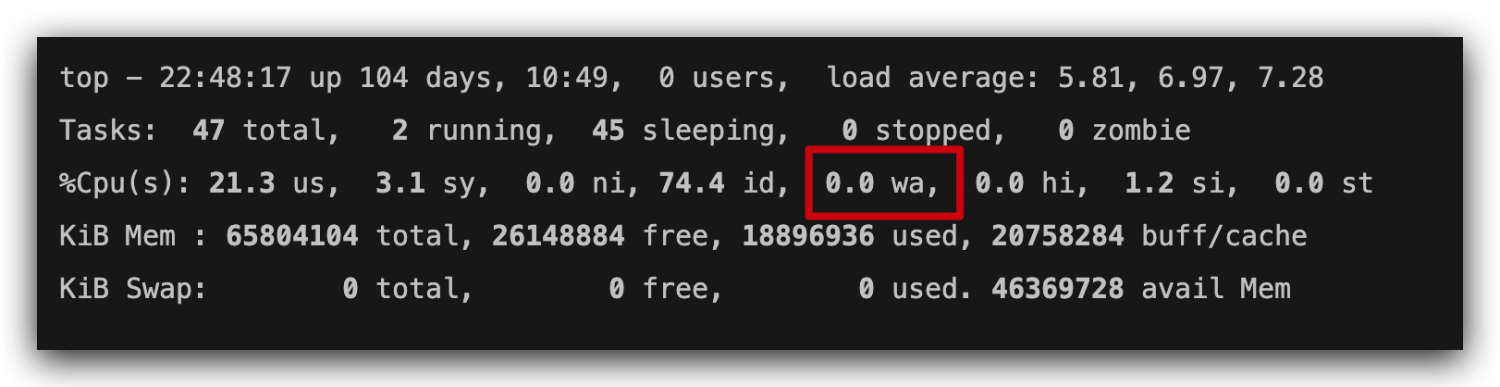
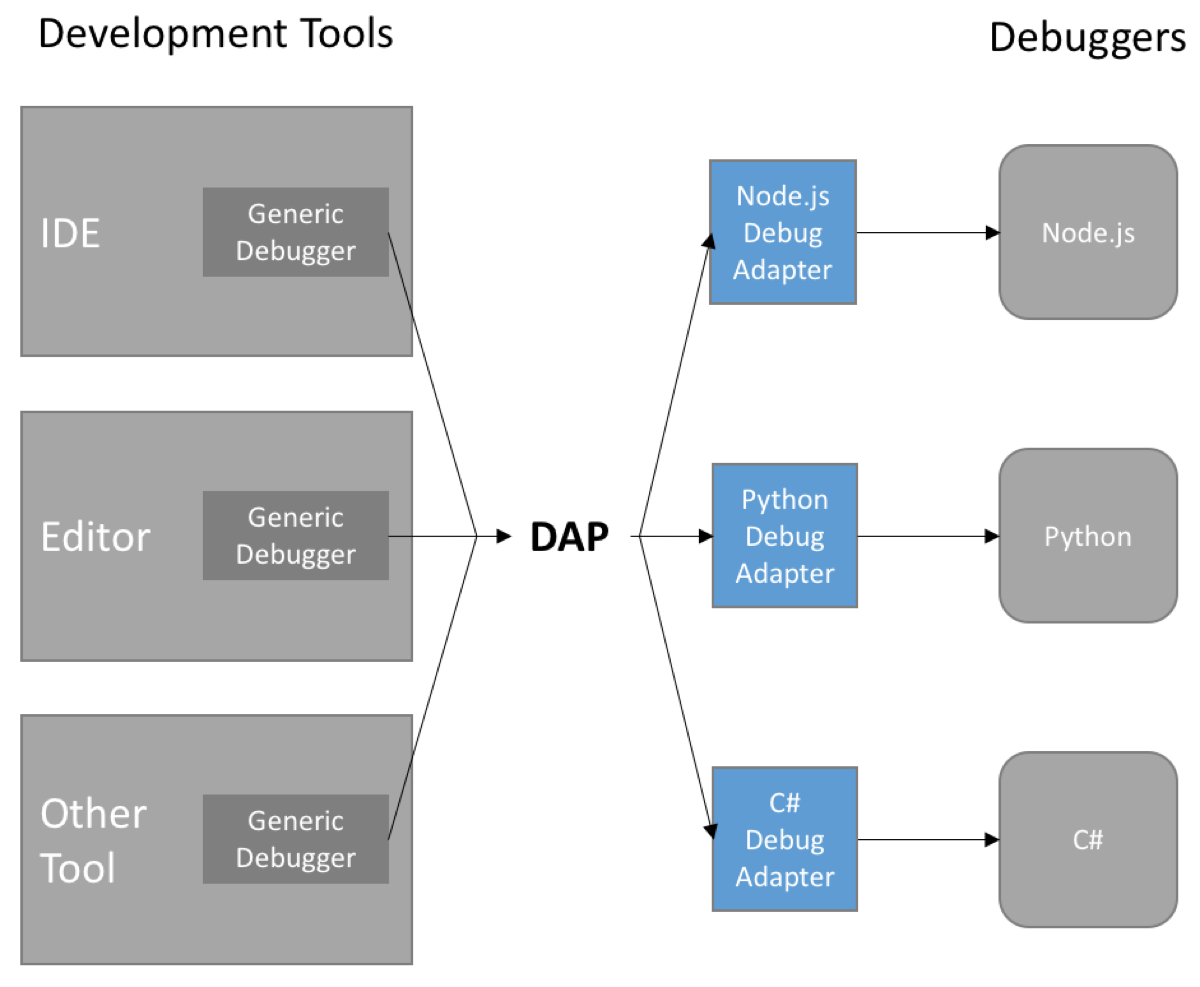
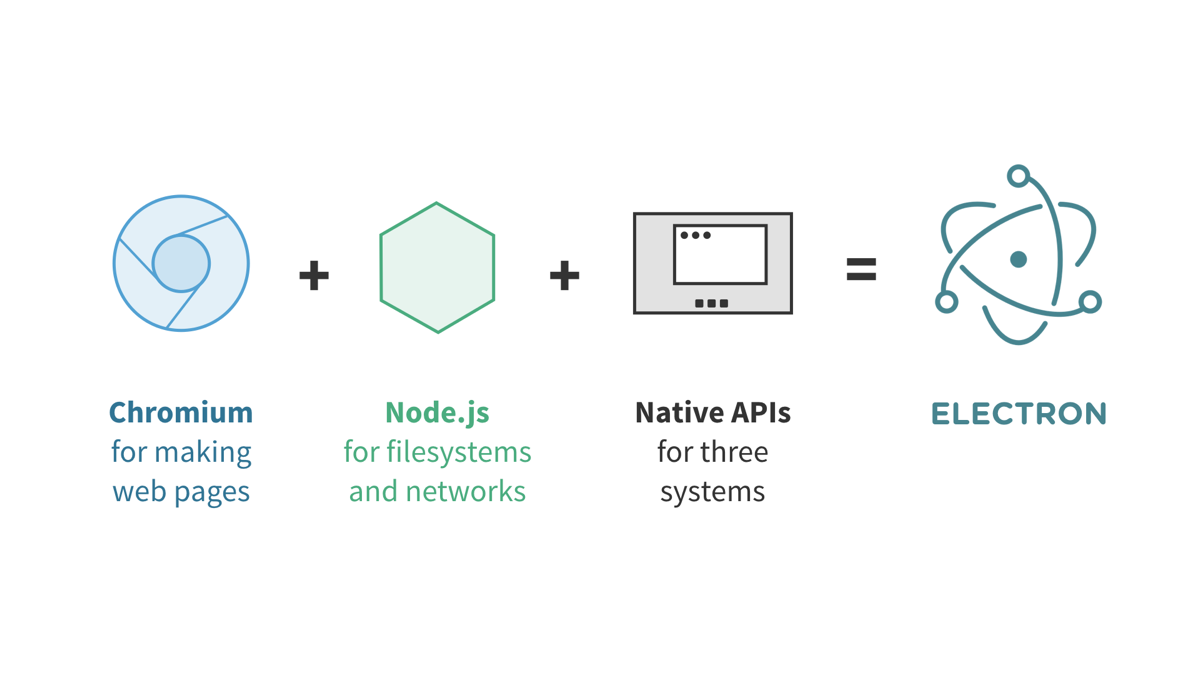
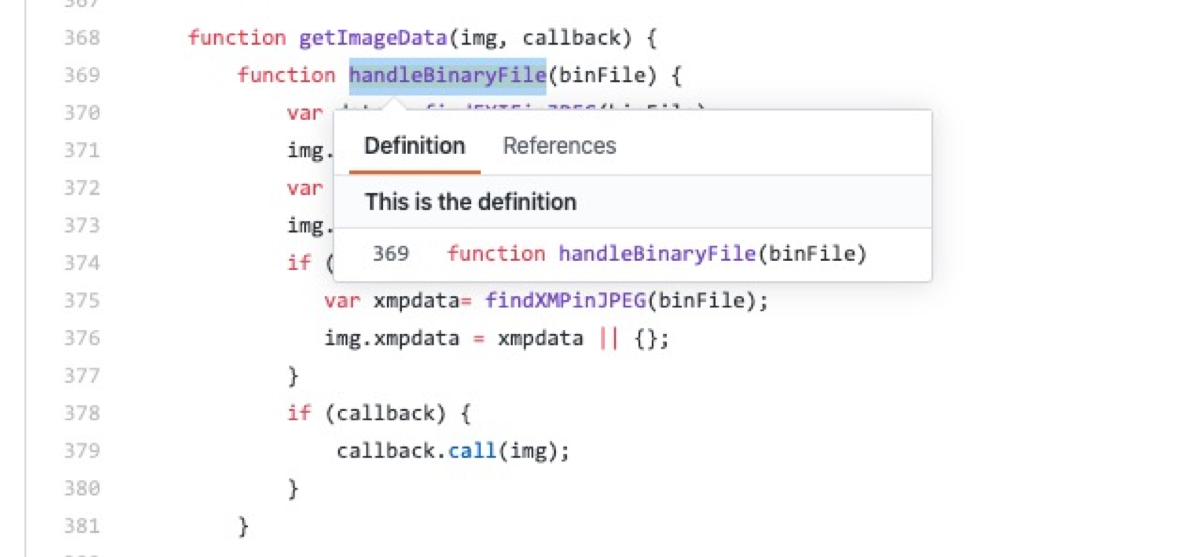
root x 0 0 root /root /bin/bash daemon x 1 1 daemon /usr/sbin /usr/sbin/nologin bin x 2 2 bin /bin /usr/sbin/nologin sys x 3 3 sys /dev /usr/sbin/nologin sync x 4 65534 sync /bin /bin/sync games x 5 60 games /usr/games /usr/sbin/nologin man x 6 12 man /var/cache/man /usr/sbin/nologin lp x 7 7 lp /var/spool/lpd /usr/sbin/nologin mail x 8 8 mail /var/mail /usr/sbin/nologin news x 9 9 news /var/spool/news /usr/sbin/nologin
No. R1 R2 R3 R4 R5 R6 R7 1 root x 0 0 root /root /bin/bash 2 daemon x 1 1 daemon /usr/sbin /usr/sbin/nologin 3 bin x 2 2 bin /bin /usr/sbin/nologin 4 sys x 3 3 sys /dev /usr/sbin/nologin 5 sync x 4 65534 sync /bin /bin/sync 6 games x 5 60 games /usr/games /usr/sbin/nologin 7 man x 6 12 man /var/cache/man /usr/sbin/nologin 8 lp x 7 7 lp /var/spool/lpd /usr/sbin/nologin 9 mail x 8 8 mail /var/mail /usr/sbin/nologin 10 news x 9 9 news /var/spool/news /usr/sbin/nologin
No. R1 R2 R3 R4 R5 R6 R7 1 root x 0 0 root /root /bin/bash 2 daemon x 1 1 daemon /usr/sbin /usr/sbin/nologin 3 bin x 2 2 bin /bin /usr/sbin/nologin 4 sys x 3 3 sys /dev /usr/sbin/nologin 5 sync x 4 65534 sync /bin /bin/sync 6 games x 5 60 games /usr/games /usr/sbin/nologin 7 man x 6 12 man /var/cache/man /usr/sbin/nologin 8 lp x 7 7 lp /var/spool/lpd /usr/sbin/nologin 9 mail x 8 8 mail /var/mail /usr/sbin/nologin 10 news x 9 9 news /var/spool/news /usr/sbin/nologin
7 man man /var/cache/man /usr/sbin/nologin 8 lp lp /var/spool/lpd /usr/sbin/nologin 9 mail mail /var/mail /usr/sbin/nologin 10 news news /var/spool/news /usr/sbin/nologin
1 root x 0 0 root /root /bin/bash 2 daemon x 1 1 daemon /usr/sbin /usr/sbin/nologin 3 bin x 2 2 bin /bin /usr/sbin/nologin 4 sys x 3 3 sys /dev /usr/sbin/nologin 5 sync x 4 65534 sync /bin /bin/sync 6 games x 5 60 games /usr/games /usr/sbin/nologin 7 man x 6 12 man /var/cache/man /usr/sbin/nologin 8 lp x 7 7 lp /var/spool/lpd /usr/sbin/nologin 9 mail x 8 8 mail /var/mail /usr/sbin/nologin 10 news x 9 9 news /var/spool/news /usr/sbin/nologin total 8 items with nologin