This is a draft of the next edition of the standard.
This page is based on the current working draft published at http://wiki.ecmascript.org/doku.php?id=harmony:specification_drafts.
The program used to convert that Word doc to HTML is a custom-piled heap of hacks. It may have stripped out or garbled some of
the formatting that makes the specification comprehensible. You can help improve the program here.
For copyright information, see Ecma International’s legal disclaimer in the document itself.
ECMA-262
6th Edition / Draft January 20, 2014
Draft
ECMAScript Language Specification
Draft
Report Errors and Issues at: https://bugs.ecmascript.org
This Ecma Standard is based on several originating technologies, the most well known being JavaScript (Netscape) and JScript
(Microsoft). The language was invented by Brendan Eich at Netscape and first appeared in that company’s Navigator 2.0
browser. It has appeared in all subsequent browsers from Netscape and in all browsers from Microsoft starting with Internet
Explorer 3.0.
The development of this Standard started in November 1996. The first edition of this Ecma Standard was adopted by the Ecma
General Assembly of June 1997.
That Ecma Standard was submitted to ISO/IEC JTC 1 for adoption under the fast-track procedure, and approved as international
standard ISO/IEC 16262, in April 1998. The Ecma General Assembly of June 1998 approved the second edition of ECMA-262 to keep it
fully aligned with ISO/IEC 16262. Changes between the first and the second edition are editorial in nature.
The third edition of the Standard introduced powerful regular expressions, better string handling, new control statements,
try/catch exception handling, tighter definition of errors, formatting for numeric output and minor changes in anticipation of
forthcoming internationalisation facilities and future language growth. The third edition of the ECMAScript standard was adopted
by the Ecma General Assembly of December 1999 and published as ISO/IEC 16262:2002 in June 2002.
Since publication of the third edition, ECMAScript has achieved massive adoption in conjunction with the World Wide Web where
it has become the programming language that is supported by essentially all web browsers. Significant work was done to develop a
fourth edition of ECMAScript. Although that work was not completed and not published as the fourth edition of ECMAScript, it
informs continuing evolution of the language. The fifth edition of ECMAScript (published as ECMA-262 5th edition)
codifies de facto interpretations of the language specification that have become common among browser implementations and adds
support for new features that have emerged since the publication of the third edition. Such features include accessor
properties, reflective creation and inspection of objects, program control of property attributes, additional array manipulation
functions, support for the JSON object encoding format, and a strict mode that provides enhanced error checking and program
security.
The edition 5.1 of the ECMAScript Standard has been fully aligned with the third edition of the international standard
ISO/IEC 16262:2011.
This present sixth edition of the Standard………
ECMAScript is a vibrant language and the evolution of the language is not complete. Significant technical enhancement will
continue with future editions of this specification.
This Ecma Standard has been adopted by the General Assembly of <month> <year>.
"DISCLAIMER
This draft document may be copied and furnished to others, and derivative works that comment on or otherwise explain it or
assist in its implementation may be prepared, copied, published, and distributed, in whole or in part, without restriction of
any kind, provided that the above copyright notice and this section are included on all such copies and derivative works.
However, this document itself may not be modified in any way, including by removing the copyright notice or references to Ecma
International, except as needed for the purpose of developing any document or deliverable produced by Ecma
International.
This disclaimer is valid only prior to final version of this document. After approval all rights on the standard are
reserved by Ecma International.
The limited permissions are granted through the standardization phase and will not be revoked by Ecma International or its
successors or assigns during this time.
This document and the information contained herein is provided on an "AS IS" basis and ECMA INTERNATIONAL DISCLAIMS ALL
WARRANTIES, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY WARRANTY THAT THE USE OF THE INFORMATION HEREIN WILL NOT
INFRINGE ANY OWNERSHIP RIGHTS OR ANY IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE."
A conforming implementation of ECMAScript must provide and support all the types, values, objects, properties, functions, and
program syntax and semantics described in this specification.
A conforming implementation of ECMAScript must interpret characters in conformance with the Unicode Standard, Version 5.1.0
or later and ISO/IEC 10646. If the adopted ISO/IEC 10646-1 subset is not otherwise specified, it is presumed to be the Unicode
set, collection 10646.
A conforming implementation of ECMAScript that provides an application programming interface that supports programs that need
to adapt to the linguistic and cultural conventions used by different human languages and countries must implement the interface
defined by the most recent edition of ECMA-402 that is compatible with this specification.
A conforming implementation of ECMAScript may provide additional types, values, objects, properties, and functions beyond
those described in this specification. In particular, a conforming implementation of ECMAScript may provide properties not
described in this specification, and values for those properties, for objects that are described in this specification.
A conforming implementation of ECMAScript may support program and regular expression syntax not described in this
specification. In particular, a conforming implementation of ECMAScript may support program syntax that makes use of the
“future reserved words” listed in subclause 11.6.2.2 of this
specification.
The following referenced documents are indispensable for the application of this document. For dated references, only the
edition cited applies. For undated references, the latest edition of the referenced document (including any amendments)
applies.
ISO/IEC 10646:2003: Information Technology – Universal Multiple-Octet Coded Character Set
(UCS) plus Amendment 1:2005, Amendment 2:2006, Amendment 3:2008, and Amendment 4:2008, plus additional amendments and
corrigenda, or successor
The Unicode Standard, Version 5.0, as amended by Unicode 5.1.0, or successor
Unicode Standard Annex #15, Unicode Normalization Forms, version Unicode 5.1.0, or
successor
Unicode Standard Annex #31, Unicode Identifiers and Pattern Syntax, version Unicode 5.1.0, or
successor.
This section contains a non-normative overview of the ECMAScript language.
ECMAScript is an object-oriented programming language for performing computations and manipulating computational objects
within a host environment. ECMAScript as defined here is not intended to be computationally self-sufficient; indeed, there are
no provisions in this specification for input of external data or output of computed results. Instead, it is expected that the
computational environment of an ECMAScript program will provide not only the objects and other facilities described in this
specification but also certain environment-specific objects, whose description and behaviour are beyond the scope of this
specification except to indicate that they may provide certain properties that can be accessed and certain functions that can
be called from an ECMAScript program.
A scripting language is a programming language that is used to manipulate, customise, and automate the
facilities of an existing system. In such systems, useful functionality is already available through a user interface, and the
scripting language is a mechanism for exposing that functionality to program control. In this way, the existing system is said
to provide a host environment of objects and facilities, which completes the capabilities of the scripting language. A
scripting language is intended for use by both professional and non-professional programmers. ECMAScript was originally
designed to be used as a scripting language, but has become widely used as a general purpose programming language.
ECMAScript was originally designed to be a Web scripting language, providing a mechanism to enliven Web pages
in browsers and to perform server computation as part of a Web-based client-server architecture. ECMAScript is now used both
as a general propose programming language and to provide core scripting capabilities for a variety of host environments.
Therefore the core language is specified in this document apart from any particular host environment.
Some of the facilities of ECMAScript are similar to those used in other programming languages; in particular C,
Java™, Self, and Scheme as described in:
ISO/IEC 9899:1996, Programming Languages – C.
Gosling, James, Bill Joy and Guy Steele. The Java™ Language
Specification. Addison Wesley Publishing Co., 1996.
Ungar, David, and Smith, Randall B. Self: The Power of Simplicity.
OOPSLA '87 Conference Proceedings, pp. 227–241, Orlando, FL, October 1987.
IEEE Standard for the Scheme Programming Language. IEEE Std
1178-1990.
A web browser provides an ECMAScript host environment for client-side computation including, for instance, objects that
represent windows, menus, pop-ups, dialog boxes, text areas, anchors, frames, history, cookies, and input/output. Further, the
host environment provides a means to attach scripting code to events such as change of focus, page and image loading,
unloading, error and abort, selection, form submission, and mouse actions. Scripting code appears within the HTML and the
displayed page is a combination of user interface elements and fixed and computed text and images. The scripting code is
reactive to user interaction and there is no need for a main program.
A web server provides a different host environment for server-side computation including objects representing requests,
clients, and files; and mechanisms to lock and share data. By using browser-side and server-side scripting together, it is
possible to distribute computation between the client and server while providing a customised user interface for a Web-based
application.
Each Web browser and server that supports ECMAScript supplies its own host environment, completing the ECMAScript execution
environment.
The following is an informal overview of ECMAScript—not all parts of the language are described. This overview is
not part of the standard proper.
ECMAScript is object-based: basic language and host facilities are provided by objects, and an ECMAScript program is a
cluster of communicating objects. In ECMAScript, an object is a collection of properties each
with zero or more attributes that determine how each property can be used—for example, when the Writable
attribute for a property is set to false, any attempt by executed ECMAScript code to change the value of the property
fails. Properties are containers that hold other objects, primitive values, or functions. A
primitive value is a member of one of the following built-in types: Undefined, Null, Boolean,
Number, Symbol and String; an object is a member of the remaining built-in type Object; and a
function is a callable object. A function that is associated with an object via a property is a method.
ECMAScript defines a collection of built-in objects that round out the definition of ECMAScript entities.
These built-in objects include the global object, the Object object, the Function object, the Array
object, the String object, the Boolean object, the Number object, the Math object, the
Date object, the RegExp object, the JSON object, and the Error objects Error, EvalError,
RangeError, ReferenceError, SyntaxError, TypeError and URIError.
ECMAScript also defines a set of built-in operators. ECMAScript operators include various unary operations,
multiplicative operators, additive operators, bitwise shift operators, relational operators, equality operators, binary
bitwise operators, binary logical operators, assignment operators, and the comma operator.
ECMAScript syntax intentionally resembles Java syntax. ECMAScript syntax is relaxed to enable it to serve as an
easy-to-use scripting language. For example, a variable is not required to have its type declared nor are types associated
with properties, and defined functions are not required to have their declarations appear textually before calls to
them.
ECMAScript does not use classes such as those in C++, Smalltalk, or Java. Instead objects may be created in various ways
including via a literal notation or via constructors which create objects and then execute code that
initialises all or part of them by assigning initial values to their properties. Each constructor is a function that has a
property named “prototype” that is used to implement prototype-based inheritance and
shared properties. Objects are created by using constructors in new expressions; for example, new
Date(2009,11) creates a new Date object. Invoking a constructor without using new has consequences that depend
on the constructor. For example, Date() produces a string representation of the current date and time rather
than an object.
Every object created by a constructor has an implicit reference (called the object’s prototype) to the value
of its constructor’s “prototype” property. Furthermore, a prototype may have a non-null
implicit reference to its prototype, and so on; this is called the prototype chain. When a reference is made to a
property in an object, that reference is to the property of that name in the first object in the prototype chain that
contains a property of that name. In other words, first the object mentioned directly is examined for such a property; if
that object contains the named property, that is the property to which the reference refers; if that object does not contain
the named property, the prototype for that object is examined next; and so on.
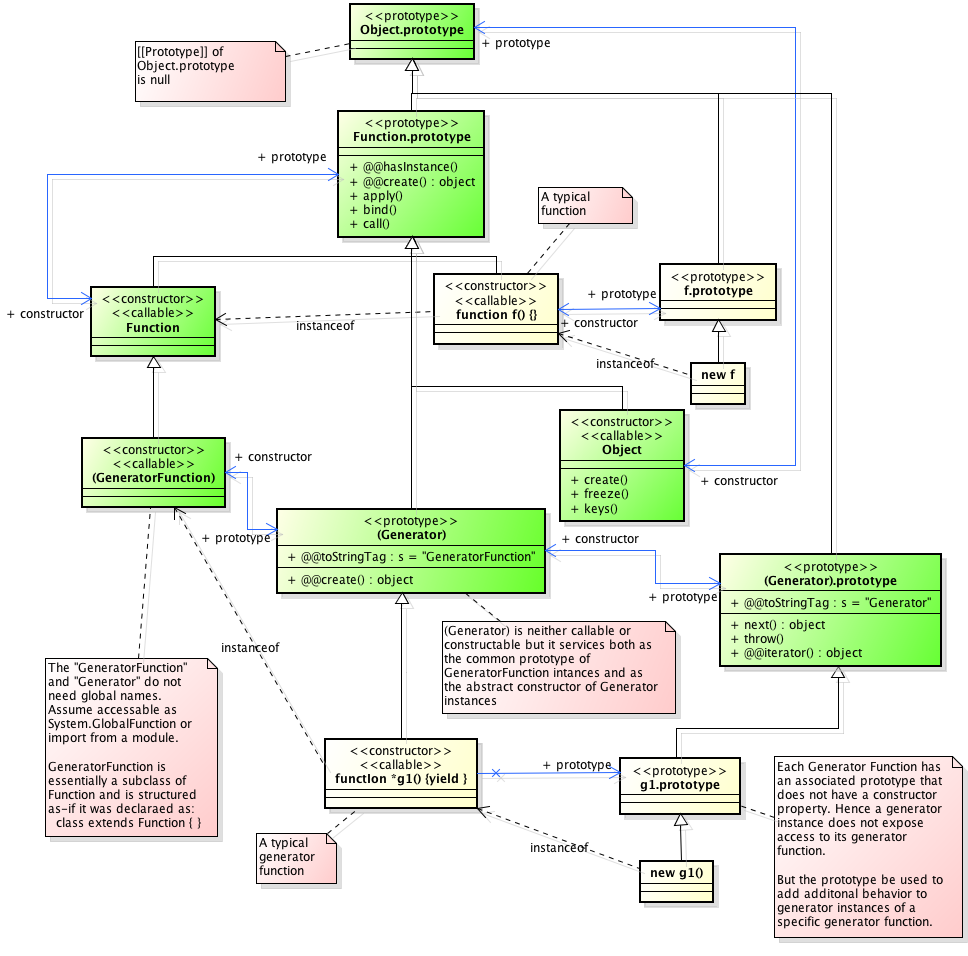
Figure 1 — Object/Prototype Relationships
In a class-based object-oriented language, in general, state is carried by instances, methods are carried by classes, and
inheritance is only of structure and behaviour. In ECMAScript, the state and methods are carried by objects, while
structure, behaviour, and state are all inherited.
All objects that do not directly contain a particular property that their prototype contains share that property and its
value. Figure 1 illustrates this:
CF is a constructor (and also an object). Five objects have been created by using new expressions:
cf1, cf2, cf3, cf4, and cf5. Each
of these objects contains properties named q1 and q2. The dashed lines represent the implicit prototype relationship; so, for example,
cf3’s prototype is CFp. The constructor, CF, has two properties itself,
named P1 and P2, which are not
visible to CFp, cf1, cf2, cf3,
cf4, or cf5. The property named CFP1 in
CFp is shared by cf1, cf2, cf3,
cf4, and cf5 (but not by CF), as are any properties found in
CFp’s implicit prototype chain that are not named q1,
q2, or CFP1. Notice that there is no
implicit prototype link between CF and CFp.
Unlike class-based object languages, properties can be added to objects dynamically by assigning values to them. That is,
constructors are not required to name or assign values to all or any of the constructed object’s properties. In the
above diagram, one could add a new shared property for cf1, cf2, cf3,
cf4, and cf5 by assigning a new value to the property in CFp.
The ECMAScript Language recognises the possibility that some users of the language may wish to restrict their usage of
some features available in the language. They might do so in the interests of security, to avoid what they consider to be
error-prone features, to get enhanced error checking, or for other reasons of their choosing. In support of this
possibility, ECMAScript defines a strict variant of the language. The strict variant of the language excludes some specific
syntactic and semantic features of the regular ECMAScript language and modifies the detailed semantics of some features. The
strict variant also specifies additional error conditions that must be reported by throwing error exceptions in situations
that are not specified as errors by the non-strict form of the language.
The strict variant of ECMAScript is commonly referred to as the strict mode of the language. Strict mode selection
and use of the strict mode syntax and semantics of ECMAScript is explicitly made at the level of individual ECMAScript code
units. Because strict mode is selected at the level of a syntactic code unit, strict mode only imposes restrictions that
have local effect within such a code unit. Strict mode does not restrict or modify any aspect of the ECMAScript semantics
that must operate consistently across multiple code units. A complete ECMAScript program may be composed for both strict
mode and non-strict mode ECMAScript code units. In this case, strict mode only applies when actually executing code that is
defined within a strict mode code unit.
In order to conform to this specification, an ECMAScript implementation must implement both the full unrestricted
ECMAScript language and the strict mode variant of the ECMAScript language as defined by this specification. In addition, an
implementation must support the combination of unrestricted and strict mode code units
into a single composite program.
object that provides shared properties for other objects
NOTE When a constructor creates an object, that object implicitly references the
constructor’s “prototype” property for the purpose of resolving property references. The
constructor’s “prototype” property can be referenced by the program expression constructor.prototype, and properties added to an object’s
prototype are shared, through inheritance, by all objects sharing the prototype. Alternatively, a new object may be
created with an explicitly specified prototype by using the Object.create
built-in function.
object supplied by an ECMAScript implementation, independent of the host environment, that is present at the start of the
execution of an ECMAScript program
NOTE Standard built-in objects are defined in this specification, and an ECMAScript
implementation may specify and define others. A built-in constructor is a built-in object that is also a
constructor.
member of the Object type that is an instance of the standard built-in Boolean constructor
NOTE A Boolean object is created by using the Boolean constructor in a
new expression, supplying a Boolean value as an argument. The resulting object has an internal slot whose value is the Boolean value. A Boolean
object can be coerced to a Boolean value.
primitive value that is a finite ordered sequence of zero or more 16-bit unsigned integer
NOTE A String value is a member of the String type. Each integer value in the sequence usually
represents a single 16-bit unit of UTF-16 text. However, ECMAScript does not place any restrictions or requirements on the
values except that they must be 16-bit unsigned integers.
member of the Object type that is an instance of the standard built-in String constructor
NOTE A String object is created by using the String constructor in a
new expression, supplying a String value as an argument. The resulting object has an internal slot whose value is the String value. A String object
can be coerced to a String value by calling the String constructor as a function (21.1.1.1).
member of the Object type that is an instance of the standard built-in Number constructor
NOTE A Number object is created by using the Number constructor in a
new expression, supplying a Number value as an argument. The resulting object has an internal slot whose value is the Number value. A Number object
can be coerced to a Number value by calling the Number constructor as a function (20.1.1.1).
member of the Object type that may be invoked as a subroutine
NOTE In addition to its properties, a function contains executable code and state that
determine how it behaves when invoked. A function’s code may or may not be written in ECMAScript.
NOTE Examples of built-in functions include parseInt and Math.exp. An implementation may provide implementation-dependent built-in functions that
are not described in this specification.
association between a key and a value that is a part of an object. The key be either a String value or a Symbol
value.
NOTE Depending upon the form of the property the value may be represented either directly as a
data value (a primitive value, an object, or a function object) or indirectly by a pair of accessor functions.
NOTE Standard built-in methods are defined in this specification, and an ECMAScript
implementation may specify and provide other additional built-in methods.
The remainder of this specification is organized as follows:
Clause 5 defines the notational conventions used throughout the specification.
Clauses 6-9 define the execution environment within which ECMAScript programs operate.
Clauses 10-16 define the actual ECMAScript programming language includings its syntactic encoding and the execution
semantics of all language features.
Clauses 17-26 define the ECMAScript standard library. It includes the definitions of all of the standard objects that are
available for use by ECMAScript programs as they execute.
A context-free grammar consists of a number of productions. Each production has an abstract symbol called a
nonterminal as its left-hand side, and a sequence of zero or more nonterminal and terminal symbols as
its right-hand side. For each grammar, the terminal symbols are drawn from a specified alphabet.
A chain production is a production that has exactly one nonterminal symbol on its right-hand side along with zero
or more terminal symbols.
Starting from a sentence consisting of a single distinguished nonterminal, called the goal symbol, a given
context-free grammar specifies a language, namely, the (perhaps infinite) set of possible sequences of terminal
symbols that can result from repeatedly replacing any nonterminal in the sequence with a right-hand side of a production for
which the nonterminal is the left-hand side.
A lexical grammar for ECMAScript is given in clause 11.
This grammar has as its terminal symbols characters (Unicode code units) that conform to the rules for SourceCharacter defined in clause 10.1. It defines a
set of productions, starting from the goal symbol InputElementDiv or InputElementRegExp, that describe how sequences of such characters are translated into a sequence of input
elements.
Input elements other than white space and comments form the terminal symbols for the syntactic grammar for ECMAScript and
are called ECMAScript tokens. These tokens are the reserved words, identifiers, literals, and punctuators of the
ECMAScript language. Moreover, line terminators, although not considered to be tokens, also become part of the stream of
input elements and guide the process of automatic semicolon insertion (11.9). Simple white space and single-line comments are discarded and do not
appear in the stream of input elements for the syntactic grammar. A MultiLineComment (that is, a
comment of the form “/*…*/” regardless of whether it spans more than one line) is likewise simply discarded if it contains
no line terminator; but if a MultiLineComment contains one or more line terminators, then it is
replaced by a single line terminator, which becomes part of the stream of input elements for the syntactic grammar.
A RegExp grammar for ECMAScript is given in 21.2.1. This grammar also has as its
terminal symbols the characters as defined by SourceCharacter. It defines a set of productions,
starting from the goal symbol Pattern, that describe how sequences of characters are translated into
regular expression patterns.
Productions of the lexical and RegExp grammars are distinguished by having two colons “::” as
separating punctuation. The lexical and RegExp grammars share some productions.
Another grammar is used for translating Strings into numeric values. This grammar is similar to the part of the lexical
grammar having to do with numeric literals and has as its terminal symbols SourceCharacter. This
grammar appears in 7.1.3.1.
Productions of the numeric string grammar are distinguished by having three colons “:::” as
punctuation.
The syntactic grammar for ECMAScript is given in clauses 11, 12, 13 and 14. This grammar has ECMAScript tokens
defined by the lexical grammar as its terminal symbols (5.1.2). It defines a
set of productions, starting from the goal symbol Script, that describe how sequences of tokens can
form syntactically correct independent components of an ECMAScript programs.
When a stream of characters is to be parsed as an ECMAScript script, it is first converted to a stream of input elements
by repeated application of the lexical grammar; this stream of input elements is then parsed by a single application of the
syntactic grammar. The script is syntactically in error if the tokens in the stream of input elements cannot be parsed as a
single instance of the goal nonterminal Script, with no tokens left over.
Productions of the syntactic grammar are distinguished by having just one colon “:” as
punctuation.
The syntactic grammar as presented in clauses 12, 13, 14 and 15 is actually not a complete account of which token
sequences are accepted as correct ECMAScript scripts. Certain additional token sequences are also accepted, namely, those
that would be described by the grammar if only semicolons were added to the sequence in certain places (such as before line
terminator characters). Furthermore, certain token sequences that are described by the grammar are not considered acceptable
if a terminator character appears in certain “awkward” places.
In certain cases in order to avoid ambiguities the syntactic grammar uses generalised productions that permit token
sequences that are not valid ECMAScript scripts. For example, this technique is used in with object literals and object
destructuring patterns. In such cases a more restrictive supplemental grammar is provided that further restricts the
acceptable token sequences. In certain contexts, when explicitly specific, the input elements corresponding to such a
production are parsed again using a goal symbol of a supplemental grammar. The script is syntactically in error if the
tokens in the stream of input elements cannot be parsed as a single instance of the supplemental goal symbol, with no tokens
left over.
Terminal symbols of the lexical, RegExp, and numeric string grammars, and some of the terminal symbols of the other
grammars, are shown in fixed width font, both in the productions of the grammars and throughout this
specification whenever the text directly refers to such a terminal symbol. These are to appear in a script either exactly as
written. All terminal symbol characters specified in this way are to be understood as the appropriate Unicode code points
from the Basic Latin range, as opposed to any similar-looking characters from other Unicode ranges.
Nonterminal symbols are shown in italic type. The definition of a nonterminal (also called a
“production”) is introduced by the name of the nonterminal being defined followed by one or more colons. (The
number of colons indicates to which grammar the production belongs.) One or more alternative right-hand sides for the
nonterminal then follow on succeeding lines. For example, the syntactic definition:
WhileStatement:
while(Expression)Statement
states that the nonterminal WhileStatement represents the token while, followed by a
left parenthesis token, followed by an Expression, followed by a right parenthesis token, followed
by a Statement. The occurrences of Expression and Statement are themselves nonterminals. As another example, the syntactic definition:
ArgumentList:
AssignmentExpression
ArgumentList,AssignmentExpression
states that an ArgumentList may represent either a single AssignmentExpression or an ArgumentList, followed by a comma, followed by an AssignmentExpression. This definition of ArgumentList is recursive, that is, it is
defined in terms of itself. The result is that an ArgumentList may contain any positive number of
arguments, separated by commas, where each argument expression is an AssignmentExpression. Such
recursive definitions of nonterminals are common.
The subscripted suffix “opt”, which may appear after a terminal or nonterminal, indicates an
optional symbol. The alternative containing the optional symbol actually specifies two right-hand sides, one that omits the
optional element and one that includes it. This means that:
so, in this example, the nonterminal IterationStatement actually has four alternative right-hand
sides.
A production may be parameterised by a subscripted annotation of the form “[parameters]”, which
may appear as a suffix to the nonterminal symbol defined by the production. “parameters” may be
either a single name or a comma separated list of names. A parameterised production is a shorthand for a set of productions
defining all combinations of the parameter names appended to the parameterised nonterminal symbol. This means that:
StatementList[Return]:
ReturnStatement
ExpressionStatement
is a convenient abbreviation for:
StatementList:
ReturnStatement
ExpressionStatement
StatementListReturn:
ReturnStatement
ExpressionStatement
and that:
StatementList[Return, In]:
ReturnStatement
ExpressionStatement
is abbreviation for:
StatementList:
ReturnStatement
ExpressionStatement
StatementListReturn:
ReturnStatement
ExpressionStatement
StatementListIn:
ReturnStatement
ExpressionStatement
StatementListReturnIn:
ReturnStatement
ExpressionStatement
References to nonterminals on the right hand side of a production can also be parameterised. For example:
StatementList:
ReturnStatement
ExpressionStatement[In]
is equivalent to saying:
StatementList:
ReturnStatement
ExpressionStatementIn
A nonterminal reference may have both a parameter list and an “opt” suffix. For example:
VariableDeclaration:
BindingIdentifierInitialiser[In]opt
is an abbreviation for:
VariableDeclaration:
BindingIdentifier
BindingIdentifierInitialiserIn
Prefixing a parameter name with “?”on a right hand side nonterminal reference makes that
parameter value dependent upon the occurrence of the parameter name on the reference to the current production’s left
hand side symbol. For example:
VariableDeclaration[In]:
BindingIdentifierInitialiser[?In]
is an abbreviation for:
VariableDeclaration:
BindingIdentifierInitialiser
VariableDeclarationIn:
BindingIdentifierInitialiserIn
If a right hand side alternative is prefixed with “[+parameter]” that alternative is only available if the
named parameter was used in referencing the production’s nonterminal symbol. If a right hand side alternative is
prefixed with “[~parameter]” that alternative is only available if the named parameter was not used in
referencing the production’s nonterminal symbol. This means that:
StatementList[Return]:
[+Return]ReturnStatement
ExpressionStatement
is an abbreviation for:
StatementList:
ExpressionStatement
StatementListReturn:
ReturnStatement
ExpressionStatement
and that
StatementList[Return]:
[~Return]ReturnStatement
ExpressionStatement
is an abbreviation for:
StatementList:
ReturnStatement
ExpressionStatement
StatementListReturn:
ExpressionStatement
When the words “one of” follow the colon(s) in a grammar definition, they signify that each of the
terminal symbols on the following line or lines is an alternative definition. For example, the lexical grammar for
ECMAScript contains the production:
NonZeroDigit::one of
123456789
which is merely a convenient abbreviation for:
NonZeroDigit::
1
2
3
4
5
6
7
8
9
If the phrase “[empty]” appears as the right-hand side of a production, it indicates that the production's
right-hand side contains no terminals or nonterminals.
If the phrase “[lookahead ∉ set]” appears in the right-hand side of a production, it
indicates that the production may not be used if the immediately following input token is a member of the given
set. The set can be written as a list of terminals enclosed in curly braces. For convenience, the set
can also be written as a nonterminal, in which case it represents the set of all terminals to which that nonterminal could
expand. For example, given the definitions
DecimalDigit::one of
0123456789
DecimalDigits::
DecimalDigit
DecimalDigitsDecimalDigit
the definition
LookaheadExample::
n[lookahead ∉ {1, 3, 5, 7, 9}]DecimalDigits
DecimalDigit[lookahead ∉ DecimalDigit]
matches either the letter n followed by one or more decimal digits the first of which is even, or a decimal
digit not followed by another decimal digit.
If the phrase “[no LineTerminator here]” appears in the right-hand side of a
production of the syntactic grammar, it indicates that the production is a restricted production: it may not be used
if a LineTerminator occurs in the input stream at the indicated position. For example, the
production:
ThrowStatement:
throw[no LineTerminator here]Expression;
indicates that the production may not be used if a LineTerminator occurs in the script between
the throw token and the Expression.
Unless the presence of a LineTerminator is forbidden by a restricted production, any number of
occurrences of LineTerminator may appear between any two consecutive tokens in the stream of input
elements without affecting the syntactic acceptability of the script.
The lexical grammar has multiple goal symbols and the appropriate goal symbol to use depends upon the syntactic grammar
context. If a phrase of the form “[Lexical goal LexicalGoalSymbol]” appears on the right-hand-side of a
syntactic production then the next token must be lexically recognised using the indicated goal symbol. In the absence of
such a phrase the default lexical goal symbol is used.
When an alternative in a production of the lexical grammar or the numeric string grammar appears to be a multi-character
token, it represents the sequence of characters that would make up such a token.
The right-hand side of a production may specify that certain expansions are not permitted by using the phrase
“but not” and then indicating the expansions to be excluded. For example, the production:
Identifier::
IdentifierNamebut notReservedWord
means that the nonterminal Identifier may be replaced by any sequence of characters that could
replace IdentifierName provided that the same sequence of characters could not replace ReservedWord.
Finally, a few nonterminal symbols are described by a descriptive phrase in sans-serif type in cases where it would be
impractical to list all the alternatives:
The specification often uses a numbered list to specify steps in an algorithm. These algorithms are used to precisely
specify the required semantics of ECMAScript language constructs. The algorithms are not intended to imply the use of any
specific implementation technique. In practice, there may be more efficient algorithms available to implement a given
feature.
Algorithms may be explicitly parameterised, in which case the names and usage of the parameters must be provided as part of
the algorithm’s definition. In order to facilitate their use in multiple parts of this specification, some algorithms,
called abstractoperations, are named and written in parameterised functional form so that they may be
referenced by name from within other algorithms.
Algorithms may be associated with productions of one of the ECMAScript grammars. A production that has multiple
alternative definitions will typically have a distinct algorithm for each alternative. When an algorithm is associated with a
grammar production, it may reference the terminal and nonterminal symbols of the production alternative as if they were
parameters of the algorithm. When used in this manner, nonterminal symbols refer to the actual alternative definition that is
matched when parsing the script souce code.
When an algorithm is associated with a production alternative, the alternative is typically shown without any “[
]” grammar annotations. Such annotations should only affect the syntactic recognition of the alternative and have no
effect on the associated semantics for the alternative.
Unless explicitly specified otherwise, all chain productions have an implicit
associated definition for every algorithm that is might be applied to that production’s left-hand side nonterminal. The
implicit definition simply reapplies the same algorithm name with the same parameters, if any, to the chain production’s sole right-hand side nonterminal and then result. For example,
assume there is a production
Block:
{StatementList}
but there is no evalution algorithm that is explicitly specified for that
production. If in some algorithm there is a statement of the form: “Return
the result of evaluating Block” it is implicit that the algorithm has an evalution algorithm of the form:
Runtime Semantics: Evaluation
Block:{StatementList}
Return the result of evaluating StatementList.
For clarity of expression, algorithm steps may be subdivided into sequential substeps. Substeps are indented and may
themselves be further divided into indented substeps. Outline numbering conventions are used to identify substeps with the
first level of substeps labelled with lower case alphabetic characters and the second level of substeps labelled with lower
case roman numerals. If more than three levels are required these rules repeat with the fourth level using numeric labels.
For example:
Top-level step
Substep.
Substep.
Subsubstep.
Subsubsubstep
Subsubsubsubstep
Subsubsubsubsubstep
A step or substep may be written as an “if” predicate that conditions its substeps. In this case, the substeps
are only applied if the predicate is true. If a step or substep begins with the word “else”, it is a predicate
that is the negation of the preceding “if” predicate step at the same level.
A step may specify the iterative application of its substeps.
A step may assert an invariant condition of its algorithm. Such assertions are used to make explicit algorithmic
invariants that would otherwise be implicit. Such assertions add no additional semantic requirements and hence need not be
checked by an implementation. They are used simply to clarify algorithms.
Mathematical operations such as addition, subtraction, negation, multiplication, division, and the mathematical functions
defined later in this clause should always be understood as computing exact mathematical results on mathematical real numbers,
which do not include infinities and do not include a negative zero that is distinguished from positive zero. Algorithms in
this standard that model floating-point arithmetic include explicit steps, where necessary, to handle infinities and signed
zero and to perform rounding. If a mathematical operation or function is applied to a floating-point number, it should be
understood as being applied to the exact mathematical value represented by that floating-point number; such a floating-point
number must be finite, and if it is +0 or −0 then the
corresponding mathematical value is simply 0.
The mathematical function abs(x) produces the absolute value of
x, which is −x if x is negative (less
than zero) and otherwise is x itself.
The mathematical function sign(x) produces 1 if x is positive and −1 if x is negative. The sign function is not used in this standard for cases when x
is zero.
The mathematical function min(x1,x2, ..., xn) produces the mathematically
smallest of x1 through xn.
The notation “x modulo y” (y must be
finite and nonzero) computes a value k of the same sign as y (or zero) such that abs(k) < abs(y) and x−k = q×y for some integer q.
The mathematical function floor(x) produces the largest integer
(closest to positive infinity) that is not larger than x.
Context-free grammars are not sufficiently powerful to express all the rules that define whether a stream of input elements
make up a valid ECMAScript script that may be evaluated. In some situations additional rules are needed that may be expressed
using either ECMAScript algorithm conventions or prose requirements. Such rules are always associated with a production of a
grammar and are called the static semantics of the production.
Static Semantic Rules have names and typically are defined using an algorithm. Named Static Semantic Rules are associated
with grammar productions and a production that has multiple alternative definitions will typically have for each alternative a
distinct algorithm for each applicable named static semantic rule.
Unless otherwise specified every grammar production alternative in this specification implicitly has a definition for a
static semantic rule named Contains which takes an argument named
symbol whose value is a terminal or nonterminal of the grammar that includes the associated production. The
default definition of Contains is:
For each terminal and nonterminal grammar symbol, sym, in the definition of this production do
If sym is the same grammar symbol as symbol, return true.
If sym is a nonterminal, then
Let contained be the result of Contains for sym with argument symbol.
If contained is true, return true.
Return false.
The above definition is explicitly over-ridden for specific productions.
A special kind of static semantic rule is an Early Error Rule. Early error rules define early error conditions (see clause 15.2.3) that are associate with specific grammar productions.
Evaluation of most early error rules are not explicitly invoked within the algorithms of this specification. A comforming
implementation must, prior to the first evaluation of a Script, validate all of the early error rules
of the productions used to parse that Script. If any of the early error rules are violated the Script is invalid and cannot be evaluated.
Algorithms within this specification manipulate values each of which has an associated type. The possible value types are
exactly those defined in this clause. Types are further subclassified into ECMAScript language types and specification
types.
Within this specification, the notation “Type(x)” is
used as shorthand for “the type of x” where “type” refers to the ECMAScript language and specification types defined in
this clause.
An ECMAScript language type corresponds to values that are directly manipulated by an ECMAScript programmer using the
ECMAScript language. The ECMAScript language types are Undefined, Null, Boolean, String, Symbol, Number, and Object. An
ECMAScript language value is a value that is characterized by an ECMAScript language type.
The String type is the set of all finite ordered sequences of zero or more 16-bit unsigned integer values
(“elements”). The String type is generally used to represent textual data in a running ECMAScript program, in
which case each element in the String is treated as a UTF-16 code unit value. Each element is regarded as occupying a
position within the sequence. These positions are indexed with nonnegative integers. The first element (if any) is at index
0, the next element (if any) at index 1, and so on. The length of a String is the number of elements (i.e., 16-bit values)
within it. The empty String has length zero and therefore contains no elements.
Where ECMAScript operations interpret String values, each element is interpreted as a single UTF-16 code unit. However,
ECMAScript does not place any restrictions or requirements on the sequence of code units in a String value, so they may be
ill-formed when interpreted as UTF-16 code unit sequences. Operations that do not interpret String contents treat them as
sequences of undifferentiated 16-bit unsigned integers. No operations ensure that Strings are in a normalized form. Only
operations that are explicitly specified to be language or locale sensitive produce language-sensitive results
NOTE The rationale behind this design was to keep the implementation of Strings as simple and
high-performing as possible. If ECMAScript source code is in Normalised Form C, string literals are guaranteed to also be
normalised, as long as they do not contain any Unicode escape sequences.
Some operations interpret String contents as UTF-16 encoded Unicode code points. In that case the interpretation is:
A code unit in the range 0 to 0xD7FF or in the range 0xE000 to 0xFFFF is interpreted as a code point with the same value.
A sequence of two code units, where the first code unit c1 is in the range 0xD800 to 0xDBFF and the second code unit
c2 is in the range 0xDC00 to 0xDFFF, is a surrogate pair and is interpreted as a code point with the value (c1 -
0xD800) × 0x400 + (c2 – 0xDC00) + 0x10000.
A code unit that is in the range 0xD800 to 0xDFFF, but is not part of a surrogate pair, is interpreted as a code point
with the same value.
Well-known symbols are built-in Symbol values that are explicitly referenced by algorithms of this specification. They
are typically used as the keys of properties whose values serve as extension points of a specification algorithm. Unless
otherwise specified, well-known symbols values are shared by all Code Realms (8.2).
Within this specification a well-known symbol is referred to by using a notation of the form @@name, where
“name” is one of the values listed in Table 1.
Table 1— Well-known Symbols
Specification Name
[[Description]]
Value and Purpose
@@create
"Symbol.create"
A method used to allocate an object. Called from the [[Construct]] internal method.
@@hasInstance
"Symbol.hasInstance"
A method that determines if a constructor object recognises an object as one of the constructor’s instances. Called by the semantics of the instanceof operator.
@@isConcatSpreadable
"Symbol.isConcatSpreadable"
A Boolean value that if true indicates that an object should be flatten to its array elements by Array.prototype.concat.
@@isRegExp
"Symbol.isRegExp"
A Boolean value that if true indicates that an object may be used as a regular expression.
@@iterator
"Symbol.iterator"
A method that returns the default iterator for an object. Called by the semantics of the for-of statement.
@@toPrimitive
"Symbol.toPrimitive"
A method that converts an object to a corresponding primitive value. Called by the ToPrimitive abstract operation.
@@toStringTag
"Symbol.toStringTag"
A string value that is used in the creation of the default string description of an object. Called by the built-in method Object.prototype.toString.
@@unscopables
"Symbol.unscopables"
An Array of string values that are property names that are excluded from the with environment bindings of the associated objects.
The Number type has exactly 18437736874454810627 (that is, 264−253+3) values, representing the double-precision
64-bit format IEEE 754 values as specified in the IEEE Standard for Binary Floating-Point Arithmetic, except that the 9007199254740990 (that is, 253−2) distinct “Not-a-Number” values of the IEEE Standard are represented in
ECMAScript as a single special NaN value. (Note that the NaN value is produced by the program expression
NaN.) In some implementations, external code might be able to detect a difference between various Not-a-Number
values, but such behaviour is implementation-dependent; to ECMAScript code, all NaN values are indistinguishable from each
other.
There are two other special values, called positive Infinity and negative Infinity. For brevity, these
values are also referred to for expository purposes by the symbols +∞ and −∞, respectively. (Note that these two infinite Number values are produced by the program
expressions +Infinity (or simply Infinity) and -Infinity.)
The other 18437736874454810624 (that is, 264−253) values are called the finite numbers. Half of these are
positive numbers and half are negative numbers; for every finite positive Number value there is a corresponding negative
value having the same magnitude.
Note that there is both a positive zero and a negative zero. For brevity, these values are also referred to
for expository purposes by the symbols +0 and −0, respectively.
(Note that these two different zero Number values are produced by the program expressions +0 (or simply
0) and -0.)
The 18437736874454810622 (that is, 264−253−2) finite nonzero values are of two kinds:
18428729675200069632 (that is, 264−254) of them are normalised, having the form
s × m × 2e
where s is +1 or −1, m is a positive integer less than 253 but not less than 252, and
e is an integer ranging from −1074 to 971, inclusive.
The remaining 9007199254740990 (that is, 253−2) values are denormalised, having the form
s × m × 2e
where s is +1 or −1, m is a positive integer less than 252, and e is −1074.
Note that all the positive and negative integers whose magnitude is no greater than 253 are representable in the Number type (indeed, the integer 0 has two representations, +0 and -0).
A finite number has an odd significand if it is nonzero and the integer m used to express it (in one of
the two forms shown above) is odd. Otherwise, it has an even significand.
In this specification, the phrase “the Number value for
x” where x represents an exact nonzero real mathematical quantity (which might even be an
irrational number such as π) means a Number value chosen in the
following manner. Consider the set of all finite values of the Number type, with −0 removed
and with two additional values added to it that are not representable in the Number type, namely 21024 (which is +1 ×
253× 2971) and −21024 (which is −1 × 253× 2971).
Choose the member of this set that is closest in value to x. If two values of the set are equally close, then the
one with an even significand is chosen; for this purpose, the two extra values 21024 and −21024 are considered
to have even significands. Finally, if 21024 was chosen,
replace it with +∞; if −21024 was chosen, replace it with −∞; if +0 was chosen, replace it with −0 if and only if x is less
than zero; any other chosen value is used unchanged. The result is the Number value for x. (This procedure
corresponds exactly to the behaviour of the IEEE 754 “round to nearest” mode.)
Some ECMAScript operators deal only with integers in the range −231 through 231−1,
inclusive, or in the range 0 through 232−1, inclusive. These operators accept any value of the Number type but first convert each
such value to one of 232 integer values. See the descriptions
of the ToInt32 and ToUint32 operators in 7.1.5 and 7.1.6, respectively.
An Object is logically a collection of properties. Each property is either a data property, or an accessor
property:
A data property associates a key value with an ECMAScript language
value and a set of Boolean attributes.
An accessor property associates a key value with one or two accessor functions, and a set of Boolean
attributes. The accessor functions are used to store or retrieve an ECMAScript language value that is associated with the property.
Properties are identified using key values. A key value is either an ECMAScript String value or a Symbol value. All
String and Symbol values, including the empty string, are valid as property keys.
Property keys are used to access properties and their values. There are two kinds of access for properties: get
and set, corresponding to value retrieval and assignment, respectively. The properties accessible via get and set
access includes both own properties that are a direct part of an object and inherited properties which are
provided by another associated object via a property inheritance relationship. Inherited properties may be either own or
inherited properties of the associated object. Each own properties of an object must each have a key value that is
distinct from the key values of the other own properties of that object.
All objects are logically collections of properties, but there are multiple forms of objects that differ in their
semantics for accessing and manipulating their properties. Ordinary objects are the most common form of objects
and have the default object semantics. An exotic object is any form of object whose property semantics differ in
any way from the default semantics.
Attributes are used in this specification to define and explain the state of Object properties. A data property
associates a key value with the attributes listed in Table 2.
The value retrieved by a get access of the property.
[[Writable]]
Boolean
If false, attempts by ECMAScript code to change the property’s [[Value]] attribute using [[Set]] will not succeed.
[[Enumerable]]
Boolean
If true, the property will be enumerated by a for-in enumeration (see 13.6.4). Otherwise, the property is said to be non-enumerable.
[[Configurable]]
Boolean
If false, attempts to delete the property, change the property to be an accessor property, or change its attributes (other than [[Value]], or changing [[Writable]] to false) will fail.
An accessor property associates a key value with the attributes listed in Table 3.
Table 3 — Attributes of an Accessor Property
Attribute Name
Value Domain
Description
[[Get]]
Object or Undefined
If the value is an Object it must be a function Object. The function’s [[Call]] internal method (Table 6) is called with an empty arguments list to retrieve the property value each time a get access of the property is performed.
[[Set]]
Object or Undefined
If the value is an Object it must be a function Object. The function’s [[Call]] internal method (Table 6) is called with an arguments list containing the assigned value as its sole argument each time a set access of the property is performed. The effect of a property's [[Set]] internal method may, but is not required to, have an effect on the value returned by subsequent calls to the property's [[Get]] internal method.
[[Enumerable]]
Boolean
If true, the property is to be enumerated by a for-in enumeration (see 13.6.4). Otherwise, the property is said to be non-enumerable.
[[Configurable]]
Boolean
If false, attempts to delete the property, change the property to be a data property, or change its attributes will fail.
If the initial values of a property’s attributes are not explicitly specified by this specification, the default
value defined in Table 4 is used.
Table 4 — Default Attribute Values
Attribute Name
Default Value
[[Value]]
undefined
[[Get]]
undefined
[[Set]]
undefined
[[Writable]]
false
[[Enumerable]]
false
[[Configurable]]
false
6.1.7.2 Object Internal Methods and Internal Slots
The actual semantics of objects, in ECMAScript, are specified via algorithms called internal methods. Each
object in an ECMAScript engine is associated with a set of internal methods that defines its runtime behaviour. These
internal methods are not part of the ECMAScript language. They are defined by this specification purely for expository
purposes. However, each object within an implementation of ECMAScript must behave as specified by the internal methods
associated with it. The exact manner in which this is accomplished is determined by the implementation.
Internal method names are polymorphic. This means that different object values may perform different algorithms when a
common internal method name is invoked upon them. If, at runtime, the implementation of an algorithm attempts to use an
internal method of an object that the object does not support, a TypeError exception is thrown.
Internal slots correspond to internal state that is associated with objects and used by various ECMAScript
specification algorithms. Internal slots are not object properties and they are not inherited. Depending upon the specific
internal slot specification, such state may consist of values of any ECMAScript
language type or of specific ECMA specification type values. Unless explicitly specified otherwise, internal slots are
allocated as part of the process of creating an object and may not be dynamically added to an object. Unless specified
otherwise, the initial value of an internal slot is the value undefined. Various algorithms
within this specification create objects that have internal slots. However, the ECMAScript language provides no direct way
to associate internal slots with an object.
Internal methods and internal slots are identified within this specification using names enclosed in double square
brackets [[ ]].
Table 5 summarises the essential internal methods used by this specification that are
applicable to all objects created or manipulated by ECMAScript code. Every object must have algorithms for all of the
essential internal methods. However, all objects do not necessarily use the same algorithms for those methods.
The “Signature” column of Table 5 and other similar tables describes the invocation
pattern for each internal method. The invocation pattern always includes a parenthesised list of descriptive parameter
names. If a parameter name is the same as an ECMAScript type name then the name describes the required type of the
parameter value. If an internal method explicitly returns a value, its parameter list is followed by the symbol
“→” and the type name of the returned value. The type names used in signatures refer to the types defined
in clause 6 augmented by the following additional names. “any” means the value may be any ECMAScript language type. An internal method implicitly returns a Completion Record as described in 6.2.2. In addition to its parameters, an internal method always has
access to the object upon which it is invoked as a method.
Table 5 — Essential Internal Methods
Internal Method
Signature
Description
[[GetPrototypeOf]]
()→Object or Null
Determine the object that provides inherited properties for this object. A null value indicates that there are no inherited properties.
[[SetPrototypeOf]]
(Object or Null)→Boolean
Associate with an object another object that provides inherited properties. Passing null indicates that there are no inherited properties. Returns true indicating that the operation was completed successfully or false indicating that the operation was not successful.
[[IsExtensible]]
( )→Boolean
Determine whether it is permitted to add additional properties to an object.
[[PreventExtensions]]
( )→Boolean
Control whether new properties may be added to an object. Returns true indicating that the operation was completed successfully or false indicating that the operation was not successful.
Returns a Property Descriptor for the own property of this object whose key is propertyKey, or undefined if no such property exists.
[[HasProperty]]
(propertyKey) → Boolean
Returns a Boolean value indicating whether the object already has either an own or inherited property whose key is propertyKey.
[[Get]]
(propertyKey, Receiver) → any
Retrieve the value of an object’s property using the propertyKey parameter. If any ECMAScript code must be executed to retrieve the property value, Receiver is used as the this value when evaluating the code.
[[Set]]
(propertyKey,value, Receiver) → Boolean
Try to set the value of an object’s property indentified by propertyKey to value. If any ECMAScript code must be executed to set the property value, Receiver is used as the this value when evaluating the code. Returns true indicating that the property value was set or false indicating that it could not be set.
[[Delete]]
(propertyKey) → Boolean
Removes the own property indentified by the propertyKey parameter from the object. Return false if the property was not deleted and is still present. Return true if the property was deleted or was not present.
[[DefineOwnProperty]]
(propertyKey, PropertyDescriptor) → Boolean
Creates or alters the named own property to have the state described by a Property Descriptor. Returns true indicating that the property was successfully created/updated or false indicating that the property could not be created or updated.
[[Enumerate]]
()→Object
Returns an iterator object over the string values of the keys of the enumerable properties of the object.
[[OwnPropertyKeys]]
()→Object
Returns an Iterator object that produces all of the own property keys for the object.
Table 6 summarises additional essential internal methods that are supported by objects that may
be called as functions.
Table 6 — Additional Essential Internal Methods of Function Objects
Executes code associated with the object. Invoked via a function call expression. The arguments to the internal method are a this value and a list containing the arguments passed to the function by a call expression. Objects that implement this internal method are callable.
Creates an object. Invoked via the new operator. The arguments to the internal method are the arguments passed to the new operator. Objects that implement this internal method are called constructors. A Function object is not necessarily a constructor and such non-constructor Function objects do not have a [[Construct]] internal method.
The semantics of the essential internal method for ordinary objects and standard exotic objects are specified in clause
9. If any specified use of an exotic object's internal methods is not supported by an implementation, that usage must
throw a TypeError exception when attempted.
6.1.7.3 Invariants of the Essential Internal Methods
The Internal Methods of Objects of an ECMAScript engine must conform to the list of invariants specified below.
Ordinary ECMAScript Objects as well as all standard exotic objects in this specification maintain these invariants.
ECMAScript Proxy objects maintain these invariants by means of runtime checks on the result of traps invoked on the
[[ProxyHandler]] object.
Any implementation provided exotic objects must also maintain these invariants for those objects. Violation of these
invariants may cause ECMAScript code to have unpredictable behavior and create security issues. However, violation of
these invariants must never compromise the memory safety of an implementation.
Definitions:
The target of an internal method is the object the internal method is called upon.
A target is non-extensible if it has been observed to return false from its
[[IsExtensible]] internal method, or true from its [[PreventExtensions]] internal
method.
A non-existent property is a property that does not exist as an own property on a non-extensible target.
Any references to SameValue are according to the definition of SameValue algorithm specified in 7.2.3.
[[GetPrototypeOf]] ( )
The Type of the return value must be either Object or Null.
If target is non-extensible, and [[GetPrototypeOf]] returns a value v, then any future calls to [[GetPrototypeOf]]
should return the SameValue as v.
An object’s prototype chain must have finite length (that is, starting from any object, recursively applying
the [[GetPrototypeOf]] internal method to its result must eventually lead to the value null.
[[SetPrototypeOf]] (V)
The Type of the return value must be Boolean.
If target is non-extensible, [[SetPrototypeOf]] must return false, unless V is the SameValue as the target’s observed [[GetPrototypeOf]] value.
[[PreventExtensions]] ( )
The Type of the return value must be Boolean.
If [[PreventExtensions]] returns true, all future calls to [[IsExtensible]] must return
false and the target is now considered non-extensible.
[[GetOwnProperty]] (P)
The Type of the return value must be either Object or Undefined.
If the Type of the return value is Object, that object must be a complete property descriptor (see 6.2.4.6).
If a property is described as a data property and it may return different values over time, then either or both of
the Desc.[[Writable]] and Desc.[[Configurable]] attributes must be true even if no
mechanism to change the value is exposed via the other internal methods.
If a property P is described as a data property with Desc.[[Value]] equal to v and Desc.[[Writable]] and
Desc.[[Configurable]] are both false, then the SameValue must
be returned for the Desc.[[Value]] attribute of the property on all future calls to [[GetOwnProperty]] ( P ).
If P’s attributes other than [[Writable]] may change over time or if the property might disappear, then
P’s [[Configurable]] attribute must be true.
If the [[Writable]] attribute may change from false to true,
then the [[Configurable]] attribute must be true.
If the target is non-extensible and P is non-existent, then all future calls to [[GetOwnProperty]] (P) must
describe P as non-existent (i.e. [[GetOwnProperty]] (P) must return undefined)
[[DefineOwnProperty]] (P, Desc)
The Type of the return value must be Boolean.
[[DefineOwnProperty]] must return false if P has previously been observed as a
non-configurable own property, unless either:
P is a non-configurable writable own data property. A non-configurable writable data property can be changed
into a non-configurable non-writable data property.
All attributes in Desc are the SameValue as P’s attributes.
[[DefineOwnProperty]] (P, Desc) must return false if target is non-extensible and P is a
non-existent own property. That is, a non-extensible target object cannot be extended with new properties.
[[HasProperty]] ( P )
The Type of the return value must be Boolean.
If P was previously observed as a non-configurable data or accessor own property, [[HasProperty]] must return true.
[[Get]] (P, Receiver)
If P was previously observed as a non-configurable, non-writable own data property with value v, then [[Get]] must
return the SameValue.
If P was previously observed as a non-configurable own accessor whose [[Get]] attribute is undefined, the [[Get]]
operation must return undefined.
[[Set]] ( P, V, Receiver)
The Type of the return value must be Boolean.
If P was previously observed as a non-configurable, non-writable own data property, then [[Set]] must return false unless V is the SameValue as P’s [[Value]]
attribute.
If P was previously observed as a non-configurable own accessor property whose [[Set]] attribute is undefined, the [[Set]] operation must return false.
[[Delete]] ( P )
The Type of the return value must be Boolean.
If P was previously observed to be a non-configurable own data or accessor property, [[Delete]] must return false.
[[Enumerate]] ( )
The Type of the return value must be Object.
[[OwnPropertyKeys]] ( )
The Type of the return value must be Object.
[[GetOwnPropertyNames]] ( )
The Type of the return value must be Object.
The return value must be an exotic Array object.
The returned array must contain at least the string and symbol-valued names of all own data and accessor properties
P that have previously been observed as non-configurable.
If the target is non-extensible, then it may not claim to have any own properties not observed by
[[GetOwnPropertyNames]].
Well-known intrinsics are built-in objects that are explicitly referenced by the algorithms of this specification and
which usually have Realm specific identities. Unless otherwise specified each intrinsic
object actually corresponds to a set of similar objects, one per Realm.
Within this specification a reference such as %name% means the intrinsic object, associated with the current Realm, corresponding to the name. Determination of the current Realm and its intrinsics is described in 8.2. The well-known intrinsics are listed in Table 7.
A specification type corresponds to meta-values that are used within algorithms to describe the semantics of ECMAScript
language constructs and ECMAScript language types. The specification types are Reference, List, Completion, Property Descriptor, Lexical
Environment, Environment Record, and Data Block.
Specification type values are specification artefacts that do not necessarily correspond to any specific entity within an
ECMAScript implementation. Specification type values may be used to describe intermediate results of ECMAScript expression
evaluation but such values cannot be stored as properties of objects or values of ECMAScript language variables.
The List type is used to explain the evaluation of argument lists (see 12.2.6) in
new expressions, in function calls, and in other algorithms where a simple ordered list of values is needed.
Values of the List type are simply ordered sequences of list elements containing the individual values. These sequences may
be of any length. The elements of a list may be randomly accessed using 0-origin indices. For notational convience an
array-like syntax can be used to access List elements. For example, arguments[2] is shorthand for saying the
3th element of the List arguments.
The Record type is used to describe data aggregations within the algorithms of this specification. A Record type value
consists of one or more named fields. The value of each field is either an ECMAScript value or an abstract value
represented by a name associated with the Record type. Field names are always enclosed in double brackets, for example
[[value]]
For notational convenience within this specification, an object literal-like syntax can be used to express a Record
value. For example, {[[field1]]: 42, [[field2]]: false, [[field3]]: empty} defines a Record value that has
three fields each of which is initialised to a specific value. Field name order is not significant. Any fields that are not
explicitly listed are considered to be absent.
In specification text and algorithms, dot notation may be used to refer to a specific field of a Record value. For
example, if R is the record shown in the previous paragraph then R.[[field2]] is shorthand for “the field of R named
[[field2]]”.
Schema for commonly used Record field combinations may be named, and that name may be used as a prefix to a literal
Record value to identify the specific kind of aggregations that is being described. For example:
PropertyDescriptor{[[Value]]: 42, [[Writable]]: false, [[Configurable]]: true}.
The Completion type is a Record used to explain the runtime propagation of values and control flow such as the
behaviour of statements (break, continue, return and throw) that
perform nonlocal transfers of control.
Values of the Completion type are Record values whole fields are defined as by Table 8.
The algorithms of this specification often implicitly return Completion Records whose [[type]] is normal. Unless it is
otherwise obvious from the context, an algorithm statement that returns a value that is not a Completion Record, such as:
NOTE The Reference type is used to explain the behaviour of such operators as
delete, typeof, the assignment operators, the super keyword and other language
features. For example, the left-hand operand of an assignment is expected to produce a reference.
A Reference is a resolved name or property binding. A Reference consists of three components, the
base value, the referenced name and the Boolean valued strict reference flag. The
base value is either undefined, an Object, a Boolean, a String, a Symbol, a Number, or an environment
record (8.1.1). A base value of undefined indicates that the
Reference could not be resolved to a binding. The referenced name is a String or Symbol value.
A Super Reference is a Reference that is used to represents a name binding that was expressed using the super keyword.
A Super Reference has an additional thisValue component and its base value will never be an
environment record.
The following abstract operations are used in this specification to access the components of references:
GetBase(V). Returns the base value component of the reference V.
GetReferencedName(V). Returns the referenced name component of the reference V.
IsStrictReference(V). Returns the strict reference flag component of the reference V.
HasPrimitiveBase(V). Returns true if Type(base)
is a Boolean, String, Symbol, or Number.
IsPropertyReference(V). Returns true if either the base value is an object or
HasPrimitiveBase(V) is true; otherwise returns false.
IsUnresolvableReference(V). Returns true if the base value is
undefined and false otherwise.
IsSuperReference(V). Returns true if this reference has a thisValue
component.
The following abstract operations are used in this specification to operate on references:
NOTE The object that may be created in step 5.a.ii is not accessible outside of the above
abstract operation and the ordinary object [[Get]] internal method. An implementation might choose to avoid the actual
creation of the object.
If succeeded is false and IsStrictReference(V) is true, then throw a
TypeError exception.
Return.
Else base must be a reference whose base is an environment record. So,
Return the result of calling the SetMutableBinding ({ REF _Ref365530812 \r \h \* MERGEFORMAT }8.1.1) concrete
method of base, passing GetReferencedName(V),
W, and IsStrictReference(V) as arguments.
NOTE The object that may be created in step 6.a.ii is not accessible outside of the above
algorithm and the ordinary object [[Set]] internal method. An implementation might choose to avoid the actual creation
of that object.
The Property Descriptor type is used to explain the manipulation and reification of Object property attributes. Values
of the Property Descriptor type are Records composed of named fields where each field’s name is an attribute name
and its value is a corresponding attribute value as specified in 6.1.7.1. In
addition, any field may be present or absent. The schema name used within this specification to tag literal descriptions
of Property Descriptor records is “PropertyDescriptor”.
Property Descriptor values may be further classified as data Property Descriptors and accessor Property Descriptors
based upon the existence or use of certain fields. A data Property Descriptor is one that includes any fields named either
[[Value]] or [[Writable]]. An accessor Property Descriptor is one that includes any fields named either [[Get]] or
[[Set]]. Any Property Descriptor may have fields named [[Enumerable]] and [[Configurable]]. A Property Descriptor value
may not be both a data Property Descriptor and an accessor Property Descriptor; however, it may be neither. A generic
Property Descriptor is a Property Descriptor value that is neither a data Property Descriptor nor an accessor Property
Descriptor. A fully populated Property Descriptor is one that is either an accessor Property Descriptor or a data Property
Descriptor and that has all of the fields that correspond to the property attributes defined in either Table 2 or Table 3.
A Property Descriptor may be derived from an object that has properties that directly correspond to the fields of a
Property Descriptor. Such a derived Property Descriptor has an additional field named [[Origin]] whose value is the
object from which the Property Descriptor was derived.
The following abstract operations are used in this specification to operate upon Property Descriptor values:
If LikeDesc is undefined, then set LikeDesc to Record{[[Value]]: undefined,
[[Writable]]: false, [[Get]]: undefined, [[Set]]: undefined, [[Enumerable]]: false,
[[Configurable]]: false}.
If Desc does not have a [[Value]] field, then set Desc.[[Value]] to
LikeDesc.[[Value]].
If Desc does not have a [[Writable]] field, then set Desc.[[Writable]] to
LikeDesc.[[Writable]].
Else,
If Desc does not have a [[Get]] field, then set Desc.[[Get]] to LikeDesc.[[Get]].
If Desc does not have a [[Set]] field, then set Desc.[[Set]] to LikeDesc.[[Set]].
If Desc does not have an [[Enumerable]] field, then set Desc.[[Enumerable]] to
LikeDesc.[[Enumerable]].
If Desc does not have a [[Configurable]] field, then set Desc.[[Configurable]] to
LikeDesc.[[Configurable]].
Return Desc.
6.2.5 The Lexical Environment and Environment Record Specification Types
The Lexical Environment and Environment
Record types are used to explain the behaviour of name resolution in nested functions and blocks. These types and the
operations upon them are defined in 8.1.
The Data Block specification type is used to describe a distinct and mutable sequence of byte-sized (8 bit) numeric
values. A Data Block value is created with a fixed number of bytes that each have the initial value 0.
For notational convenience within this specification, an array-like syntax can be used to express to the individual
bytes of a Data Block value. This notation presents a Data Block value as a 0-origined integer indexed sequence of bytes.
For example, if db is a 5 byte Data Block value then db[2] can be used to express access to its
3rd byte.
The following abstract operations are used in this specification to operate upon Data Block values:
These operations are not a part of the ECMAScript language; they are defined here to solely to aid the specification of the
semantics of the ECMAScript language. Other, more specialized abstract operations are defined throughout this
specification.
The ECMAScript language implicitly performs automatic type conversion as needed. To clarify the semantics of certain
constructs it is useful to define a set of conversion abstract operations. The conversion abstract operations are
polymorphic; they can accept a value of any ECMAScript language type or of a Completion Record value. But no other specification types are used
with these operations.
The abstract operation ToPrimitive takes an inputargument and
an optional argument PreferredType. The abstract operation ToPrimitive converts its input
argument to a non-Object type. If an object is capable of converting to more than one primitive type, it may use the
optional hint PreferredType to favour that type. Conversion occurs according to Table 9:
If IsCallable(exoticToPrim) is false, then throw a TypeError
exception.
Let result be the result of calling the [[Call]] internal method of exoticToPrim, with
argument as thisArgument and a List containing
hint as argumentsList.
If Type(result) is not Object, then return
result.
Throw a TypeError exception.
NOTE When ToPrimitive is called with no hint, then it generally behaves as if the hint were
Number. However, objects may over-ride this behaviour by defining a @@toPrimitive method. Of the objects defined in this
specification only Date objects (see 20.3) and Symbol objects (see 19.4.3.4) over-ride the default ToPrimitive behaviour. Date objects treat
no hint as if the hint were String.
ToNumber applied to Strings applies the following grammar to the input String. If the
grammar cannot interpret the String as an expansion of StringNumericLiteral, then the result of
ToNumber is NaN.
Syntax
StringNumericLiteral:::
StrWhiteSpaceopt
StrWhiteSpaceoptStrNumericLiteralStrWhiteSpaceopt
StrWhiteSpace:::
StrWhiteSpaceCharStrWhiteSpaceopt
StrWhiteSpaceChar:::
WhiteSpace
LineTerminator
StrNumericLiteral:::
StrDecimalLiteral
HexIntegerLiteral
StrDecimalLiteral:::
StrUnsignedDecimalLiteral
+StrUnsignedDecimalLiteral
-StrUnsignedDecimalLiteral
StrUnsignedDecimalLiteral:::
Infinity
DecimalDigits.DecimalDigitsoptExponentPartopt
.DecimalDigitsExponentPartopt
DecimalDigitsExponentPartopt
DecimalDigits:::
DecimalDigit
DecimalDigitsDecimalDigit
DecimalDigit:::one of
0123456789
ExponentPart:::
ExponentIndicatorSignedInteger
ExponentIndicator:::one of
eE
SignedInteger:::
DecimalDigits
+DecimalDigits
-DecimalDigits
HexIntegerLiteral:::
0xHexDigit
0XHexDigit
HexIntegerLiteralHexDigit
HexDigit:::one of
0123456789abcdefABCDEF
NOTE Some differences should be noted between the syntax of a StringNumericLiteral and a NumericLiteral (see 11.8.3):
A StringNumericLiteral may be preceded and/or followed by white space and/or line
terminators.
A StringNumericLiteral that is decimal may have any number of leading 0
digits.
A StringNumericLiteral that is decimal may be preceded by + or
- to indicate its sign.
A StringNumericLiteral that is empty or contains only white space is converted to
+0.
Infinityand –Infinity are recognised as a StringNumericLiteral but not as a NumericLiteral.
The conversion of a String to a Number value is similar overall to the determination of the Number value for a
numeric literal (see 11.8.3), but some of the details are different, so the
process for converting a String numeric literal to a value of Number type is given here in full. This value is
determined in two steps: first, a mathematical value (MV) is derived from the String numeric literal; second, this
mathematical value is rounded as described below.
The MV of StringNumericLiteral:::[empty] is 0.
The MV of StringNumericLiteral:::StrWhiteSpace is 0.
The MV of StringNumericLiteral:::StrWhiteSpaceoptStrNumericLiteralStrWhiteSpaceopt is the MV of StrNumericLiteral, no
matter whether white space is present or not.
The MV of StrNumericLiteral:::StrDecimalLiteral is the MV of StrDecimalLiteral.
The MV of StrNumericLiteral:::HexIntegerLiteral is the MV of HexIntegerLiteral.
The MV of StrDecimalLiteral:::StrUnsignedDecimalLiteral is the MV of StrUnsignedDecimalLiteral.
The MV of StrDecimalLiteral:::+StrUnsignedDecimalLiteral is the MV of StrUnsignedDecimalLiteral.
The MV of StrDecimalLiteral:::-StrUnsignedDecimalLiteral is the negative of the MV of StrUnsignedDecimalLiteral. (Note that if the MV of StrUnsignedDecimalLiteral is 0, the negative of this MV is also 0. The rounding rule described
below handles the conversion of this signless mathematical zero to a floating-point +0 or −0 as
appropriate.)
The MV of StrUnsignedDecimalLiteral:::Infinity is 1010000 (a value
so large that it will round to +∞).
The MV of StrUnsignedDecimalLiteral:::DecimalDigits. is the MV of DecimalDigits.
The MV of StrUnsignedDecimalLiteral:::DecimalDigits.DecimalDigits is the MV of
the first DecimalDigits plus (the MV of the second DecimalDigits
times 10−n), where n is the
number of characters in the second DecimalDigits.
The MV of StrUnsignedDecimalLiteral:::DecimalDigits.ExponentPart is the MV of
DecimalDigits times 10e, where e is the MV of ExponentPart.
The MV of StrUnsignedDecimalLiteral:::DecimalDigits.DecimalDigitsExponentPart is (the MV of the first DecimalDigits plus (the MV of the second
DecimalDigits times 10−n)) times 10e, where n is the number
of characters in the second DecimalDigits and e is the MV of ExponentPart.
The MV of StrUnsignedDecimalLiteral:::.DecimalDigits is the MV of DecimalDigits times
10−n, where n is the number of characters in DecimalDigits.
The MV of StrUnsignedDecimalLiteral:::.DecimalDigitsExponentPart is the MV of
DecimalDigits times 10e−n, where n is the number of characters in
DecimalDigits and e is the MV of ExponentPart.
The MV of StrUnsignedDecimalLiteral:::DecimalDigits is the MV of DecimalDigits.
The MV of StrUnsignedDecimalLiteral:::DecimalDigitsExponentPart is the MV of DecimalDigits times
10e, where e is the MV of ExponentPart.
The MV of DecimalDigits:::DecimalDigit is the MV of DecimalDigit.
The MV of DecimalDigits:::DecimalDigitsDecimalDigit is (the MV of DecimalDigits times
10) plus the MV of DecimalDigit.
The MV of ExponentPart:::ExponentIndicatorSignedInteger is the MV of
SignedInteger.
The MV of SignedInteger:::DecimalDigits is the MV of DecimalDigits.
The MV of SignedInteger:::+DecimalDigits is the MV of DecimalDigits.
The MV of SignedInteger:::-DecimalDigits is the negative of the MV of
DecimalDigits.
The MV of DecimalDigit:::0 or of HexDigit:::0 is 0.
The MV of DecimalDigit:::1 or of HexDigit:::1 is 1.
The MV of DecimalDigit:::2 or of HexDigit:::2 is 2.
The MV of DecimalDigit:::3 or of HexDigit:::3 is 3.
The MV of DecimalDigit:::4 or of HexDigit:::4 is 4.
The MV of DecimalDigit:::5 or of HexDigit:::5 is 5.
The MV of DecimalDigit:::6 or of HexDigit:::6 is 6.
The MV of DecimalDigit:::7 or of HexDigit:::7 is 7.
The MV of DecimalDigit:::8 or of HexDigit:::8 is 8.
The MV of DecimalDigit:::9 or of HexDigit:::9 is 9.
The MV of HexDigit:::a or of HexDigit:::A is 10.
The MV of HexDigit:::b or of HexDigit:::B is 11.
The MV of HexDigit:::c or of HexDigit:::C is 12.
The MV of HexDigit:::d or of HexDigit:::D is 13.
The MV of HexDigit:::e or of HexDigit:::E is 14.
The MV of HexDigit:::f or of HexDigit:::F is 15.
The MV of HexIntegerLiteral:::0xHexDigit is the MV of HexDigit.
The MV of HexIntegerLiteral:::0XHexDigit is the MV of HexDigit.
The MV of HexIntegerLiteral:::HexIntegerLiteralHexDigit is (the MV of HexIntegerLiteral
times 16) plus the MV of HexDigit.
Once the exact MV for a String numeric literal has been determined, it is then rounded to a value of the Number type.
If the MV is 0, then the rounded value is +0 unless the first non white space character in the String numeric literal is
‘-’, in which case the rounded value is −0. Otherwise, the rounded value must be the
Number value for the MV (in the sense defined in 6.1.6), unless
the literal includes a StrUnsignedDecimalLiteral and the literal has more than 20 significant
digits, in which case the Number value may be either the Number value for the MV of a literal produced by replacing each
significant digit after the 20th with a 0 digit or the Number value for the MV of a literal produced by replacing each
significant digit after the 20th with a 0 digit and then incrementing the literal at the 20th digit position. A digit is
significant if it is not part of an ExponentPart and
it is not 0; or
there is a nonzero digit to its left and there is a nonzero digit, not in the ExponentPart, to its right.
The abstract operation ToInt32 converts its argument to one of 232 integer values in the range −231 through 231−1,
inclusive. This abstract operation functions as follows:
Let number be the result of calling ToNumber on the input argument.
The abstract operation ToUint32 converts its argument to one of 232 integer values in the range 0 through 232−1, inclusive. This abstract operation functions as
follows:
Let number be the result of calling ToNumber on the input argument.
The abstract operation ToInt16 converts its argument to one of 216 integer values in the range −32768
through 32767, inclusive. This abstract operation functions as
follows:
Let number be the result of calling ToNumber on the input argument.
The abstract operation ToUint16 converts its argument to one of 216 integer values in the range 0 through 216−1, inclusive. This abstract operation functions as
follows:
Let number be the result of calling ToNumber on the input argument.
The abstract operation ToInt8 converts its argument to one of 28 integer values in the range −128 through
127, inclusive. This abstract operation functions as follows:
Let number be the result of calling ToNumber on the input argument.
The abstract operation ToUint8 converts its argument to one of 28 integer values in the range 0 through 255, inclusive. This abstract operation functions as follows:
Let number be the result of calling ToNumber on the input argument.
7.1.11
ToUint8Clamp: (Unsigned 8 Bit Integer, Clamped)
The abstract operation ToUint8Clamp converts its argument to one of 28 integer values in the range 0 through 255, inclusive. This abstract operation functions as follows:
Let number be the result of calling ToNumber on the input argument.
The abstract operation ToString converts a Number m to String format as
follows:
If m is NaN, return the String "NaN".
If m is +0 or −0, return the String "0".
If m is less than zero, return the String concatenation of the String "-" and ToString(−m).
If m is +∞, return the String "Infinity".
Otherwise, let n, k, and s be integers such that k ≥ 1, 10k−1
≤ s < 10k, the Number value for s × 10n−k is
m, and k is as small as possible. Note that k is the number of digits in the decimal
representation of s, that s is not divisible by 10, and that the least significant digit of s
is not necessarily uniquely determined by these criteria.
If k ≤ n ≤ 21, return the String consisting of the k digits of the decimal representation
of s (in order, with no leading zeroes), followed by n−k occurrences of the character
‘0’.
If 0 < n ≤ 21, return the String consisting of the most significant n digits of the decimal
representation of s, followed by a decimal point ‘.’, followed by the remaining
k−n digits of the decimal representation of s.
If −6 < n ≤ 0, return the String consisting of the character ‘0’,
followed by a decimal point ‘.’, followed by −n occurrences of the character
‘0’, followed by the k digits of the decimal representation of s.
Otherwise, if k = 1, return the String consisting of the single digit of s, followed by lowercase
character ‘e’, followed by a plus sign ‘+’ or minus sign
‘−’ according to whether n−1 is positive or negative, followed by the
decimal representation of the integer abs(n−1) (with no
leading zeroes).
Return the String consisting of the most significant digit of the decimal representation of s, followed by a
decimal point ‘.’, followed by the remaining k−1 digits of the decimal representation of
s, followed by the lowercase character ‘e’, followed by a plus sign
‘+’ or minus sign ‘−’ according to whether n−1
is positive or negative, followed by the decimal representation of the integer abs(n−1) (with no leading zeroes).
NOTE 1 The following observations may be useful as guidelines for implementations, but are
not part of the normative requirements of this Standard:
If x is any Number value other than −0, then ToNumber(ToString(x)) is exactly the same Number value as x.
The least significant digit of s is not always uniquely determined by the requirements listed in step 5.
NOTE 2 For implementations that provide more accurate conversions than required by the rules
above, it is recommended that the following alternative version of step 5 be used as a guideline:
Otherwise, let n, k, and s be integers such that k ≥ 1, 10k−1
≤ s < 10k, the Number value for s × 10n−k is
m, and k is as small as possible. If there are multiple possibilities for s, choose the value of
s for which s × 10n−k is closest in value to m. If there are
two such possible values of s, choose the one that is even. Note that k is the number of digits in the
decimal representation of s and that s is not divisible by 10.
NOTE 3 Implementers of ECMAScript may find useful the paper and code written by David M. Gay
for binary-to-decimal conversion of floating-point numbers:
The abstract operation ToLength converts its argument to an integer suitable for use as the length of an
array-like object. It performs the following steps:
The abstract operation CheckObjectCoercible throws an error if its argument is a value that cannot be converted to an
Object using ToObject. It is defined by Table 14:
The internal comparison abstract operation SameValue(x, y), where x and y are
ECMAScript language values, produces true or false. Such a
comparison is performed as follows:
If x and y are exactly the same sequence of code units (same length and same code units in
corresponding positions) return true; otherwise, return false.
The internal comparison abstract operation SameValueZero(x, y), where x and y
are ECMAScript language values, produces true or false. Such a
comparison is performed as follows:
If x and y are exactly the same sequence of code units (same length and same code units in
corresponding positions) return true; otherwise, return false.
The abstract operation IsConstructor determines if its argument, which must be an ECMAScript language value or a Completion Record, is a function object with a [[Construct]] internal
method.
The abstract operation IsExtensible is used to determine whether
additional properties can be added to the object that is O. A Boolean value is returned. This abstract operation
performs the following steps:
The comparison x < y, where x and y are values, produces true,
false, or undefined (which indicates that at least one operand is NaN). In addition to x and
y the algorithm takes a Boolean flag named LeftFirst as a parameter. The flag is used to
control the order in which operations with potentially visible side-effects are performed upon x and
y. It is necessary because ECMAScript specifies left to right evaluation of expressions. The default value of
LeftFirst is true and indicates that the x parameter corresponds to an expression
that occurs to the left of the y parameter’s corresponding expression. If LeftFirst
is false, the reverse is the case and operations must be performed upon y before x. Such a
comparison is performed as follows:
If py is a prefix of px, return false. (A String value p is a prefix of String value
q if q can be the result of concatenating p and some other String r. Note that any
String is a prefix of itself, because r may be the empty String.)
If px is a prefix of py, return true.
Let k be the smallest nonnegative integer such that the character at position k within px is
different from the character at position k within py. (There must be such a k, for neither
String is a prefix of the other.)
Let m be the integer that is the code unit value for the character at position k within
px.
Let n be the integer that is the code unit value for the character at position k within
py.
If m < n, return true. Otherwise, return false.
Else,
Let nx be the result of calling ToNumber(px). Because px and
py are primitive values evaluation order is not important.
If nx and ny are the same Number value, return false.
If nx is +0 and ny is −0, return false.
If nx is −0 and ny is +0, return false.
If nx is +∞, return false.
If ny is +∞, return true.
If ny is −∞, return false.
If nx is −∞, return true.
If the mathematical value of nx is less than the mathematical value of ny —note that these
mathematical values are both finite and not both zero—return true. Otherwise, return
false.
NOTE 1 Step 5 differs from step 11 in the algorithm for the addition operator +
(12.6.3) in using “and” instead of “or”.
NOTE 2 The comparison of Strings uses a simple lexicographic ordering on sequences of code unit
values. There is no attempt to use the more complex, semantically oriented definitions of character or string equality and
collating order defined in the Unicode specification. Therefore String values that are canonically equal according to the
Unicode standard could test as unequal. In effect this algorithm assumes that both Strings are already in normalised form.
Also, note that for strings containing supplementary characters, lexicographic ordering on sequences of UTF-16 code unit
values differs from that on sequences of code point values.
The abstract operation Get is used to retrieve the value of a specific
property of an object. The operation is called with arguments O and P where O is the
object and P is the property key. This abstract operation performs the following
steps:
The abstract operation Put is used to set the value of a specific
property of an object. The operation is called with arguments O, P, V, and Throw where O is the object, P is the property key,
V is the new value for the property and Throw is a Boolean flag. This abstract operation
performs the following steps:
The abstract operation CreateDataProperty is used to create a new own
property of an object. The operation is called with arguments O, P, and V where
O is the object, P is the property key, and V is the value
for the property. This abstract operation performs the following steps:
Let newDesc be the PropertyDescriptor{[[Value]]: V, [[Writable]]: true, [[Enumerable]]:
true, [[Configurable]]: true}.
Return the result of calling the [[DefineOwnProperty]] internal method of O passing P and newDesc
as arguments.
NOTE This abstract operation creates a property whose attributes are set to the same defaults
used for properties created by the ECMAScript language assignment operator. Normally, the property will not already exist.
If it does exist and is not configurable or O is not extensible [[DefineOwnProperty]] will
return false.
The abstract operation CreateDataPropertyOrThrow is used to create a
new own property of an object. It throws a TypeError exception if the requested property update
cannot be performed. The operation is called with arguments O, P, and V where O
is the object, P is the property key, and V is the value for the
property. This abstract operation performs the following steps:
If success is false, then throw a TypeError exception.
Return success.
NOTE This abstract operation creates a property whose attributes are set to the same defaults
used for properties created by the ECMAScript language assignment operator. Normally, the property will not already exist.
If it does exist and is not configurable or O is not extensible [[DefineOwnProperty]] will
return false causing this operation to throw a TypeError
exception.
The abstract operation DefinePropertyOrThrow is used to call the
[[DefineOwnProperlty]] internal method of an object in a manner that will throw a TypeError exception if the
requested property update cannot be performed. The operation is called with arguments O, P, and
desc where O is the object, P is the property key, and
desc is the Property Descriptor for the property. This
abstract operation perform, the following steps:
The abstract operation DeletePropertyOrThrow is used to remove a specific own property of an object. It throws an
exception if the property is not configurable. The operation is called with arguments O and P where
O is the object and P is the property key. This abstract operation
performs the following steps:
The abstract operation GetMethod is used to get the value of a specific property of an object when the value of the
property is expected to be a function. The operation is called with arguments O and P where
O is the object, P is the property key. This abstract operation
performs the following steps:
The abstract operation HasProperty is used to determine whether an object has a property with the specified property key. The property may be either an own or inherited. A Boolean value is returned. The
operation is called with arguments O and P where O is the object and P is the
property key. This abstract operation performs the following steps:
The abstract operation HasOwnProperty is used to determine whether an object has an own property with the specified property key. A Boolean value is returned. The operation is called with arguments O
and P where O is the object and P is the property key. This
abstract operation performs the following steps:
The abstract operation Invoke is used to call a method property of an
object. The operation is called with arguments O, P , and optionally args where
O serves as both the lookup point for the property and the this value of the call, P is the property key, and args is the list of arguments values passed to the method. If
args is not present, an empty List is used as its value.
This abstract operation performs the following steps:
The abstract operation TestIntegrityLevel is used to determine if the
set of own properties of an object are fixed. This abstract operation performs the following steps:
The abstract operation CreateArrayFromList is used to create an Array
object whose elements are provided by a List. This abstract operation
performs the following steps:
The abstract operation CreateListFromArrayLike is used to create a List value whose elements are provided by the indexed properties of an
array-like object. This abstract operation performs the following steps:
If Type(obj) is not Object, then throw a TypeError
exception.
The abstract operation OrdinaryHasInstance implements the default
algorithm for determining if an object O inherits from the instance object inheritance path provided by
constructor C. This abstract operation performs the following steps:
The abstract operation GetPrototypeFromConstructor determines the
[[Prototype]] value that should be used to create an object corresponding to a specific constructor. The value is retrieved
from the constructor’s prototype property, if it exists. Otherwise the supplied default is used for
[[Prototype]]. This abstract operation performs the following steps:
Assert: intrinsicDefaultProto is a string value that is this
specification’s name of an intrinsic object. The corresponding object must be an intrinsic that is intended to
be used as the [[Prototype]] value of an object.
If IsConstructor (constructor) is false, then throw a TypeError
exception.
Let proto be the result of Get(constructor, "prototype").
Let proto be realm’s intrinsic object named intrinsicDefaultProto.
Return proto.
NOTE If constructor does not supply a [[Prototype]] value, the default value that is
used is obtained from the Code Realm of the constructor function rather than
from the running execution context. This accounts for the possibility that a
built-in @@create method from a different Code Realm might be installed on
constructor.
The abstract operation GetOption is used to retrieve the value of a
specific property of an object in situation where the object may not be present. The operation is called with arguments
options and P where options is the object and P is the property key. This abstract operation performs the following steps:
The abstract operation IteratorStep with argument iterator requests the next value from iterator
and returns either false indicating that the iterator has reached its end or the IteratorResult
object if a next value is available. IteratorStep performs the following steps:
Let result be the result of IteratorNext(iterator).
The abstract operation CreateIterResultObject with arguments value and done creates an object that
supports the IteratorResult interface by performing the following steps:
The abstract operation CreateListIterator with argument list creates an Iterator (25.1.2) object whose next method returns the successive elements of list. It
performs the following steps:
Let iterator be the result of ObjectCreate(%ObjectPrototype%,
([[IteratedList]], [[ListIteratorNextIndex]])).
Set iterator’s [[IteratedList]] internal
slot to list.
Set iterator’s [[ListIteratorNextIndex]] internal slot to 0.
Define ListIterator next (7.4.7.1) as an own property of
iterator.
The abstract operation CreateEmptyIterator with no arguments creates an Iterator object whose next method always reports
that the iterator is done. It performs the following steps:
Promise Objects (25.4) serve as a place holder for the eventual result of a deferred
(and possibly asynchronous) computation.
Within this specification the adjective “eventual” mean a value or a Promise object that will ultimately
resolves to the value. For example, “Returns an eventual String” is equivalent to “Returns either a
String or a Promise object that will eventually resolves to a String”. A “resolved value” is the final
value of an “eventual value”.
NOTE The Promise related abstract operations defined in this subclause are used by
specification algorithms when they perform or respond to asynchronous operations. They ensure that the actual built-in
Promise operations are used by the algorithms, even if ECMAScript code has modified the properties of %Promise% or
%PromisePrototype%.
The abstract operation PromiseNew allocates and initilises a new promise object for use by specification
algorithm. The executor argument initiates the deferred computation.
The abstract operation PromiseNewCapability allocates a PromiseCapability record (25.4.1.1) for a builtin promise object for use by specification
algorithm.
Let resolveResult be the result of calling the [[Call]] internal method of capability.[[Resolve]] with
undefined as thisArgument and (value) as argumentsList.
A Lexical Environment is a specification type used to define the association of Identifiers to specific variables and functions based upon the lexical nesting structure of ECMAScript
code. A Lexical Environment consists of an Environment Record and a possibly null
reference to an outer Lexical Environment. Usually a Lexical Environment is associated with some specific syntactic
structure of ECMAScript code such as a FunctionDeclaration, a BlockStatement, or a Catch clause of a TryStatement and a
new Lexical Environment is created each time such code is evaluated.
An Environment Record records the identifier bindings that are created
within the scope of its associated Lexical Environment.
The outer environment reference is used to model the logical nesting of Lexical Environment values. The outer reference
of a (inner) Lexical Environment is a reference to the Lexical Environment that logically surrounds the inner Lexical
Environment. An outer Lexical Environment may, of course, have its own outer Lexical Environment. A Lexical Environment may
serve as the outer environment for multiple inner Lexical Environments. For example, if a FunctionDeclaration contains two nested FunctionDeclarations then the Lexical
Environments of each of the nested functions will have as their outer Lexical Environment the Lexical Environment of the
current evaluation of the surrounding function.
A global environment is a Lexical Environment which does not have an outer environment. The global
environment’s outer environment reference is null. A global environment’s environment record may be
prepopulated with identifier bindings and includes an associated global object whose properties provide some of the global environment’s identifier bindings. This global object is the
value of a global environment’s this binding. As ECMAScript code is executed, additional properties may
be added to the global object and the initial properties may be modified.
A method environment is a Lexical Environment that corresponds to the invocation of an ECMAScript function object that establishes a new this binding. A
method environment also captures the state necessary to support super method invocations.
Lexical Environments and Environment Record values are purely specification
mechanisms and need not correspond to any specific artefact of an ECMAScript implementation. It is impossible for an
ECMAScript program to directly access or manipulate such values.
There are two primary kinds of Environment Record values used in this specification: declarative environment
records and object environment records. Declarative environment records are used to define the effect of
ECMAScript language syntactic elements such as FunctionDeclarations, VariableDeclarations, and Catch clauses that directly associate identifier
bindings with ECMAScript language values. Object environment records are used
to define the effect of ECMAScript elements such as WithStatement that associate identifier
bindings with the properties of some object. Global Environment Records and
Function Environment Records are specializations that are used for
specifically for Script global declarations and for top-level declarations within functions.
For specification purposes Environment Record values can be thought of as existing in a simple object-oriented
hierarchy where Environment Record is an abstract class with three concrete subclasses, declarative environment record, object environment record, and global
environment record. Function environment records are a subclass of declarative environment record. The abstract class includes the abstract
specification methods defined in Table 16. These abstract methods have distinct concrete
algorithms for each of the concrete subclasses.
Table 16 — Abstract Methods of Environment Records
Method
Purpose
HasBinding(N)
Determine if an environment record has a binding for an identifier. Return true if it does and false if it does not. The String value N is the text of the identifier.
CreateMutableBinding(N, D)
Create a new but uninitialised mutable binding in an environment record. The String value N is the text of the bound name. If the optional Boolean argument D is true the binding is may be subsequently deleted.
CreateImmutableBinding(N)
Create a new but uninitialised immutable binding in an environment record. The String value N is the text of the bound name.
InitialiseBinding(N,V)
Set the value of an already existing but uninitialised binding in an environment record. The String value N is the text of the bound name. V is the value for the binding and is a value of any ECMAScript language type.
SetMutableBinding(N,V, S)
Set the value of an already existing mutable binding in an environment record. The String value N is the text of the bound name. V is the value for the binding and may be a value of any ECMAScript language type. S is a Boolean flag. If S is true and the binding cannot be set throw a TypeError exception. S is used to identify strict mode references.
GetBindingValue(N,S)
Returns the value of an already existing binding from an environment record. The String value N is the text of the bound name. S is used to identify strict mode references. If S is true and the binding does not exist or is uninitialised throw a ReferenceError exception.
DeleteBinding(N)
Delete a binding from an environment record. The String value N is the text of the bound name If a binding for N exists, remove the binding and return true. If the binding exists but cannot be removed return false. If the binding does not exist return true.
HasThisBinding()
Determine if an environment record establishes a this binding. Return true if it does and false if it does not.
HasSuperBinding()
Determine if an environment record establishes a super method binding. Return true if it does and false if it does not.
WithBaseObject ()
If this environment record is associated with a with statement, return the with object. Otherwise, return undefined.
Each declarative environment record is associated with an ECMAScript program scope containing variable, constant,
let, class, module, import, and/or function declarations. A declarative environment record binds the set of identifiers
defined by the declarations contained within its scope.
The behaviour of the concrete specification methods for Declarative Environment Records is defined by the following
algorithms.
The concrete environment record method HasBinding for declarative environment records simply determines if the
argument identifier is one of the identifiers bound by the record:
The concrete Environment Record method CreateMutableBinding for declarative
environment records creates a new mutable binding for the name N that is uninitialised. A binding must not
already exist in this Environment Record for N. If Boolean argument
D is provided and has the value true the new binding is marked as being subject to deletion.
Assert: envRec does not already have a binding for N.
Create a mutable binding in envRec for N and record that it is uninitialised. If D is
true record that the newly created binding may be deleted by a subsequent DeleteBinding call.
The concrete Environment Record method CreateImmutableBinding for declarative
environment records creates a new immutable binding for the name N that is uninitialised. A binding must not
already exist in this environment record for N.
The concrete Environment Record method InitialiseBinding for declarative
environment records is used to set the bound value of the current binding of the identifier whose name is the value of
the argument N to the value of argument V. An uninitialised binding for N must already
exist.
The concrete Environment Record method SetMutableBinding for declarative
environment records attempts to change the bound value of the current binding of the identifier whose name is the value
of the argument N to the value of argument V. A binding for N must already exist. If
the binding is an immutable binding, a TypeError is thrown if S
is true.
The concrete Environment Record method GetBindingValue for declarative
environment records simply returns the value of its bound identifier whose name is the value of the argument
N. The binding must already exist. If S is true and the binding is an uninitialised
immutable binding throw a ReferenceError exception.
The concrete Environment Record method DeleteBinding for declarative
environment records can only delete bindings that have been explicitly designated as being subject to deletion.
Each object environment record is associated with an object called its binding object. An object environment
record binds the set of string identifier names that directly correspond to the property names of its binding object.
Property keys that are not strings in the form of an IdentifierName are not included in the set
of bound identifiers. Both own and inherited properties are included in the set regardless of the setting of their
[[Enumerable]] attribute. Because properties can be dynamically added and deleted from objects, the set of identifiers
bound by an object environment record may potentially change as a side-effect of any operation that adds or deletes
properties. Any bindings that are created as a result of such a side-effect are considered to be a mutable binding even
if the Writable attribute of the corresponding property has the value false. Immutable bindings do not exist for
object environment records.
Object environment records also have a possibly empty List of
strings called unscopables. The strings in this List
are excluded from the environment records set of bound names, regardless of whether or not they exist as property keys
of its binding object.
Object environment records created for with statements (13.10) can
provide their binding object as an implicit this value for use in function calls. The capability is controlled by a
withEnvironment Boolean value that is associated with each object environment record. By default, the value
of withEnvironment is false for any object environment record.
The behaviour of the concrete specification methods for Object Environment Records is defined by the following
algorithms.
The concrete Environment Record method HasBinding for object environment
records determines if its associated binding object has a property whose name is the value of the argument
N:
The concrete Environment Record method CreateMutableBinding for object
environment records creates in an environment record’s associated binding object a property whose name is the
String value and initialises it to the value undefined. If Boolean argument D is provided and has the
value true the new property’s [[Configurable]] attribute is set to true, otherwise it is set to
false.
If D is true then let configValue be true otherwise let configValue be
false.
Return the result of DefinePropertyOrThrow(bindings, N,
PropertyDescriptor{[[Value]]:undefined, [[Writable]]: true, [[Enumerable]]: true ,
[[Configurable]]: configValue}).
NOTE Normally envRec will not have a binding for N but if it does, the
semantics of DefinePropertyOrThrow may result in an existing binding being
replaced or shadowed or cause an abrupt completion to be returned.
The concrete Environment Record method InitialiseBinding for object
environment records is used to set the bound value of the current binding of the identifier whose name is the value of
the argument N to the value of argument V. An uninitialised binding for N must already
exist.
The concrete Environment Record method SetMutableBinding for object
environment records attempts to set the value of the environment record’s associated binding object’s
property whose name is the value of the argument N to the value of argument V. A property named
N normally already exists but if it does not or is not currently writable, error handling is determined by
the value of the Boolean argument S.
The concrete Environment Record method GetBindingValue for object environment
records returns the value of its associated binding object’s property whose name is the String value of the
argument identifier N. The property should already exist but if it does not the result depends upon the value
of the S argument:
The concrete Environment Record method DeleteBinding for object environment
records can only delete bindings that correspond to properties of the environment object whose [[Configurable]]
attribute have the value true.
A function environment record is a declarative environment record
that is used to represent the outer most scope of a function that provides a this binding. In addition to
its identifier bindings, a function environment record contains the this value used within its scope. If such a
function references super, its function environment record also contains the state that is used to perform
super method invocations from within the function.
Function environment records store their this binding as the value of their thisValue. If the
associated function references super, the environment record stores in HomeObject
the object that the function is bound to as a method and in MethodName the property key used for unqualified super invocations from within the function. The default
value for HomeObject and MethodName is undefined.
Methods environment records support all of Declarative Environment
Record methods listed in Table 16 and share the same specifications for all of those methods
except for HasThisBinding and HasSuperBinding. In addition, declarative environment records support the methods listed
in Table 17:
Table 17 — Additional Methods of Function Environment Records
Method
Purpose
GetThisBinding()
Return the value of this environment record’s this binding.
Return the object that is the base for super property accesses bound in this environment record. The object is derived from this environment record’s HomeObject binding. If the value is Empty, return undefined.
A global environment record is used to represent the outer most scope that is shared by all of the ECMAScript Script elements that are processed in a common Realm (8.2). A global environment provides the bindings for built-in globals (clause 18), properties of the global object, and for all declarations that are not
function code and that occur within Script productions.
A global environment record is logically a single record but it is specified as a composite encapsulating an object environment record and a declarative environment record. The object environment record has as its base object the global object of the
associated Realm. This global object is also the value of the global environment
record’s thisValue. The object environment record
component of a global environment record contains the bindings for all built-in globals (clause 18) and all bindings introduced by a FunctionDeclaration or
VariableStatement contained in global code. The bindings for all other ECMAScript declarations
in global code are contained in the declarative environment record
component of the global environment record.
Properties may be created directly on a global object. Hence, the object
environment record component of a global environment record may contain both bindings created explicitly by FunctionDeclaration or VariableStatement declarations and binding created
implicitly as properties of the global object. In order to identify which bindings were explicitly created using
declarations, a global environment record maintains a list of the names bound using its CreateGlobalVarBindings and
CreateGlobalFunctionBindings concrete methods.
Global environment records have the additional state components listed in Table 18 and the
additional methods listed in Table 19.
Table 18 -- Components of Global Environment Records
Component
Purpose
ObjectEnvironment
An Object Environment Record whose base object is the global object. Contains global built-in bindings as well as bindings for FunctionDeclaration or VariableStatement declarations in global code for the associated Realm.
DeclarativeEnvironment
A Declarative Environment Record that contains bindings for all declarations in global for the associated Realm code except for FunctionDeclaration and VariableStatement declarations.
VarNames
A List containing the string names bound by FunctionDeclaration or VariableStatement declarations in global code for the associated Realm.
Table 19 — Additional Methods of Global Environment Records
Method
Purpose
GetThisBinding()
Return the value of this environment record’s this binding.
Determines if the argument identifier has a binding in this environment record that was created using a lexical declaration such as a LexicalDeclaration or a ClassDeclaration.
Used to create global var bindings in the ObjectEnvironmentComponent of the environment record. The binding will be a mutable binding. The corresponding global object property will have attribute values approate for a var. The String value N is the text of the bound name. V is the initial value of the binding If the optional Boolean argument D is true the binding is may be subsequently deleted. This is logically equivalent to CreateMutableBinding but it allows var declarations to receive special treatment.
Used to create and initialise global function bindings in the ObjectEnvironmentComponent of the environment record. The binding will be a mutable binding. The corresponding global object property will have attribute values approate for a function.The String value N is the text of the bound name. If the optional Boolean argument D is true the binding is may be subsequently deleted. This is logically equivalent to CreateMutableBinding followed by a SetMutableBinding but it allows function declarations to receive special treatment.
The behaviour of the concrete specification methods for Global Environment Records is defined by the following
algorithms.
The concrete environment record method HasBinding for global environment records simply determines if the argument
identifier is one of the identifiers bound by the record:
The concrete environment record method CreateMutableBinding for global environment records creates a new mutable
binding for the name N that is uninitialised. The binding is created in the associated
DeclarativeEnvironment. A binding for N must not already exist in the DeclarativeEnvironment. If Boolean
argument D is provided and has the value true the new binding is marked as being subject to
deletion.
The concrete Environment Record method CreateImmutableBinding for global
environment records creates a new immutable binding for the name N that is uninitialised. A binding must not
already exist in this environment record for N.
The concrete Environment Record method InitialiseBinding for global
environment records is used to set the bound value of the current binding of the identifier whose name is the value of
the argument N to the value of argument V. An uninitialised binding for N must already
exist.
The concrete Environment Record method SetMutableBinding for global
environment records attempts to change the bound value of the current binding of the identifier whose name is the value
of the argument N to the value of argument V. If the binding is an immutable binding, a
TypeError is thrown if S is true. A
property named N normally already exists but if it does not or is not currently writable, error handling is
determined by the value of the Boolean argument S.
The concrete Environment Record method GetBindingValue for global environment
records simply returns the value of its bound identifier whose name is the value of the argument N. If
S is true and the binding is an uninitialised binding throw a ReferenceError exception. A
property named N normally already exists but if it does not or is not currently writable, error handling is
determined by the value of the Boolean argument S.
The concrete Environment Record method DeleteBinding for global environment
records can only delete bindings that have been explicitly designated as being subject to deletion.
The concrete environment record method HasVarDeclaration for global environment records determines if the argument
identifier has a binding in this record that was created using a VariableStatement or a FunctionDeclaration:
The concrete environment record method HasLexicalDeclaration for global environment records determines if the
argument identifier has a binding in this record that was created using a lexical declaration such as a LexicalDeclaration or a ClassDeclaration:
The concrete environment record method CanDeclareGlobalVar for global environment records determines if a
corresponding CreateGlobalVarBinding call would succeed if called for the same
argument N. Redundent var declarations and var declarations for pre-existing global object properties are
allowed.
The concrete environment record method CanDeclareGlobalFunction for global environment records determines if a
corresponding CreateGlobalFunctionBinding call would succeed if called
for the same argument N.
The concrete Environment Record method CreateGlobalVarBinding for global
environment records creates a mutable binding in the associated object
environment record and records the bound name in the associated VarNames List. If a binding already exists, it is reused.
The concrete Environment Record method CreateGlobalFunctionBinding for global
environment records creates a mutable binding in the associated object
environment record and records the bound name in the associated VarNames List. If a binding already exists, it is replaced.
NOTE Global function declarations are always represented as own properties of the global
object. If possible, an existing own property is reconfigured to have a standard set of attribute values.
The abstract operation GetIdentifierReference is called with a Lexical
Environmentlex, a String name, and a Boolean flag strict. The value of
lex may be null. When called, the following steps are performed:
If lex is the value null, then
Return a value of type Reference whose base value is
undefined, whose referenced name is name, and whose strict reference flag is strict.
Let envRec be lex’s environment record.
Let exists be the result of calling the HasBinding(N) concrete method of envRec passing
name as the argument N.
When the abstract operation NewDeclarativeEnvironment is called with either a Lexical Environment or null as argument E the following steps are
performed:
When the abstract operation NewObjectEnvironment is called with an Object O and a Lexical EnvironmentE (or null) as arguments, the following steps
are performed:
When the abstract operation NewFunctionEnvironment is called with an ECMAScript function Object F and an
ECMAScript value T as arguments, the following steps are performed:
Before it is evaluated, all ECMAScript code must be associated with a Realm. Conceptually, a realm consists of a
set of intrinsic objects, an ECMAScript global environment, all of the ECMAScript code that is loaded within the scope of
that global environment, a Loader object that can associate new ECMAScript code with the realm, and other associated state
and resources.
A Realm is specified as a Record with the fields specified in Table 20:
Table 20 — Realm Record Fields
Field Name
Value
Meaning
[[intrinsics]]
A record whose field names are intrinsic keys and whose values are objects
These are the intrinsic values used by code associated with this Realm
[[globalThis]]
An object
The global object for this Realm
[[globalEnv]]
An ECMAScript environment
The global environment for this Realm
[[directEvalTranslate]]
undefined or an object that is callable as a function.
[[directEvalFallback]]
undefined or an object that is callable as a function.
[[indirectEval]]
undefined or an object that is callable as a function.
[[Function]]
undefined or an object that is callable as a function.
[[loader]]
any ECMAScript identifier or empty
The Loader object that can associate ECMAScript code with this Realm
When the abstract operation CreateRealm is called with no arguments, the following steps are performed:
Let realmRec be a new Record.
Let intrinsics be a record initialized with the values listed in Table 7. Each intrinsic
object is a new object value fully and recursively populated with properties values as defined by the specification of
each object in clauses 17-26. All object property values are newly created object values. All values that are
built-in function objects are created by performing CreateBuiltinFunction(realmRec, <steps>) where <steps> is the
definition of that function provided by this specification.
An execution context is a specification device that is used to track the runtime evaluation of code by an
ECMAScript implementation. At any point in time, there is at most one execution context that is actually executing code.
This is known as the running execution context. A stack is used to track execution contexts. The running execution
context is always the top element of this stack. A new execution context is created whenever control is transferred from the
executable code associated with the currently running execution context to executable code that is not associated with that
execution context. The newly created execution context is pushed onto the stack and becomes the running execution
context.
An execution context contains whatever implementation specific state is necessary to track the execution progress of its
associated code. Each execution context has at least the state components listed in Table 21.
Table 21 —State Components for All Execution Contexts
Component
Purpose
code evaluation state
Any state needed to perform, suspend, and resume evaluation of the code associated with this execution context.
The Realm from which associated code accesses ECMAScript resources.
Evaluation of code by the running execution context may be suspended at various points defined within this specification.
Once the running execution context has been suspended a different execution context may become the running execution
context and commence evaluating its code. At some latter time a suspended execution context may again become the running
execution context and continue evaluating its code at the point where it had previously been suspended. Transition of the
running execution context status among execution contexts usually occurs in stack-like last-in/first-out manner. However,
some ECMAScript features require non-LIFO transitions of the running execution context.
The value is the Realm component of the running execution context is also called the
current Realm.
Execution contexts for ECMAScript code have the additional state components listed in Table
22.
Table 22 — Additional State Components for ECMAScript Code Execution Contexts
Component
Purpose
LexicalEnvironment
Identifies the Lexical Environment used to resolve identifier references made by code within this execution context.
VariableEnvironment
Identifies the Lexical Environment whose environment record holds bindings created by VariableStatements within this execution context.
The LexicalEnvironment and VariableEnvironment components of an execution context are always Lexical Environments. When
an execution context is created its LexicalEnvironment and VariableEnvironment components initially have the same value.
The value of the VariableEnvironment component never changes while the value of the LexicalEnvironment component may change
during execution of code within an execution context.
Execution contexts representing the evaluation of generator objects have the additional state components listed in Table 23.
Table 23 — Additional State Components for Generator Execution Contexts
Component
Purpose
Generator
The GeneratorObject that this execution context is evaluating.
In most situations only the running execution context (the top of the execution context stack) is directly manipulated by
algorithms within this specification. Hence when the terms “LexicalEnvironment”, and
“VariableEnvironment” are used without qualification they are in reference to those components of the running
execution context.
An execution context is purely a specification mechanism and need not correspond to any particular artefact of an
ECMAScript implementation. It is impossible for ECMAScript code to directly access or observe an execution context.
The ResolveBinding abstract operation is used to determine the binding of name passed as a string value using
the LexicalEnvironment of the running execution
context. During execution of ECMAScript code, ResolveBinding is performed using the following algorithm:
The abstract operation GetThisEnvironment finds the lexical environment that currently supplies the binding of the keyword
this. GetThisEnvironment performs the following steps:
The abstract operation ResolveThisBinding determines the binding of the keyword this using the LexicalEnvironment of the running execution
context. ResolveThisBinding performs the following steps:
Let env be the result of performing the GetThisEnvironment abstract
operation.
Return the result of calling the GetThisBinding concrete method of env.
The abstract operation GetGlobalObject returns the global object used
by the currently running execution context. GetGlobalObject performs the following steps:
A Task is an abstract operation that initiates an ECAMScript computation when no other ECMAScript computation is
currently in progress. A Task abstract operation may be defined to accept an arbitrary set of task parameters.
Execution of a Task can be initiated only when there is no running execution
context and the execution context stack is empty. A PendingTask is a request for
the future execution of a Task. A PendingTask is an internal Record whose fields are specified in Table
24.
Table 24 — PendingTask Record Fields
Field Name
Value
Meaning
[[Task]]
The name of a Task abstract operation
This is the abstract operation that is performed when execution of this PendingTask is initiated. Tasks are abstract operations that use NextTask rather than Return to indicate that they have completed.
The Realm that when for the initial execution context when this Pending Task is initiated.
A Task Queue is a FIFO queue of PendingTask records. Each Task Queue has a name and the full set of available Task Queues
are defined by an ECMAScript implementation. Every ECMAScript implementation has at least the task queues defined in Table 25.
Table 25 — Required Task Queues
Name
Purpose
LoadingTasks
Tasks that validate, load, and evaluate ECMAScript Script and Module code units. See clauses 10 and 15.
PromiseTasks
Tasks that are responses to the settlement of a Promise (see 25.4).
A request for the future execution of a Task is made by enqueueing on a Task Queue a PendingTask record that includes a
Task abstract operation name and any necessary argument values. When there is no running execution context and the execution context stack
is empty, the ECMAScript implementation removes the first PendingTask from a Task Queue and uses the information contained
in it to create an execution context and starts execution of associated Task
abstraction operation.
The PendingTask records from a single Task Queue are always initiated in FIFO order. This specification does not define
the order in which multiple Task Queues are serviced. An ECMAScript implementation may interweave the FIFO evaluation of the
PendingTask records of a Task Queue with the evaluation of the PendingTask records of one or more other Task Queues. An
implementation must define what occurs when there are no running execution context and
all Task Queues are empty.
NOTE Typically an ECMAScript implementation will have its Task Queues are preinitialised with
at least one PendingTask and one of those Tasks will be the first to be executed. An implementation might choose to free
all resources and terminate if the current Task completes and all Task Queues are empty. Alternatively, it might choose
to wait for a some implementation specific agent or mechanism to enqueue new PendingTask requests.
The following abstraction operations are used to create and manage Tasks and Task Queues:
Task abstraction operations must not contain a Return step or a ReturnIfAbrupt step.
The NextTask result operation is equivalent to the following steps:
If result is an abrupt completion, then perform
implementation defined unhandled exception processing.
Let nextQueue be a non-emptry Task Queue chosen in an implementation defined manner. If all Task Queues are
empty, the result is implementation defined.
Let nextPending be the PendingTask record at the front of nextQueue. Remove that record from
nextQueue.
9.1 Ordinary Object Internal Methods and Internal Slots
All ordinary objects have an internal slot called
[[Prototype]]. The value of this internal slot is either
null or an object and is used for implementing inheritance. Data properties of the [[Prototype]] object are
inherited (are visible as properties of the child object) for the purposes of get access, but not for set access. Accessor
properties are inherited for both get access and set access.
Every ordinary object has a Boolean-valued [[Extensible]] internal slot that controls whether or not properties may be
added to the object. If the value of the [[Extensible]] internal
slot is false then additional properties may not be added to the object. In addition, if [[Extensible]] is
false the value of the [[Prototype]] internal slot of
the object may not be modified. Once the value of an object’s [[Extensible]] internal slot has been set to false it may not be
subsequently changed to true.
When the abstract operation OrdinaryDefineOwnProperty is called with
Object O, property keyP, and Property DescriptorDesc the following steps are taken:
When the abstract operation IsCompatiblePropertyDescriptor is called
with Boolean value Extensible, and Property Descriptors Desc, and Current the following steps are taken:
When the abstract operation ValidateAndApplyPropertyDescriptor is
called with Object O, property keyP, Boolean value extensible, and Property Descriptors Desc, and
current the following steps are taken:
This algorithm contains steps that test various fields of the Property DescriptorDesc for specific
values. The fields that are tested in this manner need not actually exist in Desc. If a field is
absent then its value is considered to be false.
NOTE If undefined is passed as the O argument only
validation is performed and no object updates are performed.
If O is not undefined, then create an own data property named P of object O
whose [[Value]], [[Writable]], [[Enumerable]] and [[Configurable]] attribute values are described by
Desc. If the value of an attribute field of Desc is absent, the attribute of the newly created
property is set to its default value.
If O is not undefined, then create an own accessor property named P of object O
whose [[Get]], [[Set]], [[Enumerable]] and [[Configurable]] attribute values are described by Desc.
If the value of an attribute field of Desc is absent, the attribute of the newly created property is
set to its default value.
Return true.
Return true, if every field in Desc is absent.
Return true, if every field in Desc also occurs in current and the value of every field in
Desc is the same value as the corresponding field in current when compared using the SameValue algorithm.
If the [[Configurable]] field of current is false then
Return false, if the [[Configurable]] field of Desc is true.
Return false, if the [[Enumerable]] field of Desc is present and the [[Enumerable]] fields of
current and Desc are the Boolean negation of each other.
If IsGenericDescriptor(Desc) is true, then no further
validation is required.
If O is not undefined, then convert the property named P of object O from a data
property to an accessor property. Preserve the existing values of the converted property’s
[[Configurable]] and [[Enumerable]] attributes and set the rest of the property’s attributes to their
default values.
Else,
If O is not undefined, then convert the property named P of object O from an
accessor property to a data property. Preserve the existing values of the converted property’s
[[Configurable]] and [[Enumerable]] attributes and set the rest of the property’s attributes to their
default values.
If the [[Configurable]] field of current is false, then
Return false, if the [[Set]] field of Desc is present and SameValue(Desc.[[Set]], current.[[Set]]) is false.
Return false, if the [[Get]] field of Desc is present and SameValue(Desc.[[Get]], current.[[Get]]) is false.
If O is not undefined, then
For each attribute field of Desc that is present, set the correspondingly named attribute of the property
named P of object O to the value of the field.
Return true.
NOTE Step 8.b allows any field of Desc to
be different from the corresponding field of current if current’s [[Configurable]] field is true.
This even permits changing the [[Value]] of a property whose [[Writable]] attribute is false.
This is allowed because a true [[Configurable]] attribute would permit an equivalent sequence
of calls where [[Writable]] is first set to true, a new [[Value]] is set, and then
[[Writable]] is set to false.
Let setterResult be the result of calling the [[Call]] internal method of setter providing
Receiver as thisArgument and a new List
containing V as argumentsList.
When the [[Enumerate]] internal method of O is called the following steps are taken:
Return an Iterator object (25.1.2) whose next method iterates over all the
String valued keys of enumerable property keys of O. The mechanics and order of enumerating the properties is
not specified but must conform to the rules specified below.
Enumerated properties do not include properties whose property key is a Symbol. Properties
of the object being enumerated may be deleted during enumeration. If a property that has not yet been visited during
enumeration is deleted, then it will not be visited. If new properties are added to the object being enumerated during
enumeration, the newly added properties are not guaranteed to be visited in the active enumeration. A property name must not
be visited more than once in any enumeration.
Enumerating the properties of an object includes enumerating properties of its prototype, and the prototype of the
prototype, and so on, recursively; but a property of a prototype is not enumerated if it is “shadowed” because
some previous object in the prototype chain has a property with the same name. The values of [[Enumerable]] attributes are
not considered when determining if a property of a prototype object is shadowed by a previous object on the prototype
chain.
The following is an informative algorithm that conforms to these rules
Let obj be O.
Let proto be the result of calling the [[GetPrototypeOf]] internal method of O with no arguments.
The abstract operation ObjectCreate with argument proto (an object or null) is used to specify the runtime
creation of new ordinary objects. The optional argument internalDataList is a List of the names of internal slot names that should be defined as part of the object.
If the list is not provided, an empty List is used. If no arguments
are provided %ObjectPrototype% is used as the value of proto. This abstract operation performs the following
steps:
If internalDataList was not provided, let internalDataList be an empty List.
Let obj be a newly created object with an internal
slot for each name in internalDataList.
Set obj’s essential internal methods to the default ordinary object definitions specified in 9.1.
Set the [[Prototype]] internal slot of obj to
proto.
Set the [[Extensible]] internal slot of obj to
true.
The abstract operation OrdinaryCreateFromConstructor creates an ordinary object whose [[Prototype]] value is retrieved
from a constructor’s prototype property, if it exists. Otherwise the supplied default is used for
[[Prototype]]. The optional internalDataList is a List of
the names of internal slot names that should be defined as
part of the object. If the list is not provided, an empty List is
used. This abstract operation performs the following steps:
Assert: intrinsicDefaultProto is a string value that is this
specification’s name of an intrinsic object. The corresponding object must be an intrinsic that is intended to
be used as the [[Prototype]] value of an object.
ECMAScript function objects encapsulate parameterised ECMAScript code closed over a lexical environment and support the dynamic evaluation of that code. An ECMAScript
function object is an ordinary object and has the same internal slots and (except as noted below) the same internal methods
as other ordinary objects. The code of an ECMAScript function object may be either strict
mode code (10.2.1) or non-strict mode code.
ECMAScript function objects have the additional internal slots listed in Table 26.
ECMAScript function objects whose code is not strict mode code (10.2.1) provide an alternative definition for the [[GetOwnProperty]] internal method. This
alternative prevents the value of strict mode function from being revealed as the value of a function object property named
"caller". The alternative definition exist solely to preclude a non-standard legacy feature of some ECMAScript
implementations from revealing information about strict mode callers. If an implementation does not provide such a feature,
it need not implement this alternative internal method for ECMAScript function objects. ECMAScript function objects are
considered to be ordinary objects even though they may use the alternative definition of [[GetOwnProperty]].
Table 26 -- Internal Slots of ECMAScript Function Objects
The Code Realm in which the function was created and which provides any intrinsic objects that are accessed when evaluating the function.
[[ThisMode]]
(lexical, strict, global)
Defines how this references are interpreted within the formal parameters and code body of the function. lexical means that this refers to the this value of a lexically enclosing function. strict means that the this value is used exactly as provided by an invocation of the function. global means that a this value of undefined is interpreted as a reference to the global object.
[[Strict]]
Boolean
true if this is a strict mode function, false this is not a strict mode function.
[[NeedsSuper]]
Boolean
true if this functions uses super.
[[HomeObject]]
Object
If the function uses super, this is the object whose [[GetPrototypeOf]] provides the object where super property lookups begin.
[[MethodName]]
String or Symbol
If the function uses super, this is the property keys that is used for unqualified references to super.
All ECMAScript function objects have the [[Call]] internal method defined here. ECMAScript functions that are also
constructors in addition have the [[Construct]] internal method. ECMAScript function objects whose code is not strict mode code have the [[Get]] and [[GetOwnProperty]] internal methods defined here.
If P is "caller" and v.[[Value]] is a strict mode Function object, then
Set v.[[Value]] to null.
Return v.
If an implementation does not provide a built-in caller property for non-strict ECMAScript function objects
then it must not use this definition. Instead the ordinary object [[GetOwnProperty]] internal method is used.
The abstract operation FunctionAllocate requires the two arguments functionPrototype and strict. It also accepts one optional argument, functionKind.
FunctionAllocate performs the following steps:
Assert: If functionKind is present, its value is either
"normal" or "generator".
If functionKind is not present, then let functionKind be "normal".
Let F be a newly created ECMAScript function object with the
internal slots listed in Table 26. All of those internal slots are initialised to
undefined.
Set F’s essential internal methods except for [[GetOwnProperty]] to the default ordinary object
definitions specified in 9.1.
If strict is true, set F’s [[GetOwnProperty]] internal method to the default ordinary
object definitions specified in 9.1.
Else, set F’s [[GetOwnProperty]] internal method to the definitions specified in 9.2.2.
Set F’s [[Call]] internal method to the definition specified in 9.2.1.
NOTE 2 When calleeContext is removed from the
execution context stack it must not be destroyed because it may have been suspended and retained by a generator object for later resumption.
The abstract operation FunctionInitialise requires the arguments: a function object F, kind which
is one of (Normal, Method, Arrow), a parameter list production specified by ParameterList, a body
production specified by Body, a Lexical Environment
specified by Scope. FunctionInitialise performs the following
steps:
Let len be the ExpectedArgumentCount of ParameterList.
Let strict be the vale of F’s [[Strict]] internal slot.
Let status be the result of DefinePropertyOrThrow(F,
"length", PropertyDescriptor{[[Value]]: len, [[Writable]]: false, [[Enumerable]]:
false, [[Configurable]]: true}).
The abstract operation FunctionCreate requires the arguments: kind which is one of (Normal, Method, Arrow), a
parameter list production specified by ParameterList, a body production specified by Body, a Lexical Environment specified by Scope, a Boolean flag Strict, and optionally, an object functionPrototype. FunctionCreate performs the following steps:
If the functionPrototype argument was not passed, then
Let functionPrototype be the intrinsic object %FunctionPrototype%.
Let F be the result of performing FunctionAllocate with arguments
functionPrototype and Strict.
Return the result of performing FunctionInitialise with passing F,
kind, ParameterList, Body, and Scope.
The abstract operation GeneratorFunctionCreate requires the arguments: kind which is one of (Normal, Method,
Arrow), a parameter list production specified by ParameterList, a body production specified by Body, a Lexical Environment specified by Scope, a Boolean flag Strict, and optionally, an object
functionPrototype. GeneratorFunctionCreate performs the following steps:
If the functionPrototype argument was not passed, then
Let functionPrototype be the intrinsic object %Generator%.
Let F be the result of performing FunctionAllocate with arguments
functionPrototype, Strict, and "generator".
Return the result of performing FunctionInitialise with passing F,
kind, ParameterList, Body, and Scope.
The abstract operation AddRestrictedFunctionProperties is called with a function object F as its argument. It
performs the following steps:
Let thrower be the %ThrowTypeError% intrinsic function
Object.
Let status be the result of DefinePropertyOrThrow(F,
"caller", PropertyDescriptor {[[Get]]: thrower, [[Set]]: thrower, [[Enumerable]]:
false, [[Configurable]]: false}).
The abstract operation MakeConstructor requires a Function argument F and optionally, a Boolean
writablePrototype and an object prototype. If prototype is provided it is assumed to
already contain, if needed, a "constructor" property whose value is F. This operation converts
F into a constructor by performing the following steps:
Let prototype be the result of ObjectCreate(%ObjectPrototype%).
If the writablePrototype argument was not provided, then
Let writablePrototype be true.
Set F’s essential internal method [[Construct]] to the definition specified in 9.2.1.
If installNeeded, then
Let status be the result of DefinePropertyOrThrow(prototype, "constructor",
PropertyDescriptor{[[Value]]: F, [[Writable]]: writablePrototype, [[Enumerable]]: false,
[[Configurable]]: writablePrototype }).
Let status be the result of DefinePropertyOrThrow(F,
"prototype", and PropertyDescriptor{[[Value]]: prototype, [[Writable]]: writablePrototype,
[[Enumerable]]: false, [[Configurable]]: false}.
The abstract operation SetFunctionName requires a Function argument F, a String or Symbol argument
name and optionally a String argument prefix. This operation adds a name property to
F by performing the following steps:
Let description be the values of name’s [[Description]].
If description is undefined, then let name be the empty String.
Else, let name be the concatenation of "[", description, and "]".
If name is not the empty string and prefix was passed, then let name be the concatenation of
prefix, Unicode code point U+0020 (Space) , and name.
Call the [[DefineOwnProperty]] internal method of F with arguments "name" and
PropertyDescriptor{[[Value]]: name, [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]:
true}.
Assert: Defining the name property will always succeed.
The abstract operation Clone is called with a function object function, an object newHome, and a property keynewName as its argument. It performs the following steps:
Assert: Type(newName) one
of Undefined, String, or Symbol.
Let new be a new ECMAScript function object that has all of the
same internal methods and internal slots as function.
Set the value of each of new’s internal slots, except for [[HomeObject]] and [[MethodName]] to the value
of function’s corresponding internal
slot.
If the value of function’s [[NeedsSuper]] internal slot is true, then
Set the value of new’s [[HomeObject]] internal
slot to newHome.
If newName is not undefined, then
Set the value of new’s [[MethodName]] internal slot to newName.
Else,
Set the value of new’s [[MethodName]] internal slot to the value of functions’s
[[MethodName]] internal slot.
Return new.
NOTE The purpose of this abstract operation is to create a new function object that is
identical to the argument object in all aways except for its identity and the value of its [[HomeObject]] internal slot.
This version reflects the concensus as of the Sept. 2012 TC39 meeting. A concensus for
a new semantics was reach at the Sept. 2013 meeting. This specification has not yet been update.
NOTE When an execution context is established for
evaluating function code a new Declarative Environment Record is
created and bindings for each formal parameter, and each function level variable, constant, or function declarated in the
function are instantiated in the environment record. Formal parameters and functions are initialised as part of this
process. All other bindings are initialised during execution of the function code.
Function Declaration Instantiation is performed as follows using arguments func,argumentsList, and
env. func is the function object that for which the execution
context is being established. env is the declarative
environment record in which bindings are to be created.
Let code be the value of the [[Code]] internal
slot of func.
Let strict be the value of the [[Strict]] internal
slot of func.
Let formals be the value of the [[FormalParameters]] internal slot of func.
Let parameterNames be the BoundNames of formals.
Let varDeclarations be the VarScopedDeclarations of code.
Let alreadyDeclared be the result of calling env’s HasBinding concrete method passing
paramName as the argument.
NOTE Duplicate parameter names can only occur in non-strict functions. Parameter names that are the same as
function declaration names do not get initialised to undefined.
If alreadyDeclared is false, then
If paramName is "arguments", then let argumentsObjectNeeded be false.
Let status be the result of calling env’s CreateMutableBinding concrete method passing
paramName as the argument.
Let lexDeclarations be the LexicalDeclarations of code.
For each element d in lexDeclarations do
NOTE A lexically declared name cannot be the same as a function declaration, formal parameter, or a var
name. Lexically declarated names are only instantiated here but not initialised.
For each element dn of the BoundNames of d do
If IsConstantDeclaration of d is true, then
Call env’s CreateImmutableBinding concrete method passing dn as the argument.
Else,
Let status be the result of calling env’s CreateMutableBinding concrete method passing
dn and false as the arguments.
NOTE Function declaration are initialised prior to parameter initialisation so that default value expressions may
reference them. "arguments" is not initialised until after parameter initialisation.
Let formalStatus be the result of performing IteratorBindingInitialisation for formals with CreateListIterator(argumentsList) and undefined as arguments.
The built-in function objects defined in this specification may be implemented as either ECMAScript function objects (9.1.14) whose behaviour is provided using ECMAScript code or as implementation
provided exotic function objects whose behaviour is provided in some other manner. In either case, the effect of calling
such functions must conform to their specifications.
If a built-in function object is implemented as an exotic object it must have the ordinary object behaviour specified in
9.1 except [[GetOwnProperty]] which must be as
specified in 9.1.14. All such exotic function objects also have
[[Prototype]] and [[Extensible]] internal slots.
Unless otherwise specified every built-in function object initially has the %FunctionPrototype% object (19.2.3) as the initial value of its [[Prototype]] internal slot.
The behaviour specified for each built-in function via algorithm steps or other means is the specification of the
[[Call]] behaviour for that function with the [[Call]] thisArgument providing the this
value and the [[Call]] argumentsList providing the named parameters for each built-in function. If the built-in
function is implemented as an ECMAScript function object then this specified
behaviour must be implemented by the ECMAScript code that is the body of the function. Built-in functions that are
ECMAScript function objects must be strict mode functions.
Built-in function objects that are not identified as constructors do not implement the [[Construct]] internal method
unless otherwise specified in the description of a particular function. When a built-in constructor is called as part of a
new expression the argumentsList parameter of the invoked [[Construct]] internal method provides the
values for the built-in constructor’s named parameters.
Built-in functions that are not constructors do not have a prototype property unless otherwise specified in
the description of a particular function.
If a built-in function object is not implemented as an ECMAScript function it must have a [[Realm]] internal slot and a [[Call]] internal method that conforms to the
following definition:
The [[Call]] internal method for a built-in function object F is called with parameters
thisArgument and argumentsList, a List of ECMAScript language values. The following steps are taken:
NOTE 1 When calleeContext is removed from the
execution context stack it must not be destroyed because it may have been suspended and retained by a generator object for later resumption.
Assert: steps is either a set of algorithm steps or other definition
of a functions behaviour provided in this specification.
Let func be a new built-in function object that when called performs the action described by steps. The
[[Realm]] internal slot of func is step to
realm.
9.4 Built-in Exotic Object Internal Methods and Data Fields
This specification defines several kinds of built-in exotic objects. These objects generally behave similar to ordinary
objects except for a few specific situations. The following exotic objects use the ordinary object internal methods except
where it is explicitly specified otherwise below:
A bound function is an exotic object that wrappers another function object. A bound function is callable (it
has a [[Call]] internal method and may have a [[Construct]] internal method). Calling a bound function generally results
in a call of its wrappered function.
Bound function objects do not have the internal slots of ECMAScript function objects defined in Table 26. Instead they have the internal slots defined in Table 27.
Table 27 -- Internal Slots of Exotic Bound Function Objects
Internal Slot
Type
Description
[[BoundTargetFunction]]
Callable Object
The wrappered function object.
[[BoundThis]]
Any
The value that is always passed as the this value when calling the wrappered function.
A list of values that whose elements are used as the first arguments to any call to the wrappered function.
Unlike ECMAScript function objects, bound function objects do not use alternative definitions of the [[Get]] and
[[GetOwnProperty]] internal methods. Bound function objects provide all of the essential internal methods as specified in
9.1. However, they use the following definitions
for the essential internal methods of function objects.
When the [[Call]] internal method of an exotic bound function object,
F, which was created using the bind function is called with parameters thisArgument and
argumentsList, a List of ECMAScript language values, the following steps are taken:
Let args be a new list containing the same values as the list boundArgs in the same order followed by
the same values as the list argumentsList in the same order.
Return the result of calling the [[Call]] internal method of target providing boundThis as
thisArgument and providing args as argumentsList.
When the [[Construct]] internal method of an exotic bound function
object, F that was created using the bind function is called with a list of arguments ExtraArgs, the following steps are taken:
Let args be a new list containing the same values as the list boundArgs in the same order followed by
the same values as the list ExtraArgs in the same order.
Return the result of calling the [[Construct]] internal method of target providing args as the
arguments.
The abstract operation BoundFunctionCreate with arguments targetFunction, boundThis and
boundArgs is used to specify the creation of new Bound
Function exotic objects. It performs the following steps:
Let proto be the intrinsic %FunctionPrototype%.
Let obj be a newly created object.
Set obj’s essential internal methods to the default ordinary object definitions specified in 9.1.
Set the [[Call]] internal method of obj as described in 9.4.1.1.
If targetFunction has a [[Construct]] internal method, then
Set the [[Construct]] internal method of obj as described in 9.4.1.2.
Set the [[Prototype]] internal slot of obj to
proto.
Set the [[Extensible]] internal slot of obj to
true.
An Array object is an exotic object that gives special treatment to a certain class of property names. A
property name P (in the form of a String value) is an array index if and only if ToString(ToUint32(P)) is equal to P and ToUint32(P) is not equal to 232−1. A property whose property name is an array index is also called an element.
Every Array object has a length property whose value is always a nonnegative integer less than 232. The value of the length property is numerically
greater than the name of every property whose name is an array index; whenever a property of an Array object is created or
changed, other properties are adjusted as necessary to maintain this invariant. Specifically, whenever a property is added
whose name is an array index, the length property is changed, if necessary, to be one more than the numeric
value of that array index; and whenever the length property is changed, every property whose name is an array
index whose value is not smaller than the new length is automatically deleted. This constraint applies only to own
properties of an Array object and is unaffected by length or array index properties that may be inherited
from its prototypes.
Exotic Array objects have the same internal slots as ordinary objects. They also have an [[ArrayInitialisationState]]
internal slot.
Exotic Array objects always have a non-configurable property named "length".
Exotic Array objects provide an alternative definition for the [[DefineOwnProperty]] internal method. Except for that
internal method, exotic Array objects provide all of the other essential internal methods as specified in 9.1.
When the [[DefineOwnProperty]] internal method of an exotic Array object A is called with property keyP, and Property
DescriptorDesc the following steps are taken:
Return the result of calling ArraySetLength with arguments A, and
Desc.
Else if P is an array index, then
Let oldLenDesc be the result of calling the [[GetOwnProperty]] internal method of A passing
"length" as the argument. The result will never be
undefined or an accessor descriptor because Array objects are created with a length data property that
cannot be deleted or reconfigured.
The abstract operation ArrayCreate with argument length (a positive integer or undefined) and optional argument proto is used to specify the creation of new exotic Array
objects. It performs the following steps:
If the proto argument was not passed, then let proto be the intrinsic object %ArrayPrototype%.
Set the [[ArrayInitialisationState]] internal slot
of A to true.
Else
Set the [[ArrayInitialisationState]] internal slot
of A to false.
Let length be 0.
If length>232-1, then throw a RangeError exception.
Call OrdinaryDefineOwnProperty with arguments A,
"length" and PropertyDescriptor{[[Value]]: length, [[Writable]]: true, [[Enumerable]]:
false, [[Configurable]]: false}.
If newLen is not equal to ToNumber( Desc.[[Value]]), throw a
RangeError exception.
Set newLenDesc.[[Value]] to newLen.
Let oldLenDesc be the result of calling the [[GetOwnProperty]] internal method of A passing "length" as the argument. The result will never be undefined or an
accessor descriptor because Array objects are created with a length data property that cannot be deleted or
reconfigured.
Let oldLen be oldLenDesc.[[Value]].
If newLen ≥oldLen, then
Return the result of calling OrdinaryDefineOwnProperty passing
A, "length", and newLenDesc as arguments.
If oldLenDesc.[[Writable]] is false, then return false.
If newLenDesc.[[Writable]] is absent or has the value true, let newWritable be
true.
Else,
Need to defer setting the [[Writable]] attribute to false in case any elements cannot be deleted.
Let newWritable be false.
Set newLenDesc.[[Writable]] to true.
Let succeeded be the result of calling OrdinaryDefineOwnProperty
passing A, "length", and newLenDesc as
arguments.
A String object is an exotic object that encapsulates a String value and exposes virtual integer indexed data
properties corresponding to the individual code unit elements of the string value. Exotic String objects always have a
data property named "length" whose value is the number of code unit
elements in the encapsulated String value. Both the code unit data properties and the "length" property are non-writable and non-configurable.
Exotic String objects have the same internal slots as ordinary objects. They also have a [[StringData]] internal
slot.
Exotic String objects provide alternative definitions for the following internal methods. All of the other exotic
String object essential internal methods that are not defined below are as specified in 9.1.
If SameValue(absIntIndex, P) is false return
undefined.
Let str be the String value of the [[StringData]] internal slot of S, if the value of [[StringData]]
is undefined the empty string is used as its value.
Let len be the number of elements in str.
If len ≤ index, return undefined.
Let resultStr be a String value of length 1, containing one code unit from str, specifically the code
unit at position index, where the first (leftmost) element in str is considered to be at position 0,
the next one at position 1, and so on.
When the [[DefineOwnProperty]] internal method of an exotic String object O is called with property keyP, and Property
DescriptorDesc the following steps are taken:
Let current be the result of calling the [[GetOwnProperty]] internal method of O with argument
P.
Let extensible be the value of the [[Extensible]] internal slot of O.
NOTE This algorithm differs from the ordinary object OrdinaryDefineOwnProperty abstract operation algorithm only in invocation of
[[GetOwnProperty]] in step 1.
The abstract operation StringCreate with argument prototype is used to specify the creation of new exotic
String objects. It performs the following steps:
Most of the text in this section is copied from the ES5 spec. and still needs to be
updated to work within the context of the ES6 specification.
An arguments object is an exotic object whose array index properties map to the formal parameters bindings of an
invocation of a non-strict function.
Exotic arguments objects have the same internal slots as ordinary objects. They also have a [[ParameterMap]] internal
slot.
Exotic arguments objects provide alternative definitions for the following internal methods. All of the other exotic
arguments object essential internal methods that are not defined below are as specified in 9.1.
When function code is evaluated, an arguments object is created unless (as specified in 9.2.14) the identifier arguments occurs as an Identifier in the function’s FormalParameters or occurs as the BindingIdentifier of a FunctionDeclaration contained in the outermost StatementList of the function code.
The abstract operation InstantiateArgumentsObject called with an
argument args performs the following steps:
Let len be the number of elements in args.
Let obj be the result of the abstract operation ObjectCreate with the
intrinsic object %ObjectPrototype% as its argument.
Call the [[DefineOwnProperty]] internal method on obj passing "length" and the PropertyDescriptor{[[Value]]: len, [[Writable]]: true,
[[Enumerable]]: false, [[Configurable]]: true} as arguments.
Let indx = len - 1.
Repeat while indx ≥ 0,
Let val be the element of args at 0-origined list position indx.
Call the [[DefineOwnProperty]] internal method on obj passing ToString(indx) and the PropertyDescriptor{[[Value]]: val, [[Writable]]:
true, [[Enumerable]]: true, [[Configurable]]: true} as arguments.
Let indx = indx - 1
Return obj
The abstract operation CompleteStrictArgumentsObject is called with
argument obj which must have been previously created by the abstract operation InstantiateArgumentsObject. The following steps are performed:
The abstract operation CompleteMappedArgumentsObject is called with
object obj, object func, grammar production formals, and environment record
env. obj must have been previously created by the abstract operation InstantiateArgumentsObject.The following steps are performed:
Let numberOfNonRestFormals be NumberOfParameters of formals.
Let map be the result of the abstract operation ObjectCreate with the
intrinsic object %ObjectPrototype% as its argument.
Let indx = len - 1.
Repeat while indx ≥ 0,
If indx is less than the numberOfNonRestFormals, then
Let param be getParameter of formals with argument indx.
If param is a BindingIdentifier, then
Let name be the sole element of BoundNames of param.
If name is not an element of mappedNames, then
Add name as an element of the list mappedNames.
Let g be the result of calling the MakeArgGetter abstract operation with arguments
name and env.
Let p be the result of calling the MakeArgSetter abstract operation with arguments
name and env.
Call the [[DefineOwnProperty]] internal method of map passing ToString(indx) and the PropertyDescriptor{[[Set]]: p,
[[Get]]: g, [[Configurable]]: true} as arguments.
Let indx = indx - 1
If mappedNames is not empty, then
Set the [[ParameterMap]] internal slot of
obj to map.
Set the [[Get]], [[GetOwnProperty]], [[DefineOwnProperty]], and [[Delete]] internal methods of obj to the
definitions provided below.
Call the [[DefineOwnProperty]] internal method on obj passing "callee" and the
PropertyDescriptor{[[Value]]: func, [[Writable]]: true, [[Enumerable]]: false,
[[Configurable]]: true} as arguments.
Return obj
The abstract operation MakeArgGetter called with String
name and environment record env creates a function object that when executed returns the value bound
for name in env. It performs the following steps:
Let bodyText be the result of concatenating the Strings "return ", name, and
";".
Let body be the result of parsing bodyText using FunctionBody as the goal symbol.
Let parameters be a FormalParameters:[empty] production.
Return the result of calling the abstract operation FunctionCreate with arguments
Normal, parameters , body , env , and true
.
The abstract operation MakeArgSetter called with String
name and environment record env creates a function object that when executed sets the value bound
for name in env. It performs the following steps:
Let paramText be the String name concatenated with the String "_arg".
Let parameters be the result of parsing paramText using FormalParameters as the goal
symbol.
Let bodyText be the String "<name> = <param>;" with <name> replaced by the value of name and
<param> replaced by the value of paramText.
Let body be the result of parsing bodyText using FunctionBody as the goal symbol.
Return the result of calling the abstract operation FunctionCreate with arguments
Normal , parameters , body for FunctionBody,
env , and true .
The [[Get]] internal method of an arguments object for a non-strict mode function with formal parameters when called
with a property name P performs the following steps:
Let args be the arguments object.
Let map be the value of the [[ParameterMap]] internal slot of the arguments object.
Let isMapped be the result of calling the [[GetOwnProperty]] internal method of map passing P
as the argument.
If the value of isMapped is undefined, then
Let v be the result of calling the default ordinary object [[Get]] internal method (9.1.8) on args
passing P and args as the arguments.
If P is "caller" and v is a strict mode Function object, throw a TypeError
exception.
Return v.
Else map contains a formal parameter mapping for P,
The [[GetOwnProperty]] internal method of an arguments object for a non-strict mode function with formal parameters
when called with a property name P performs the following steps:
Let desc be the result of calling the default [[GetOwnProperty]] internal method for ordinary objects (9.1.5) on the arguments object
passing P as the argument.
If desc is undefined then return desc.
Let map be the value of the [[ParameterMap]] internal slot of the arguments object.
Let isMapped be the result of calling the [[GetOwnProperty]] internal method of map passing P
as the argument.
If the value of isMapped is not undefined, then
Set desc.[[Value]] to the result of calling Get(map, P).
Return desc.
The [[DefineOwnProperty]] internal method of an arguments object for a non-strict mode function with formal parameters
when called with a property name P and Property
DescriptorDesc performs the following steps:
Let map be the value of the [[ParameterMap]] internal slot of the arguments object.
Let isMapped be the result of calling the [[GetOwnProperty]] internal method of map passing P
as the argument.
Let allowed be the result of calling the default [[DefineOwnProperty]] internal method for ordinary objects
(9.1.6) on the
arguments object passing P and Desc as the arguments.
Call the [[Delete]] internal method of map passing P as the argument.
Else
If Desc.[[Value]] is present, then
Let putStatus be the result of Put(map, P,
Desc.[[Value]], false).
Assert: putStatus is true because formal
parameters mapped by argument objects are always writable.
If Desc.[[Writable]] is present and its value is false, then
Call the [[Delete]] internal method of map passing P as the argument.
Return true.
The [[Delete]] internal method of an arguments object for a non-strict mode function with formal parameters when called
with a property keyP performs the following steps:
Let map be the value of the [[ParameterMap]] internal slot of the arguments object.
Let isMapped be the result of calling the [[GetOwnProperty]] internal method of map passing P
as the argument.
Let result be the result of calling the default [[Delete]] internal method for ordinary objects (9.1.10) on the arguments object passing
P as the argument.
If result is true and the value of isMapped is not undefined, then
Call the [[Delete]] internal method of map passing P as the argument.
Return result.
NOTE 1 For non-strict mode functions the integer indexed data properties of an arguments
object whose numeric name values are less than the number of formal parameters of the corresponding function object
initially share their values with the corresponding argument bindings in the function’s execution context. This means that changing the property changes the corresponding
value of the argument binding and vice-versa. This correspondence is broken if such a property is deleted and then
redefined or if the property is changed into an accessor property. For strict mode functions, the values of the
arguments object’s properties are simply a copy of the arguments passed to the function and there is no dynamic
linkage between the property values and the formal parameter values.
NOTE 2 The ParameterMap object and its property values are used as a device for specifying
the arguments object correspondence to argument bindings. The ParameterMap object and the objects that are the values of
its properties are not directly accessible from ECMAScript code. An ECMAScript implementation does not need to actually
create or use such objects to implement the specified semantics.
NOTE 3 Arguments objects for strict mode functions define non-configurable accessor
properties named "caller" and "callee" which throw a TypeError exception on access. The
"callee" property has a more specific meaning for non-strict mode functions and a "caller"
property has historically been provided as an implementation-defined extension by some ECMAScript implementations. The
strict mode definition of these properties exists to ensure that neither of them is defined in any other manner by
conforming ECMAScript implementations.
An Integer Indexed object is an exotic object that performs special handling of integer property keys.
Integer Indexed exotic objects have the same internal slots as ordinary objects additionally [[ViewedArrayBuffer]],
[[ArrayLength]], [[ByteOffset]], and [[TypedArrayName]] internal slots.
Integer Indexed Exotic objects provide alternative definitions for the following internal methods. All of the other
Integer Indexed exotic object essential internal methods that are not defined below are as specified in 9.1.
When the [[DefineOwnProperty]] internal method of an Integer Indexed exotic object O is called with property keyP, and Property
DescriptorDesc the following steps are taken:
When the [[Get]] internal method of an Integer Indexed exotic object O is called with property keyP and ECMAScript language
valueReceiver the following steps are taken:
When the [[Set]] internal method of an Integer Indexed exotic object O is called with property keyP, value V, and ECMAScript language valueReceiver, the following steps
are taken:
The abstract operation IntegerIndexedObjectCreate with argument prototype is used to specify the creation of
new Integer Indexed exotic objects. It performs the following steps:
Let A be a newly created object.
Set A’s essential internal methods to the default ordinary object definitions specified in 9.1.
Set the [[GetOwnProperty]] internal method of A as specified in 9.4.5.1.
Set the [[DefineOwnProperty]] internal method of A as specified in 9.4.5.2.
Set the [[Get]] internal method of A as specified in 9.4.5.3.
Set the [[Set]] internal method of A as specified in 9.4.5.4.
Set the [[Enumerate]] internal method of A as specified in 9.4.5.5.
Set the [[OwnPropertyKeys]] internal method of A as specified in 9.4.5.6.
Set the [[Prototype]] internal slot of A to
prototype.
9.5 Proxy Object Internal Methods and Internal Slots
A proxy object is an exotic object whose essential internal methods are partially implemented using ECMAScript code.
Every proxy objects has an internal slot called
[[ProxyHandler]]. The value of [[ProxyHandler]] is always an object, called the proxy’s handler object.
Methods of a handler object may be used to augment the implementation for one or more of the proxy object’s internal
methods. Every proxy object also has an internal slot called
[[ProxyTarget]] whose value is either an object or the null value. This object is called the proxy’s target
object.
When a handler method is called to provide the implementation of a proxy object internal method, the handler method is
passed the proxy’s target object as a parameter. A proxy’s handler object does not necessarily have a method
corresponding to every essential internal method. Invoking an internal method on the proxy results in the invocation of the
corresponding internal method on the proxy’s target object if the handler object does not have a method corresponding
to the internal trap.
The [[ProxyHandler]] and [[ProxyTarget]] internal slots of a proxy object are always initialised when the object is
created and typically may not be modified. Some proxy objects are created in a manner that permits them to be subsequently
revoked. When a proxy is revoked, its [[ProxyHander]] and [[ProxyTarget]] internal slots are set to null
causing subsequent invocations of internal methods on that proxy obeject to throw a TypeError
exception.
Because proxy permit arbitrary ECMAScript code to be used to in the implementation of internal methods, it is possible to
define a proxy object whose handler methods violates the invariants defined in 6.1.7.3. Some of the internal method invariants defined in 6.1.7.3 are essential integrity invariants. These invariants
are explicitly enforced by the proxy internal methods specified in this section. An ECMAScript implementation must be robust
in the presence of all possible invariant violations.
If SameValue(handlerProto, targetProto) is false, then throw a
TypeError exception.
Return handlerProto.
NOTE [[GetPrototypeOf]] for proxy objects enforces the following invariant:
The result of [[GetPrototypeOf]] must be either an Object or null.
If the target object is not extensible, [[GetPrototypeOf]] applied to the proxy object must return the same
value as [[GetPrototypeOf] applied to the proxy object’s target object.
If SameValue(booleanTrapResult, targetResult) is false, then throw a
TypeError exception.
Return booleanTrapResult.
NOTE [[IsExtensible]] for proxy objects enforces the following invariant:
[[IsExtensible]] applied to the proxy object must return the same value as [[IsExtensible]] applied to the proxy
object’s target object with the same argument.
If valid is false, then throw a TypeError exception.
If resultDesc.[[Configurable]] is false, then
If targetDesc is undefined or targetDesc.[[Configurable]] is true, then
Throw a TypeError exception.
Return resultDesc.
NOTE [[GetOwnProperty]] for proxy objects enforces the following invariants:
The result of [[GetOwnProperty]] must be either an Object or undefined.
A property cannot be reported as non-existent, if it exists as a non-configurable own property of the target
object.
A property cannot be reported as non-existent, if it exists as an own property of the target object and the target
object is not extensible.
A property cannot be reported as existent, if it does not exists as an own property of the target object and the
target object is not extensible.
A property cannot be reported as non-configurable, if it does not exists as an own property of the target object or
if it exists as a configurable own property of the target object.
The result of [[GetOwnProperty]] can be applied to the target object using [[DefineOwnProperty]] and will not
throw an exception.
When the [[DefineOwnProperty]] internal method of an exotic Proxy object O is called with property keyP and Property
DescriptorDesc, the following steps are taken:
NOTE If Desc was originally generated from an object using ToPropertyDescriptor, then descObj will be that original object.
Let trapResult be the result of calling the [[Call]] internal method of trap with handler as the
this value and a new List containing target,
P, and descObj.
If settingConfigFalse is true and targetDesc.[[Configurable]] is true, then throw a
TypeError exception.
Return true.
NOTE [[DefineOwnProperty]] for proxy objects enforces the following invariants:
A property cannot be added, if the target object is not extensible.
A property cannot be added as or modified to be non-configurable, if it does not exists as a non-configurable own
property of the target object.
A property may not be non-configurable, if is corresponding configurable property of the target object exists.
If a property has a corresponding target object property then apply the Property Descriptor of the property to the target object using
[[DefineOwnProperty]] will not throw an exception.
When the [[Get]] internal method of an exotic Proxy object O is called with property keyP and ECMAScript language
valueReceiver the following steps are taken:
Return the result of calling the [[Get]] internal method of target with arguments P and
Receiver.
Let trapResult be the result of calling the [[Call]] internal method of trap with handler as the
this value and a new List containing target,
P, and Receiver.
If IsDataDescriptor(targetDesc) and targetDesc.[[Configurable]]
is false and targetDesc.[[Writable]] is false, then
If SameValue(trapResult, targetDesc.[[Value]]) is false,
then throw a TypeError exception.
If IsAccessorDescriptor(targetDesc) and
targetDesc.[[Configurable]] is false and targetDesc.[[Get]] is undefined, then
If trapResult is not undefined, then throw a TypeError exception.
Return trapResult.
NOTE [[Get]] for proxy objects enforces the following invariants:
The value reported for a property must be the same as the value of the corresponding target object property if the
target object property is a non-writable, non-configurable data property.
The value reported for a property must be undefined if the corresponding corresponding
target object property is non-configurable accessor property that has undefined as its
[[Get]] attribute.
When the [[Set]] internal method of an exotic Proxy object O is called with property keyP, value V, and ECMAScript language valueReceiver, the following steps
are taken:
Return the result of calling the [[Set]] internal method of target with arguments P, V, and
Receiver.
Let trapResult be the result of calling the [[Call]] internal method of trap with handler as the
this value and a new List containing target,
P, V, and Receiver.
If IsDataDescriptor(targetDesc) and targetDesc.[[Configurable]]
is false and targetDesc.[[Writable]] is false, then
If SameValue(V, targetDesc.[[Value]]) is false, then throw a
TypeError exception.
If IsAccessorDescriptor(targetDesc) and
targetDesc.[[Configurable]] is false, then
If targetDesc.[[Set]] is undefined, then throw a TypeError exception.
Return true.
NOTE [[Set]] for proxy objects enforces the following invariants:
Cannnot change the value of a property to be different from the value of the corresponding target object property
if the corresponding target object property is a non-writable, non-configurable data property.
Cannot set the value of a property if the corresponding corresponding target object property is a non-configurable
accessor property that has undefined as its [[Set]] attribute.
The [[Call]] internal method of an exotic Proxy object O is called with parameters thisArgument and
argumentsList, a List of ECMAScript language values. The following steps are taken:
Let handler be the value of the [[ProxyHandler]] internal slot of O.
If handler is null, then throw a TypeError exception.
Let target be the value of the [[ProxyTarget]] internal slot of O.
Let trap be the result of GetMethod(handler, "apply").
Return the result of calling the [[Call]] internal method of trap with handler as the this value
and a new List containing target, thisArgument,
and argArray.
NOTE A Proxy exotic object only has a [[Call]] internal method if the initial value of its
[[ProxyTarget]] internal slot is an object that has a
[[Call]] internal method.
The [[Construct]] internal method of an exotic Proxy object O is called with a single parameter
argumentsList which is a possibly empty List of ECMAScript language values. The following steps are taken:
Let handler be the value of the [[ProxyHandler]] internal slot of O.
If handler is null, then throw a TypeError exception.
Let target be the value of the [[ProxyTarget]] internal slot of O.
Let trap be the result of GetMethod(handler,
"construct").
If Type(newObj) is not Object, then throw a
TypeError exception.
Return newObj.
NOTE 1 A Proxy exotic object only has a [[Construct]] internal method if the initial value of
its [[ProxyTarget]] internal slot is an object that has a
[[Construct]] internal method.
NOTE 2 [[Construct]]] for proxy objects enforces the following invariants:
The abstract operation ProxyCreate with arguments target and handler is used to specify the
creation of new Proxy exotic objects. It performs the following steps:
If Type(target) is not Object, throw a TypeError
Exception.
If Type(handler) is not Object, throw a TypeError
Exception.
Let P be a newly created object.
Set P’s essential internal methods to the definitions specified in 9.5.
The ECMAScript code is expressed using Unicode, version 5.1 or later. ECMAScript source text is a sequence of code
points. All Unicode code point values from U+0000 to U+10FFFF, including surrogate code points, may occur in source text
where permitted by the ECMAScript grammars. The actual encodings used to store and interchange ECMAScript source text is not
relevant to this specification. Regardless of the external source text encoding, a conforming ECMAScript implementation
processes the source text as if it was an equivalent sequence of SourceCharacter values. Each SourceCharacter being a Unicode code point. Conforming ECMAScript implementations are not required to
perform any normalisation of text, or behave as though they were performing normalisation of text.
The components of a combining character sequence are treated as individual Unicode code points even though a user might
think of the whole sequence as a single character.
NOTE In string literals, regular expression literals,template literals and identifiers, any
Unicode code point may also be expressed using Unicode escape sequences that explicitly express a code point’s
numeric value. Within a comment, such an escape sequence is effectively ignored as part of the comment.
ECMAScript differs from the Java programming language in the behaviour of Unicode escape sequences. In a Java program,
if the Unicode escape sequence \u000A, for example, occurs within a single-line comment, it is interpreted as
a line terminator (Unicode character 000A is line feed) and therefore the next character is not part of the
comment. Similarly, if the Unicode escape sequence \u000A occurs within a string literal in a Java program,
it is likewise interpreted as a line terminator, which is not allowed within a string literal—one must write
\n instead of \u000A to cause a line feed to be part of the string value of a string literal. In
an ECMAScript program, a Unicode escape sequence occurring within a comment is never interpreted and therefore cannot
contribute to termination of the comment. Similarly, a Unicode escape sequence occurring within a string literal in an
ECMAScript program always contributes a Unicode code unit or code point (depending upon the first of the escape) to the
literal and is never interpreted as a line terminator or as a quote mark that might terminate the string literal.
Global code is source text that is treated as an ECMAScript Script. The global code of a particular
Script does not include any source text that is parsed as part of a FunctionBody, GeneratorBody,
ConciseBody, ClassBody, or ModuleBody.
Eval code is the source text supplied to the built-in eval function. More precisely, if the
parameter to the built-in eval function is a String, it is treated as an ECMAScript Script. The eval
code for a particular invocation of eval is the global code portion of that Script.
Function code is source text that is parsed to supply the value of the [[Code]] internal slot (see 9.1.14) of function and generator objects. The function code of a
particular function or generator does not include any source text that is parsed as the function code of a nested
FunctionBody, GeneratorBody, ConciseBody, or ClassBody.
Module code is source text that is code that is provided as a ModuleBody. It is the code that is
directly evaluated when a module is initialised. The module code of a particular module does not include any source
text that is parsed as part of a nested FunctionBody, GeneratorBody, ConciseBody, ClassBody,
or ModuleBody.
NOTE Function code is generally provided as the bodies of Function Definitions (14.1), Arrow Function Definitions (14.2), Method Definitions (14.3) and
Generator Definitions (14.4). Function code is also derived from the
last argument to the Function constructor (19.2.1.1) and the GeneratorFunction
constructor (25.2.1.1).
An ECMAScript Script syntactic unit may be processed using either unrestricted or strict mode
syntax and semantics. When processed using strict mode the four types of ECMAScript code are referred to as module code,
strict global code, strict eval code, and strict function code. Code is interpreted as strict mode code in the following
situations:
A ClassDeclaration or a ClassExpression is always strict code.
Eval code is strict eval code if it begins with a Directive Prologue that contains a Use Strict Directive or if the call to eval is a direct
call (see 18.2.1.1) to the eval function that is contained in strict mode
code.
Function code that is part of a FunctionDeclaration, FunctionExpression, or accessor PropertyDefinition is strict function code if
its FunctionDeclaration, FunctionExpression, or PropertyDefinition is contained in strict mode code or if the function code begins with a Directive Prologue that contains a Use Strict Directive.
Function code that is supplied as the last argument to the built-in Function constructor is strict function code if
the last argument is a String that when processed as a FunctionBody begins with a Directive Prologue that contains a Use Strict Directive.
An ECMAScript implementation may support the evaluation of exotic function objects whose evaluative behaviour is
expressed in some implementation defined form of executable code other than via ECMAScript code. Whether a function object
is an ECMAScript code function or a non-ECMAScript function is not semantically observable from the perspective of an
ECMAScript code function that calls or is called by such a non-ECMAScript function.
The source text of an ECMAScript script is first converted into a sequence of input elements, which are tokens, line
terminators, comments, or white space. The source text is scanned from left to right, repeatedly taking the longest possible
sequence of characters as the next input element.
There are several situations where the identification of lexical input elements is sensitive to the syntactic grammar
context that is consuming the input elements. This requires multiple goal symbols for the lexical grammar. The InputElementDiv goal symbol is the default goal symbol and is used in those syntactic grammar contexts where
a leading division (/) or division-assignment (/=) operator is permitted. The InputElementRegExp goal symbol is used in all syntactic grammar contexts where a RegularExpressionLiteral is permitted. The InputElementTemplateTail goal is used in
syntactic grammar contexts where a TemplateLiteral logically continues after a substitution
element.
NOTE There are no syntactic grammar contexts where both a leading division or
division-assignment, and a leading RegularExpressionLiteral are permitted. This is not affected by
semicolon insertion (see 11.9); in examples such as the following:
a = b /hi/g.exec(c).map(d);
where the first non-whitespace, non-comment character after a LineTerminator is slash
(/) and the syntactic context allows division or division-assignment, no semicolon is inserted at the LineTerminator. That is, the above example is interpreted in the same way as:
The Unicode format-control characters (i.e., the characters in category “Cf” in the Unicode Character Database
such as left-to-right mark or right-to-left mark) are control codes used to control the formatting of a range of text in the
absence of higher-level protocols for this (such as mark-up languages).
It is useful to allow format-control characters in source text to facilitate editing and display. All format control
characters may be used within comments, and within string literals, template literals, and regular expression literals.
U+200C (Zero width non-joiner) and U+200D (Zero width joiner) are format-control characters that are used to make necessary distinctions when forming words or phrases
in certain languages. In ECMAScript source text, <ZWNJ> and <ZWJ> may also be used in an identifier after the first character.
U+FEFF (Byte Order Mark) is a format-control character used primarily at the start of a text to mark it as Unicode and to allow
detection of the text's encoding and byte order. <BOM> characters
intended for this purpose can sometimes also appear after the start of a text, for example as a result of concatenating files.
<BOM> characters are treated as white space characters (see 11.2).
The special treatment of certain format-control characters outside of comments, string literals, and regular expression
literals is summarised in Table 28.
White space characters are used to improve source text readability and to separate tokens (indivisible lexical units) from
each other, but are otherwise insignificant. White space characters may occur between any two tokens and at the start or end
of input. White space characters may occur within a StringLiteral, a RegularExpressionLiteral, a Template, or a TemplateSubstitutionTail where they are considered significant characters forming part of a literal value.
They may also occur within a Comment, but cannot appear within any other kind of token.
The ECMAScript white space characters are listed in Table 29.
Table 29 — Whitespace Characters
Code Point
Name
Abbreviation
U+0009
Character Tabulation
<TAB>
U+000B
LINE TABULATION
<VT>
U+000C
Form Feed
<FF>
U+0020
Space
<SP>
U+00A0
No-break space
<NBSP>
U+FEFF
Byte Order Mark
<BOM>
Other category “Zs”
Any other Unicode “space separator”
<USP>
ECMAScript implementations must recognise all of the white space characters defined in Unicode 5.1. Later editions of the
Unicode Standard may define other white space characters. ECMAScript implementations may recognise white space characters from
later editions of the Unicode Standard.
Like white space characters, line terminator characters are used to improve source text readability and to separate tokens
(indivisible lexical units) from each other. However, unlike white space characters, line terminators have some influence over
the behaviour of the syntactic grammar. In general, line terminators may occur between any two tokens, but there are a few
places where they are forbidden by the syntactic grammar. Line terminators also affect the process of automatic semicolon insertion (11.9). A line terminator cannot occur within any token except a StringLiteral, Template, or TemplateSubstitutionTail. Line
terminators may only occur within a StringLiteral token as part of a LineContinuation.
A line terminator can occur within a MultiLineComment (11.4) but cannot
occur within a SingleLineComment.
Line terminators are included in the set of white space characters that are matched by the \s class in regular
expressions.
The ECMAScript line terminator characters are listed in Table 30.
Table 30 — Line Terminator Characters
Code Point
Name
Abbreviation
U+000A
Line Feed
<LF>
U+000D
Carriage Return
<CR>
U+2028
Line separator
<LS>
U+2029
Paragraph separator
<PS>
Only the Unicode code points in Table 30 are treated as line terminators. Other new line or line
breaking Unicode code points are treated as white space but not as line terminators. The sequence <CR><LF> is
commonly used as a line terminator. It should be considered a single SourceCharacter for the purpose
of reporting line numbers.
Comments can be either single or multi-line. Multi-line comments cannot nest.
Because a single-line comment can contain any Unicode code point except a LineTerminator character,
and because of the general rule that a token is always as long as possible, a single-line comment always consists of all
characters from the // marker to the end of the line. However, the LineTerminator at the
end of the line is not considered to be part of the single-line comment; it is recognised separately by the lexical grammar
and becomes part of the stream of input elements for the syntactic grammar. This point is very important, because it implies
that the presence or absence of single-line comments does not affect the process of automatic semicolon insertion (see 11.9).
Comments behave like white space and are discarded except that, if a MultiLineComment contains a
line terminator character, then the entire comment is considered to be a LineTerminator for purposes
of parsing by the syntactic grammar.
NOTE The DivPunctuator, RegularExpressionLiteral,
RightBracePunctuator, and TemplateSubstitutionTail productions define tokens, but are not
included in the Token production.
IdentifierName, Identifier, and ReservedWord are
tokens that are interpreted according to the Default Identifier Syntax given in Unicode Standard Annex #31, Identifier and
Pattern Syntax, with some small modifications. ReservedWord is is an enumerated subset of IdentifierName and Identifier is an IdentifierName that is
not a ReservedWord (see 11.6.2). The Unicode identifier grammar is
based on character properties specified by the Unicode Standard. The Unicode code points in the specified categories in
version 5.1.0 of the Unicode standard must be treated as in those categories by all conforming ECMAScript implementations.
ECMAScript implementations may recognise identifier characters defined in later editions of the Unicode Standard.
NOTE 1 This standard specifies specific character additions: The dollar sign
(U+0024) and the underscore (U+005f) are permitted anywhere in an IdentifierName, and the characters zero width non-joiner (U+200C) and zero width joiner (U+200D) are
permitted anywhere after the first character of an IdentifierName.
Unicode escape sequences are permitted in an IdentifierName, where they contribute a single
Unicode code point to the IdentifierName. The code point is expressed by the HexDigits of the UnicodeEscapeSequence (see 11.8.4). The \ preceding the UnicodeEscapeSequence and the u and { } characters, if they appear, do not
contribute code points to the IdentifierName. A UnicodeEscapeSequence cannot
be used to put a code point into an IdentifierName that would otherwise be illegal. In other words,
if a \UnicodeEscapeSequence sequence were replaced by the SourceCharacter it constributes, the result must still be a valid IdentifierName
that has the exact same sequence of SourceCharacter elements as the original IdentifierName. All interpretations of IdentifierName within this specification
are based upon their actual code points regardless of whether or not an escape sequence was used to contribute any
particular characters.
Two IdentifierName that are canonically equivalent according to the Unicode standard are
not equal unless they are represented by the exact same sequence of code points (in other words, conforming
ECMAScript implementations are only required to do bitwise comparison on IdentifierName values).
Syntax
Identifier::
IdentifierNamebut notReservedWord
IdentifierName::
IdentifierStart
IdentifierNameIdentifierPart
IdentifierStart::
UnicodeIDStart
$
_
\UnicodeEscapeSequence
IdentifierPart::
UnicodeIDContinue
$
_
\UnicodeEscapeSequence
<ZWNJ>
<ZWJ>
UnicodeIDStart::
any Unicode code point with the Unicode property “ID_Start”.
UnicodeIDContinue::
any Unicode code point with the Unicode property “ID_Continue”
The definitions of the nonterminal UnicodeEscapeSequence is given in 11.8.4.
It is an Syntax Error if StringValue(IdentifierName) is the same string value as
the StringValue of any ReservedWord.
NOTEStringValue(IdentifierName) normalizes any Unicode escape
sequences in IdentifierName hence such escapes can not be used to write an Identifier whose code point sequence is the same as a ReservedWord.
IdentifierStart::\UnicodeEscapeSequence
It is an Sytax Error if SV(UnicodeEscapeSequence) is
neither the UTF-16 encoding of a single Unicode code point with the Unicode property “ID_Start” nor
"$″ or "_″.
IdentifierPart::\UnicodeEscapeSequence
It is an Sytax Error if SV(UnicodeEscapeSequence) is
neither the UTF-16 encoding of a single Unicode code point with the Unicode property “ID_Continue” nor
"$″ or "_″ nor the UTF-16 encoding either <ZWNJ> or <ZAJ>.
NOTE An UnicodeEscape can not be used for force an Identifier to include a code point that could not literally appear within an Identifier.
Return the String value consisting of the sequence of code units corresponding to IdentifierName. In
determining the sequence any occurrences of \UnicodeEscapeSequence are first replaced with the
code point represented by the UnicodeEscapeSequence and then the code points of the entire
IdentifierName are converted to code units by UTF-16 Encoding (10.1.1) each code point.
A reserved word is an IdentifierName that cannot be used as an Identifier.
Syntax
ReservedWord::
Keyword
FutureReservedWord
NullLiteral
BooleanLiteral
The ReservedWord definitions are specified as literal sequences of specific SourceCharacter elements. Code point in a ReservedWord can not be expressed by
a \UnicodeEscapeSequence.
The following tokens are ECMAScript keywords and may not be used as Identifiers in ECMAScript
programs.
Syntax
Keyword::one of
break
do
in
typeof
case
else
instanceof
var
catch
export
new
void
class
extends
return
while
const
finally
super
with
continue
for
switch
yield
debugger
function
this
default
if
throw
delete
import
try
NOTE In some contexts yield is given the semantics of an Identifier. See 12.1.2.1, 12.1.5.1, and 13.2.1.1. In strict mode code, let is treated as a keyword through static semantic
restrictions (see 12.1.2.1, 12.1.5.1, and 13.2.1.1) rather than the lexical grammar.
The following words are used as keywords in proposed extensions and are therefore reserved to allow for the possibility
of future adoption of those extensions.
Syntax
FutureReservedWord::
enum
NOTE Use of the following tokens within strict mode code
(see 10.2.1) is also reserved. That usage is restricted using static semantic
restrictions (see 12.1.2.1, 12.1.5.1, and 13.2.1.1) rather than the lexical grammar:
The SourceCharacter immediately following a NumericLiteral must not be
an IdentifierStart or DecimalDigit.
NOTE For example:
3in
is an error and not the two input elements 3 and in.
A conforming implementation, when processing strict mode code (see 10.2.1), must not extend the syntax of NumericLiteral to include
LegacyOctalIntegerLiteral as described in B.1.1.
A numeric literal stands for a value of the Number type. This value is determined in two steps: first, a mathematical
value (MV) is derived from the literal; second, this mathematical value is rounded as described below.
The MV of NumericLiteral::DecimalLiteral is the MV of DecimalLiteral.
The MV of NumericLiteral::BinaryIntegerLiteral is the MV of BinaryIntegerLiteral.
The MV of NumericLiteral::OctalIntegerLiteral is the MV of OctalIntegerLiteral.
The MV of NumericLiteral::HexIntegerLiteral is the MV of HexIntegerLiteral.
The MV of DecimalLiteral::DecimalIntegerLiteral. is the MV of DecimalIntegerLiteral.
The MV of DecimalLiteral::DecimalIntegerLiteral.DecimalDigits is the
MV of DecimalIntegerLiteral plus (the MV of DecimalDigits × 10–n), where
n is the number of characters in DecimalDigits.
The MV of DecimalLiteral::DecimalIntegerLiteral.ExponentPart is the MV
of DecimalIntegerLiteral × 10e, where e is the MV of ExponentPart.
The MV of DecimalLiteral::DecimalIntegerLiteral.DecimalDigitsExponentPart is (the MV of DecimalIntegerLiteral plus (the MV of DecimalDigits
× 10–n)) × 10e, where n is the number of characters in
DecimalDigits and e is the MV of ExponentPart.
The MV of DecimalLiteral::.DecimalDigits is the MV of DecimalDigits ×
10–n, where n is the number of characters in DecimalDigits.
The MV of DecimalLiteral::.DecimalDigitsExponentPart is the MV of
DecimalDigits × 10e–n, where n is the number of characters in
DecimalDigits and e is the MV of ExponentPart.
The MV of DecimalLiteral::DecimalIntegerLiteral is the MV of DecimalIntegerLiteral.
The MV of DecimalLiteral::DecimalIntegerLiteralExponentPart is the MV of
DecimalIntegerLiteral × 10e, where e is the MV of ExponentPart.
The MV of DecimalIntegerLiteral::0 is 0.
The MV of DecimalIntegerLiteral::NonZeroDigit is the MV of NonZeroDigit.
The MV of DecimalIntegerLiteral::NonZeroDigitDecimalDigits is (the MV of NonZeroDigit ×
10n) plus the MV of DecimalDigits, where n is the number of characters in
DecimalDigits.
The MV of DecimalDigits::DecimalDigit is the MV of DecimalDigit.
The MV of DecimalDigits::DecimalDigitsDecimalDigit is (the MV of DecimalDigits ×
10) plus the MV of DecimalDigit.
The MV of ExponentPart::ExponentIndicatorSignedInteger is the MV of
SignedInteger.
The MV of SignedInteger::DecimalDigits is the MV of DecimalDigits.
The MV of SignedInteger::+DecimalDigits is the MV of DecimalDigits.
The MV of SignedInteger::-DecimalDigits is the negative of the MV of DecimalDigits.
The MV of DecimalDigit::0 or of HexDigit::0 or of OctalDigit::0 or of BinaryDigit::0 is 0.
The MV of DecimalDigit::1 or of NonZeroDigit::1 or of HexDigit::1 or of OctalDigit::1 or of BinaryDigit::1 is 1.
The MV of DecimalDigit::2 or of NonZeroDigit::2 or of HexDigit::2 or of OctalDigit::2 is 2.
The MV of DecimalDigit::3 or of NonZeroDigit::3 or of HexDigit::3 or of OctalDigit::3 is 3.
The MV of DecimalDigit::4 or of NonZeroDigit::4 or of HexDigit::4 or of OctalDigit::4 is 4.
The MV of DecimalDigit::5 or of NonZeroDigit::5 or of HexDigit::5 or of OctalDigit::5 is 5.
The MV of DecimalDigit::6 or of NonZeroDigit::6 or of HexDigit::6 or of OctalDigit::6 is 6.
The MV of DecimalDigit::7 or of NonZeroDigit::7 or of HexDigit::7 or of OctalDigit::7 is 7.
The MV of DecimalDigit::8 or of NonZeroDigit::8 or of HexDigit::8 is 8.
The MV of DecimalDigit::9 or of NonZeroDigit::9 or of HexDigit::9 is 9.
The MV of HexDigit::a or of HexDigit::A is 10.
The MV of HexDigit::b or of HexDigit::B is 11.
The MV of HexDigit::c or of HexDigit::C is 12.
The MV of HexDigit::d or of HexDigit::D is 13.
The MV of HexDigit::e or of HexDigit::E is 14.
The MV of HexDigit::f or of HexDigit::F is 15.
The MV of BinaryIntegerLiteral::0bBinaryDigits is the MV of BinaryDigits.
The MV of BinaryIntegerLiteral::0BBinaryDigits is the MV of BinaryDigits.
The MV of BinaryDigits::BinaryDigit is the MV of BinaryDigit.
The MV of BinaryDigits::BinaryDigitsBinaryDigit is (the MV of BinaryDigits × 2)
plus the MV of BinaryDigit.
The MV of OctalIntegerLiteral::0oOctalDigits is the MV of OctalDigits.
The MV of OctalIntegerLiteral::0OOctalDigits is the MV of OctalDigits.
The MV of OctalDigits::OctalDigit is the MV of OctalDigit.
The MV of OctalDigits::OctalDigitsOctalDigit is (the MV of OctalDigits × 8)
plus the MV of OctalDigit.
The MV of HexIntegerLiteral::0xHexDigits is the MV of HexDigits.
The MV of HexIntegerLiteral::0XHexDigits is the MV of HexDigits.
The MV of HexDigits::HexDigit is the MV of HexDigit.
The MV of HexDigits::HexDigitsHexDigit is (the MV of HexDigits × 16) plus
the MV of HexDigit.
Once the exact MV for a numeric literal has been determined, it is then rounded to a value of the Number type. If the
MV is 0, then the rounded value is +0; otherwise, the rounded value must be the Number value
for the MV (as specified in 6.1.6), unless the literal is a DecimalLiteral and the literal has more than 20 significant digits, in which case the Number value may
be either the Number value for the MV of a literal produced by replacing each significant digit after the 20th with a
0 digit or the Number value for the MV of a literal produced by replacing each significant digit after the
20th with a 0 digit and then incrementing the literal at the 20th significant digit position. A digit is
significant if it is not part of an ExponentPart and
it is not 0; or
there is a nonzero digit to its left and there is a nonzero digit, not in the ExponentPart, to its
right.
NOTE A string literal is zero or more Unicode code points enclosed in single or double
quotes. Unicode code points may also be represented by an escape sequence. All characters may appear literally in a
string literal except for the closing quote character, backslash, carriage return, line separator, paragraph separator,
and line feed. Any character may appear in the form of an escape sequence. String literals evaluate to ECAMScript String
values. When generating these string values Unicode code points are UTF-16 encoded as defined in 10.1.1. Code points belonging to Basic Multilingual Plane are encoded
as a single code unit element of the string. All other code points are encoded as two code unit elements of the
string.
Syntax
StringLiteral::
"DoubleStringCharactersopt"
'SingleStringCharactersopt'
DoubleStringCharacters::
DoubleStringCharacterDoubleStringCharactersopt
SingleStringCharacters::
SingleStringCharacterSingleStringCharactersopt
DoubleStringCharacter::
SourceCharacterbut not one of"or\orLineTerminator
\EscapeSequence
LineContinuation
SingleStringCharacter::
SourceCharacterbut not one of'or\orLineTerminator
\EscapeSequence
LineContinuation
LineContinuation::
\LineTerminatorSequence
EscapeSequence::
CharacterEscapeSequence
0[lookahead ∉ DecimalDigit]
HexEscapeSequence
UnicodeEscapeSequence
A conforming implementation, when processing strict mode code (see 10.2.1), must not extend the syntax of EscapeSequence to include
LegacyOctalEscapeSequence as described in B.1.2.
CharacterEscapeSequence::
SingleEscapeCharacter
NonEscapeCharacter
SingleEscapeCharacter::one of
'"\bfnrtv
NonEscapeCharacter::
SourceCharacterbut not one ofEscapeCharacterorLineTerminator
EscapeCharacter::
SingleEscapeCharacter
DecimalDigit
x
u
HexEscapeSequence::
xHexDigitHexDigit
UnicodeEscapeSequence::
uHex4Digits
u{HexDigits}
Hex4Digits::
HexDigitHexDigitHexDigitHexDigit
The definition of the nonterminal HexDigit is given in 11.8.3. SourceCharacter is defined in 10.1.
NOTE A line terminator character cannot appear in a string literal, except as part of a LineContinuation to produce the empty character sequence. The correct way to cause a line terminator
character to be part of the String value of a string literal is to use an escape sequence such as \n or
\u000A.
A string literal stands for a value of the String type. The String value (SV) of the literal is described in terms of
code unit values (CV) contributed by the various parts of the string literal. As part of this process, some Unicode code
points within the string literal are interpreted as having a mathematical value (MV), as described below or in 11.8.3.
The SV of StringLiteral::"" is the empty code unit sequence.
The SV of StringLiteral::'' is the empty code unit sequence.
The SV of StringLiteral::"DoubleStringCharacters" is the SV of
DoubleStringCharacters.
The SV of StringLiteral::'SingleStringCharacters' is the SV of
SingleStringCharacters.
The SV of DoubleStringCharacters::DoubleStringCharacter is a sequence of one or two code units that is the CV of
DoubleStringCharacter.
The SV of DoubleStringCharacters::DoubleStringCharacterDoubleStringCharacters is a sequence of one or
two code units that is the CV of DoubleStringCharacter followed by all the code units in the SV of
DoubleStringCharacters in order.
The SV of SingleStringCharacters::SingleStringCharacter is a sequence of one or two code units that is the CV of
SingleStringCharacter.
The SV of SingleStringCharacters::SingleStringCharacterSingleStringCharacters is a sequence of one or
two code units that is the CV of SingleStringCharacter followed by all the code units in the SV of
SingleStringCharacters in order.
The CV of DoubleStringCharacter::SourceCharacterbut not one of"or\orLineTerminator is the UTF-16 Encoding (10.1.1) of the code point value of SourceCharacter.
The CV of DoubleStringCharacter::\EscapeSequence is the CV of the EscapeSequence.
The CV of DoubleStringCharacter::LineContinuation is the empty character sequence.
The CV of SingleStringCharacter::SourceCharacterbut not one of'or\orLineTerminator is the UTF-16 Encoding (10.1.1) of the code point value of SourceCharacter .
The CV of SingleStringCharacter::\EscapeSequence is the CV of the EscapeSequence.
The CV of SingleStringCharacter::LineContinuation is the empty character sequence.
The CV of EscapeSequence::CharacterEscapeSequence is the CV of the CharacterEscapeSequence.
The CV of EscapeSequence::0 is the code unit value 0.
The CV of EscapeSequence::HexEscapeSequence is the CV of the HexEscapeSequence.
The CV of EscapeSequence::UnicodeEscapeSequence is the CV of the UnicodeEscapeSequence.
The CV of CharacterEscapeSequence::SingleEscapeCharacter is the character whose code unit value is determined by the
SingleEscapeCharacter according to Table 31.
Table 31 — String Single Character Escape Sequences
Escape Sequence
Code Unit Value
Name
Symbol
\b
0x0008
backspace
<BS>
\t
0x0009
horizontal tab
<HT>
\n
0x000A
line feed (new line)
<LF>
\v
0x000B
vertical tab
<VT>
\f
0x000C
form feed
<FF>
\r
0x000D
carriage return
<CR>
\"
0x0022
double quote
"
\'
0x0027
single quote
'
\\
0x005C
backslash
\
The CV of CharacterEscapeSequence::NonEscapeCharacter is the CV of the NonEscapeCharacter.
The CV of NonEscapeCharacter::SourceCharacterbut not one ofEscapeCharacterorLineTerminator is the UTF-16 Encoding (10.1.1) of the code point value of SourceCharacter .
The CV of HexEscapeSequence::xHexDigitHexDigit is the code unit value
that is (16 times the MV of the first HexDigit) plus the MV of the second HexDigit.
The CV of UnicodeEscapeSequence::uHex4Digits is the code unit value that is (4096 times the MV of the first
HexDigit) plus (256 times the MV of the second HexDigit) plus (16 times the MV of the third
HexDigit) plus the MV of the fourth HexDigit.
The CV of Hex4Digits::HexDigitHexDigitHexDigitHexDigit is the code unit value that is (4096 times the MV of the first HexDigit) plus (256 times the MV
of the second HexDigit) plus (16 times the MV of the third HexDigit) plus the MV of the fourth
HexDigit.
The CV of UnicodeEscapeSequence::u{HexDigits} is the UTF-16 Encoding (10.1.1) of the MV of HexDigits.
NOTE A regular expression literal is an input element that is converted to a RegExp object
(see 21.1.5) each time the literal is evaluated. Two regular expression
literals in a program evaluate to regular expression objects that never compare as === to each other even
if the two literals' contents are identical. A RegExp object may also be created at runtime by new RegExp
(see 21.2.3.2) or calling the RegExp constructor as a
function (21.2.3.1).
The productions below describe the syntax for a regular expression literal and are used by the input element scanner to
find the end of the regular expression literal. The source code comprising the RegularExpressionBody and the RegularExpressionFlags are subsequently parsed
using the more stringent ECMAScript Regular Expression grammar (21.2.1).
An implementation may extend the ECMAScript Regular Expression grammar defined in 21.2.1,
but it must not extend the RegularExpressionBody and RegularExpressionFlags productions defined below or the productions used by these productions.
Syntax
RegularExpressionLiteral::
/RegularExpressionBody/RegularExpressionFlags
RegularExpressionBody::
RegularExpressionFirstCharRegularExpressionChars
RegularExpressionChars::
[empty]
RegularExpressionCharsRegularExpressionChar
RegularExpressionFirstChar::
RegularExpressionNonTerminatorbut not one of*or\or/or[
RegularExpressionBackslashSequence
RegularExpressionClass
RegularExpressionChar::
RegularExpressionNonTerminatorbut not one of\or/or[
NOTE Regular expression literals may not be empty; instead of representing an empty regular
expression literal, the characters // start a single-line comment. To specify an empty regular expression,
use: /(?:)/.
A template literal component is interpreted as a sequence of Unicode code points. The Template Value (TV) of a literal
component is described in terms of code unit values (CV, 11.8.4) contributed
by the various parts of the template literal component. As part of this process, some Unicode code points within the
template component are interpreted as having a mathematical value (MV, 11.8.3). In determining a TV, escape sequences are replaced by the UTF-16 code
unit(s) of the Unicode code point represented by the escape sequence. The Template Raw Value (TRV) is similar to a
Template Value with the difference that in TRVs escape sequences are interpreted literally.
The TV and TRV of NoSubstitutionTemplate::`` is the empty code unit sequence.
The TV and TRV of TemplateHead::`${ is the empty code unit sequence.
The TV and TRV of TemplateMiddle::}${ is the empty code unit sequence.
The TV and TRV of TemplateTail::}` is the empty code unit sequence.
The TV of NoSubstitutionTemplate::`TemplateCharacters` is the TV of
TemplateCharacters.
The TV of TemplateHead::`TemplateCharacters${ is the TV of
TemplateCharacters.
The TV of TemplateMiddle::}TemplateCharacters${ is the TV of
TemplateCharacters.
The TV of TemplateTail::}TemplateCharacters` is the TV of
TemplateCharacters.
The TV of TemplateCharacters::TemplateCharacter is the TV of TemplateCharacter.
The TV of TemplateCharacters::TemplateCharacterTemplateCharacters is a sequence consisting of the
code units in the TV of TemplateCharacter followed by all the code units in the TV of TemplateCharacters
in order.
The TV of TemplateCharacter::SourceCharacterbut not one of`or\or$orLineTerminatorSequence is the UTF-16 Encoding (10.1.1) of the code point value of SourceCharacter.
The TV of TemplateCharacter::$ is the code unit value 0x0024.
The TV of TemplateCharacter::\EscapeSequence is the CV of EscapeSequence.
The TV of TemplateCharacter::LineContinuation is the TV of LineContinuation.
The TV of TemplateCharacter::LineTerminatorSequence is the TRV of LineTerminatorSequence.
The TV of LineContinuation::\LineTerminatorSequence is the empty code unit sequence.
The TRV of NoSubstitutionTemplate::`TemplateCharacters` is the TRV of
TemplateCharacters.
The TRV of TemplateHead::`TemplateCharacters${ is the TRV of
TemplateCharacters.
The TRV of TemplateMiddle::}TemplateCharacters${ is the TRV of
TemplateCharacters.
The TRV of TemplateTail::}TemplateCharacters` is the TRV of
TemplateCharacters.
The TRV of TemplateCharacters::TemplateCharacter is the TRV of TemplateCharacter.
The TRV of TemplateCharacters::TemplateCharacterTemplateCharacters is a sequence consisting of the
code units in the TRV of TemplateCharacter followed by all the code units in the TRV of
TemplateCharacters, in order.
The TRV of TemplateCharacter::SourceCharacterbut not one of`or\or$orLineTerminatorSequence is the UTF-16 Encoding (10.1.1) of the code point value of SourceCharacter.
The TRV of TemplateCharacter::$ is the code unit value 0x0024.
The TRV of TemplateCharacter::\EscapeSequence is the sequence consisting of the code unit value
0x005C followed by the code units of TRV of EscapeSequence.
The TRV of TemplateCharacter::LineContinuation is the TRV of LineContinuation.
The TRV of TemplateCharacter::LineTerminatorSequence is the TRV of LineTerminatorSequence.
The TRV of EscapeSequence::CharacterEscapeSequence is the TRV of the CharacterEscapeSequence.
The TRV of EscapeSequence::0 is the code unit value 0x0030.
The TRV of EscapeSequence::HexEscapeSequence is the TRV of the HexEscapeSequence.
The TRV of EscapeSequence::UnicodeEscapeSequence is the TRV of the UnicodeEscapeSequence.
The TRV of CharacterEscapeSequence::SingleEscapeCharacter is the TRV of the SingleEscapeCharacter.
The TRV of CharacterEscapeSequence::NonEscapeCharacter is the CV of the NonEscapeCharacter.
The TRV of SingleEscapeCharacter::one of'"\bfnrtv is the CV of the SourceCharacter that is that single character.
The TRV of HexEscapeSequence::xHexDigitHexDigit is the sequence
consisting of code unit value 0x0078 followed by TRV of the first HexDigit followed by the TRV of the second
HexDigit.
The TRV of UnicodeEscapeSequence::uHexDigitHexDigitHexDigitHexDigit is the sequence consisting of code unit value 0x0075 followed by TRV of the
first HexDigit followed by the TRV of the second HexDigit followed by TRV of the third HexDigit
followed by the TRV of the fourth HexDigit.
The TRV of UnicodeEscapeSequence::u{HexDigits} is the sequence consisting of
code unit value 0x0075 followed by code unit value 0x007B followed by TRV of HexDigits followed by code unit
value 0x007D.
The TRV of HexDigits::HexDigit is the TRV of HexDigit.
The TRV of HexDigits::HexDigitsHexDigit is the sequence consisting of TRV of
HexDigits followed by TRV of HexDigit.
The TRV of a HexDigit is the CV of the SourceCharacter that is that HexDigit.
The TRV of LineContinuation::\LineTerminatorSequence is the sequence consisting of the code unit
value 0x005C followed by the code units of TRV of LineTerminatorSequence.
The TRV of LineTerminatorSequence::
<LF> is the code unit value 0x000A.
The TRV of LineTerminatorSequence::
<CR> is the code unit value 0x000A.
The TRV of LineTerminatorSequence::
<LS> is the code unit value 0x2028.
The TRV of LineTerminatorSequence::
<PS> is the code unit value 0x2029.
The TRV of LineTerminatorSequence::
<CR><LF> is the sequence consisting of the code unit value 0x000A.
NOTE TV excludes the code units of LineContinuation while TRV
includes them. <CR><LF> and <CR> LineTerminatorSequences are normalized to
<LF> for both TV and TRV. An explicit EscapeSequence is needed to include a <CR> or
<CR><LF> sequence.
Certain ECMAScript statements (empty statement, let and const declarations, variable statement, expression statement,
debugger statement, continue statement, break statement, return
statement, and throw statement) must be terminated with semicolons. Such semicolons may always appear
explicitly in the source text. For convenience, however, such semicolons may be omitted from the source text in certain
situations. These situations are described by saying that semicolons are automatically inserted into the source code token
stream in those situations.
There are three basic rules of semicolon insertion:
When, as the script is parsed from left to right, a token (called the offending token) is encountered that is
not allowed by any production of the grammar, then a semicolon is automatically inserted before the offending token if
one or more of the following conditions is true:
The offending token is separated from the previous token by at least one LineTerminator.
The offending token is }.
When, as the script is parsed from left to right, the end of the input stream of tokens is encountered and the parser
is unable to parse the input token stream as a single complete ECMAScript script, then a semicolon is
automatically inserted at the end of the input stream.
When, as the script is parsed from left to right, a token is encountered that is allowed by some production of the
grammar, but the production is a restricted production and the token would be the first token for a terminal or
nonterminal immediately following the annotation “[no LineTerminator here]” within the restricted production (and therefore such a token is called a restricted token), and
the restricted token is separated from the previous token by at least one LineTerminator, then
a semicolon is automatically inserted before the restricted token.
However, there is an additional overriding condition on the preceding rules: a semicolon is never inserted automatically
if the semicolon would then be parsed as an empty statement or if that semicolon would become one of the two semicolons in
the header of a for statement (see 13.6.3).
NOTE The following are the only restricted productions in the grammar:
The practical effect of these restricted productions is as follows:
When a ++ or -- token is encountered where the parser would treat it as a postfix operator, and
at least one LineTerminator occurred between the preceding token and the ++ or
-- token, then a semicolon is automatically inserted before the ++ or -- token.
When a continue, break, return, throw, or yield token is
encountered and a LineTerminator is encountered before the next token, a semicolon is automatically
inserted after the continue, break, return, throw, or yield
token.
The resulting practical advice to ECMAScript programmers is:
A postfix ++ or -- operator should appear on the same line as its operand.
An Expression in a return or throw statement or an AssignmentExpression in a yield expression should start on the same line as the
return, throw, or yield token.
An IdentifierReference in a break or continue statement should be on
the same line as the break or continue token.
is not a valid ECMAScript sentence and is not altered by automatic semicolon
insertion because the semicolon is needed for the header of a for statement. Automatic semicolon insertion
never inserts one of the two semicolons in the header of a for statement.
NOTE The expression a + b is not treated as a value to be returned by the
return statement, because a LineTerminator separates it from the token
return.
NOTE The token ++ is not treated as a postfix operator applying to the variable
b, because a LineTerminator occurs between b and ++.
The source
if (a > b) else c = d
is not a valid ECMAScript sentence and is not altered by automatic semicolon
insertion before the else token, even though no production of the grammar applies at that point, because an
automatically inserted semicolon would then be parsed as an empty statement.
The source
a = b + c (d + e).print()
is not transformed by automatic semicolon insertion, because the
parenthesised expression that begins the second line can be interpreted as an argument list for a function call:
a = b + c(d + e).print()
In the circumstance that an assignment statement must begin with a left parenthesis, it is a good idea for the programmer
to provide an explicit semicolon at the end of the preceding statement rather than to rely on automatic semicolon insertion.
When processing the production PrimaryExpression:CoverParenthesisedExpressionAndArrowParameterList the following grammar is used to refine the
interpretation of CoverParenthesisedExpressionAndArrowParameterList.
Return the result of parsing the lexical token stream matched by
CoverParenthesisedExpressionAndArrowParameterList using ParenthesisedExpression as the goal
symbol.
It is a Syntax Error if this NonResolvedIdentifier is contained in strict code and if the StringValue of Identifier is:
"implements", "interface", "let", "package",
"private", "protected", "public", "static", or
"yield".
It is a Syntax Error if this NonResolvedIdentifier has a [Yield] and the StringValue of Identifier is
"yield".
NonResolvedIdentifier:yield
It is a Syntax Error if the IdentifierReference is contained in strict code.
NOTE Unlike a BindingIdentifier (13.2.1.1), an IdentifierReference in strict code may be the Identifiereval or arguments.
Assert: The source code matching this production is not strict code.
Let ref be the result of performing ResolveBinding("yield").
Return ref.
NOTE 1: The result of evaluating an IdentifierReference is always a
value of type Reference.
NOTE 2: In non-strict code, the keyword
yield may be used as an identifier. Evaluating the IdentifierReference production
resolved the binding of yield as if it was an Identifier. The Early Error
restriction ensures that such an evaluation only can occur for non-strict code. See
13.2.1 for the handling of yield in binding creation
contexts.
NOTE An ArrayLiteral is an expression describing the
initialisation of an Array object, using a list, of zero or more expressions each of which represents an array
element, enclosed in square brackets. The elements need not be literals; they are evaluated each time the array
initialiser is evaluated.
Array elements may be elided at the beginning, middle or end of the element list. Whenever a comma in the element
list is not preceded by an AssignmentExpression (i.e., a comma at the beginning or after another
comma), the missing array element contributes to the length of the Array and increases the index of subsequent elements.
Elided array elements are not defined. If an element is elided at the end of an array, that element does not contribute
to the length of the Array.
Let created be the result of calling the [[DefineOwnProperty]] internal method of array with
arguments ToString(ToUint32(nextIndex+padding)) and
the PropertyDescriptor{ [[Value]]: initValue, [[Writable]]: true, [[Enumerable]]: true,
[[Configurable]]: true}.
Let created be the result of calling the [[DefineOwnProperty]] internal method of array with
arguments ToString(ToUint32(postIndex+padding)) and the PropertyDescriptor{ [[Value]]:
initValue, [[Writable]]: true, [[Enumerable]]: true, [[Configurable]]: true}.
NOTE [[DefineOwnProperty]] is used to ensure that own properties are defined for the array
even if the standard built-in Array prototype object has been modified in a manner that would preclude the creation of
new own properties using [[Set]].
NOTEundefined is passed for environment to indicate that a PutValue operation should be used to assign the initialisation value. This is the case for
var statements formal parameter lists of non-strict functions. In those cases a lexical binding is hosted
and preinitialised prior to evaluation of its initialiser.
ForBinding:BindingPattern
If Type(value) is not Object, then throw a
TypeError exception.
Return the result of performing BindingInitialisation for BindingPattern passing value and
environment as the arguments.
NOTEundefined is passed for accumulator to indicate that a comprehension
component is being evaluated as part of a generator comprehension. Otherwise, the value of accumulator is
the array object into the elements of an array comprehension are to be accumulated.
Comprehension:ComprehensionForComprehensionTail
Return the result of performing ComprehensionComponentEvaluation for ComprehensionFor with arguments
ComprehensionTail and accumulator.
NOTEundefined is passed for accumulator to indicate that a comprehension
component is being evaluated as part of a generator comprehension. Otherwise, the value of accumulator is
the array object into the elements of an array comprehension are to be accumulated.
NOTE 1 An object initialiser is an expression describing the initialisation of an Object,
written in a form resembling a literal. It is a list of zero or more pairs of property names and associated values,
enclosed in curly braces. The values need not be literals; they are evaluated each time the object initialiser is
evaluated.
NOTE 3 In certain contexts, ObjectLiteral is used as a cover grammar
for a more restricted secondary grammar. The CoverInitialisedName production is necessary to
fully cover these secondary grammars. However, use of this production results in an early Syntax Error in normal
contexts where an actual ObjectLiteral is expected.
In addition to describing an actual object initialiser the ObjectLiteral productions are also
used as a cover grammar for ObjectAssignmentPattern (12.13.5). When ObjectLiteral appears in a context where
ObjectAssignmentPattern is required, the following Early Error rules are not applied.
ObjectLiteral:{PropertyDefinitionList}
and
ObjectLiteral:{PropertyDefinitionList,}
It is a Syntax Error if PropertyNameList of PropertyDefinitionListcontains any duplicate entries, unless one of the following conditions
are true for each duplicate entry:
The source code corresponding to PropertyDefinitionList is not strict code and all occurrences in the list of the duplicated entry were
obtained from productions of the form PropertyDefinition:PropertyName:AssignmentExpression .
The duplicated entry occurs exactly twice in the list and one occurrence was obtained from a get
accessor MethodDefinition and the other occurrence was obtained from a set
accessor MethodDefinition.
PropertyDefinition:IdentifierReference
It is a Syntax Error if the PropertyDefinition is contained in strict code and if the IdentifierReference is:
implements, interface, let, package, private,
protected, public, static, or yield.
It is a Syntax Error if IdentifierReference is a ReservedWord other
than yield.
PropertyDefinition:CoverInitialisedName
Always throw a Syntax Error if this production is present
NOTE This production exists so that ObjectLiteral can serve as a
cover grammar for ObjectAssignmentPattern (12.13.5).
It cannot occur in an actual object initialiser.
NOTE The keyword yield may be used in identifier contexts within a GeneratorComprehension contained in non-strict code. The following
early error rule ensures that a GeneratorComprehension never contains a YieldExpression.
Let parameters be the production: FormalParameters: [empty].
Using Comprehension from the production that is being evaluated, let body be the supplemental
syntactic grammar production: GeneratorBody:Comprehension .
Let closure be the result of performing the GeneratorFunctionCreate abstract operation with arguments Arrow,
parameters, body, scope, andstrict.
Let prototype be the result of the abstract operation ObjectCreate with the
intrinsic object %GeneratorPrototype% as its argument.
Perform the abstract operation MakeConstructor with arguments closure,
true, and prototype.
Let iterator be the result of calling the [[Call]] internal method of closure with undefined as
thisArgument and an empty List as
argumentsList.
Return iterator.
NOTE The GeneratorFunction object created in step 5 is not observable from ECMAScript code so
an implementation may choose to avoid its allocation and initialisation. In that case use other semantically equivalent
means must be used to allocate and initialise the iterator object in step 8. In either case, the
prototype object created in step 6 must be created because it is potentially observable as the value of the
iterator object’s [[Prototype]] internal
slot.
It is a Syntax Error if BodyText of RegularExpressionLiteral cannot be recognised using the goal symbol Pattern
of the ECMAScript RegExp grammar specified in 21.2.1.
It is a Syntax Error if FlagText of RegularExpressionLiteral contains any character other than "g", "i",
"m", "u", or "y", or if it contains the same character more than once.
Return a List whose first element is siteObj, whose
second elements is firstSub, and whose subsequent elements are the elements of restSub, in order.
restSub may contain no elements.
The abstract operation GetTemplateCallSite is called with a grammar
production, templateLiteral, as an argument. It performs the following steps:
If a call site object for the source code corresponding to templateLiteral has already been created by a
previous call to this abstract operation, then
Return that call site object.
Let cookedStrings be TemplateStrings of templateLiteral with argument false.
Let rawStrings be TemplateStrings of templateLiteral with argument true.
Let count be the number of elements in the ListcookedStrings.
Let siteObj be the result of the abstract operation ArrayCreate with
argument count.
Let rawObj be the result of the abstract operation ArrayCreate with argument
count.
Let cookedValue be the string value at 0-based position index of the ListcookedStrings.
Call the [[DefineOwnProperty]] internal method of siteObj with arguments prop and
PropertyDescriptor{[[Value]]: cookedValue, [[Enumerable]]: true, [[Writable]]: false,
[[Configurable]]: false}.
Let rawValue be the string value at 0-based position index of the ListrawStrings.
Call the [[DefineOwnProperty]] internal method of rawObj with arguments prop and
PropertyDescriptor{[[Value]]: rawValue, [[Enumerable]]: true, [[Writable]]: false,
[[Configurable]]: false}.
Call the [[DefineOwnProperty]] internal method of siteObj with arguments "raw" and PropertyDescriptor{[[Value]]: rawObj, [[Writable]]: false,
[[Enumerable]]: false, [[Configurable]]: false}.
Remember an association between the source code corresponding to templateLiteral and siteObj such
that siteObj can be retrieve in subsequent calls to this abstract operation.
Return siteObj.
NOTE 1 The creation of a call site object cannot result in an abrupt completion.
NOTE 2 Each TemplateLiteral in the program code is associated with
a unique Template call site object that is used in the evaluation of tagged Templates (12.1.9.2.4). The same call site object is used each
time a specific tagged Template is evaluated. Whether call site objects are created lazily upon first evaluation of
the TemplateLiteral or eagerly prior to first evaluation is an implementation choice that is
not observable to ECMAScript code.
It is a Syntax Error if the lexical token sequence matched by CoverParenthesisedExpressionAndArrowParameterList cannot be parsed with no tokens left over using
ParenthesisedExpression as the goal symbol.
All Early Errors rules for ParenthesisedExpression and its derived productions also apply
to the CoveredParenthesisedExpression of CoverParenthesisedExpressionAndArrowParameterList.
Let expr be CoveredParenthesisedExpression of CoverParenthesisedExpressionAndArrowParameterList.
Return the result of evaluating expr.
ParenthesisedExpression:(Expression)
Return the result of evaluating Expression. This may be of type Reference.
NOTE This algorithm does not apply GetValue to the result of
evaluating Expression. The principal motivation for this is so that operators such as delete and
typeof may be applied to parenthesised expressions.
The dot notation is explained by the following syntactic conversion:
MemberExpression . IdentifierName
is identical in its behaviour to
MemberExpression [ <identifier-name-string> ]
and similarly
CallExpression . IdentifierName
is identical in its behaviour to
CallExpression [ <identifier-name-string> ]
where <identifier-name-string> is a string literal containing the same sequence of characters after
processing of Unicode escape sequences as the IdentifierName.
Let propertyNameString be ToString(propertyNameValue).
If the code matched by the syntactic production that is being evaluated is strict
mode code, let strict be true, else let strict be false.
Return a value of type Reference whose base value is bv and
whose referenced name is propertyNameString, and whose strict reference flag is strict.
CallExpression:CallExpression[Expression]
Is evaluated in exactly the same manner as MemberExpression:MemberExpression[Expression] except that the contained CallExpression is evaluated in step
1.
If tailCall is true, then perform the PrepareForTailCall abstract operation.
Let result be the result of calling the [[Construct]] internal method on constructor, passing
argList as the argument.
Assert: If tailCall is true, the above call of [[Construct]]
will not return here, but instead evaluation will continue with the resumption of leafCallerContext as the running execution context.
The abstract operation EvaluateCall takes as arguments a value ref, and a syntactic grammar production
arguments, and a Boolean argument tailPosition. It performs the following steps:
If tailPosition is true, then perform the PrepareForTailCall abstract operation.
Let result be the result of calling the [[Call]] internal method on func, passing thisValue as
the thisArgument and argList as the argumentsList.
Assert: If tailPosition is true, the above call will not
return here, but instead evaluation will continue with the resumption of leafCallerContext as the running execution context.
It is a Syntax Error if the source code parsed with this production is global code that is not eval code.
It is a Syntax Error if the source code parsed with this production is eval code and the source code is not being
processed by a direct call to eval that is contained in function code.
If tailCall is true, then perform the PrepareForTailCall abstract operation.
Let result be the result of calling the [[Construct]] internal method on constructor, passing
argList as the argument.
Assert: If tailCall is true, the above call of [[Construct]]
will not return here, but instead evaluation will continue with the resumption of leafCallerContext as the running execution context.
Return result.
CallExpression:superArguments
If the code matched by the syntactic production that is being evaluated is strict
mode code, let strict be true, else let strict be false.
Let propertyKey be the result of calling the GetMethodName concrete
method of env.
If propertyKey is undefined, then then throw a ReferenceError exception.
Return a value of type Reference that is a Super Reference whose base value is bv, whose referenced name is
propertyKey, whose thisValue is actualThis, and whose strict reference flag is strict.
Return a List whose length is one greater than the length of
precedingArgs and whose items are the items of precedingArgs, in order, followed at the end by
arg which is the last item of the new list.
It is a Syntax Error if the UnaryExpression is contained in strict code and the derived UnaryExpression is PrimaryExpression:IdentifierReference.
It is a Syntax Error if the derived UnaryExpression is PrimaryExpression : CoverParenthesisedExpressionAndArrowParameterList and derives a
production that, if used in place of UnaryExpression, would produce a Syntax Error according to these
rules. This rule is recursively applied.
NOTE The last rule means that expressions such as delete
(((foo))) produce early errors because of recursive application of the first rule.
Return the result of calling the DeleteBinding concrete method of bindings, providing GetReferencedName(ref) as the argument.
NOTE When a delete operator occurs within strict
mode code, a SyntaxError exception is thrown if its UnaryExpression is a direct
reference to a variable, function argument, or function name. In addition, if a delete operator occurs
within strict mode code and the property to be deleted has the attribute {
[[Configurable]]: false }, a TypeError exception is thrown.
Object (standard exotic and does not implement [[Call]])
"object"
Object (implements [[Call]])
"function"
Object (non-standard exotic and does not implement [[Call]])
Implementation-defined. May not be "undefined", "boolean", "number", "symbol", or "string".
NOTE Implementations are discouraged from defining new typeof result values for
non-standard exotic objects. If possible "object"should be used for such objects.
The production MultiplicativeExpression:MultiplicativeExpression@UnaryExpression , where
@ stands for one of the operators in the above definitions, is evaluated as follows:
Let left be the result of evaluating MultiplicativeExpression.
The * operator performs multiplication, producing the product of its operands. Multiplication is
commutative. Multiplication is not always associative in ECMAScript, because of finite precision.
The result of a floating-point multiplication is governed by the rules of IEEE 754 binary double-precision
arithmetic:
If either operand is NaN, the result is NaN.
The sign of the result is positive if both operands have the same sign, negative if the operands have different
signs.
Multiplication of an infinity by a zero results in NaN.
Multiplication of an infinity by an infinity results in an infinity. The sign is determined by the rule already
stated above.
Multiplication of an infinity by a finite nonzero value results in a signed infinity. The sign is determined by the
rule already stated above.
In the remaining cases, where neither an infinity nor NaN is involved, the product is computed and rounded to the
nearest representable value using IEEE 754 round-to-nearest mode. If the magnitude is too large to represent, the
result is then an infinity of appropriate sign. If the magnitude is too small to represent, the result is then a zero
of appropriate sign. The ECMAScript language requires support of gradual underflow as defined by IEEE 754.
The / operator performs division, producing the quotient of its operands. The left operand is the dividend
and the right operand is the divisor. ECMAScript does not perform integer division. The operands and result of all
division operations are double-precision floating-point numbers. The result of division is determined by the specification
of IEEE 754 arithmetic:
If either operand is NaN, the result is NaN.
The sign of the result is positive if both operands have the same sign, negative if the operands have different
signs.
Division of an infinity by an infinity results in NaN.
Division of an infinity by a zero results in an infinity. The sign is determined by the rule already stated
above.
Division of an infinity by a nonzero finite value results in a signed infinity. The sign is determined by the rule
already stated above.
Division of a finite value by an infinity results in zero. The sign is determined by the rule already stated
above.
Division of a zero by a zero results in NaN; division of zero by any other finite value results in zero,
with the sign determined by the rule already stated above.
Division of a nonzero finite value by a zero results in a signed infinity. The sign is determined by the rule
already stated above.
In the remaining cases, where neither an infinity, nor a zero, nor NaN is involved, the quotient is computed
and rounded to the nearest representable value using IEEE 754 round-to-nearest mode. If the magnitude is too large to
represent, the operation overflows; the result is then an infinity of appropriate sign. If the magnitude is too small
to represent, the operation underflows and the result is a zero of the appropriate sign. The ECMAScript language
requires support of gradual underflow as defined by IEEE 754.
The % operator yields the remainder of its operands from an implied division; the left operand is the
dividend and the right operand is the divisor.
NOTE In C and C++, the remainder operator accepts only integral operands; in ECMAScript, it
also accepts floating-point operands.
The result of a floating-point remainder operation as computed by the % operator is not the same as the
“remainder” operation defined by IEEE 754. The IEEE 754 “remainder” operation computes the
remainder from a rounding division, not a truncating division, and so its behaviour is not analogous to that of the usual
integer remainder operator. Instead the ECMAScript language defines % on floating-point operations to behave
in a manner analogous to that of the Java integer remainder operator; this may be compared with the C library function
fmod.
The result of an ECMAScript floating-point remainder operation is determined by the rules of IEEE arithmetic:
If either operand is NaN, the result is NaN.
The sign of the result equals the sign of the dividend.
If the dividend is an infinity, or the divisor is a zero, or both, the result is NaN.
If the dividend is finite and the divisor is an infinity, the result equals the dividend.
If the dividend is a zero and the divisor is nonzero and finite, the result is the same as the dividend.
In the remaining cases, where neither an infinity, nor a zero, nor NaN is involved, the floating-point
remainder r from a dividend n and a divisor d is defined by the mathematical relation r = n − (d × q)
where q is an integer that is negative only if n/d is negative and positive only if n/d is positive, and whose
magnitude is as large as possible without exceeding the magnitude of the true mathematical quotient of n and d. r is
computed and rounded to the nearest representable value using IEEE 754 round-to-nearest mode.
If Type(lprim) is String or Type(rprim) is String, then
Return the String that is the result of concatenating ToString(lprim)
followed by ToString(rprim)
Return the result of applying the addition operation to ToNumber(lprim) and ToNumber(rprim). See the Note below 12.6.5.
NOTE 1 No hint is provided in the calls to ToPrimitive in
steps 7 and 9. All standard objects except Date objects handle the absence of a hint as if the hint Number were given;
Date objects handle the absence of a hint as if the hint String were given. Exotic objects may handle the absence of a
hint in some other manner.
NOTE 2 Step 11 differs from step 5 of the Abstract Relational Comparison algorithm (7.2.8), by using the logical-or operation instead of the logical-and
operation.
The + operator performs addition when applied to two operands of numeric type, producing the sum of the
operands. The - operator performs subtraction, producing the difference of two numeric operands.
Addition is a commutative operation, but not always associative.
The result of an addition is determined using the rules of IEEE 754 binary double-precision arithmetic:
If either operand is NaN, the result is NaN.
The sum of two infinities of opposite sign is NaN.
The sum of two infinities of the same sign is the infinity of that sign.
The sum of an infinity and a finite value is equal to the infinite operand.
The sum of two negative zeroes is −0. The sum of two positive zeroes, or of two zeroes of opposite sign,
is +0.
The sum of a zero and a nonzero finite value is equal to the nonzero operand.
The sum of two nonzero finite values of the same magnitude and opposite sign is +0.
In the remaining cases, where neither an infinity, nor a zero, nor NaN is involved, and the operands have the same
sign or have different magnitudes, the sum is computed and rounded to the nearest representable value using IEEE 754
round-to-nearest mode. If the magnitude is too large to represent, the operation overflows and the result is then an
infinity of appropriate sign. The ECMAScript language requires support of gradual underflow as defined by IEEE 754.
NOTE The - operator performs subtraction when applied to two operands of numeric
type, producing the difference of its operands; the left operand is the minuend and the right operand is the subtrahend.
Given numeric operands a and b, it is always the case that a–b
produces the same result as a+(–b).
Let shiftCount be the result of masking out all but the least significant 5 bits of rnum, that is,
compute rnum & 0x1F.
Return the result of performing a sign-extending right shift of lnum by shiftCount bits. The most
significant bit is propagated. The result is a signed 32-bit integer.
Let shiftCount be the result of masking out all but the least significant 5 bits of rnum, that is,
compute rnum & 0x1F.
Return the result of performing a zero-filling right shift of lnum by shiftCount bits. Vacated bits
are filled with zero. The result is an unsigned 32-bit integer.
NOTE The result of evaluating a relational operator is always of type Boolean, reflecting
whether the relationship named by the operator holds between its two operands.
12.8.4
Runtime Semantics: InstanceofOperator(O, C)
The abstract operation InstanceofOperator(O, C)
implements the generic algorithm for determining if an object O inherits from the inheritance path defined by
constructor C. This abstract operation performs the following steps:
If Type(C) is not Object, throw a TypeError
exception.
Let instOfHandler be the result of GetMethod(C,@@hasInstance).
Let result be the result of calling the [[Call]] internal method of instOfHandler passing C
as thisArgument and a new List containing O as
argumentsList.
NOTE Steps 5 and 6 provide compatibility with previous editions of ECMAScript that did not use
a @@hasInstance method to define the instanceof operator semantics. If a function object does not define or
inherit @@hasInstance it uses the default instanceof semantics.
NOTE The result of evaluating an equality operator is always of type Boolean, reflecting
whether the relationship named by the operator holds between its two operands.
Let r be the result of performing Strict Equality Comparison rval === lval.
If r is true, return false. Otherwise, return true.
NOTE 1 Given the above definition of equality:
String comparison can be forced by: "" + a == "" + b.
Numeric comparison can be forced by: +a == +b.
Boolean comparison can be forced by: !a == !b.
NOTE 2 The equality operators maintain the following invariants:
A!=B is equivalent to !(A==B).
A==B is equivalent to B==A, except
in the order of evaluation of A and B.
NOTE 3 The equality operator is not always transitive. For example, there might be two distinct
String objects, each representing the same String value; each String object would be considered equal to the String value
by the == operator, but the two String objects would not be equal to each other. For Example:
new String("a")=="a" and "a"==new
String("a")are both true.
new String("a")==new String("a") is false.
NOTE 4 Comparison of Strings uses a simple equality test on sequences of code unit values.
There is no attempt to use the more complex, semantically oriented definitions of character or string equality and
collating order defined in the Unicode specification. Therefore Strings values that are canonically equal according to the
Unicode standard could test as unequal. In effect this algorithm assumes that both Strings are already in normalised
form.
NOTE The value produced by a && or || operator is not
necessarily of type Boolean. The value produced will always be the value of one of the two operand expressions.
NOTE The grammar for a ConditionalExpression in ECMAScript is slightly different from that in C
and Java, which each allow the second subexpression to be an Expression but restrict the third expression to be a
ConditionalExpression. The motivation for this difference in ECMAScript is to allow an assignment expression to be
governed by either arm of a conditional and to eliminate the confusing and fairly useless case of a comma expression as
the centre expression.
It is a Syntax Error if LeftHandSideExpression is either an ObjectLiteral or an ArrayLiteral and if the lexical token sequence matched by
LeftHandSideExpression cannot be parsed with no tokens left over using AssignmentPattern as the goal symbol.
If LeftHandSideExpression is either an ObjectLiteral or an ArrayLiteral and if the lexical token sequence matched by LeftHandSideExpression can be parsed with no tokens left over using AssignmentPattern as the goal symbol then the following rules are not applied. Instead, the Early
Error rules for AssignmentPattern are used.
It is a Syntax Error if LeftHandSideExpression is an Identifier that
can be statically determined to always resolve to a declarative
environment record binding and the resolved binding is an immutable binding.
It is an early Reference Error if LeftHandSideExpression is neither an ObjectLiteral nor an ArrayLiteral and IsValidSimpleAssignmentTarget of
LeftHandSideExpression is false.
It is a Syntax Error if the LeftHandSideExpression is an IdentifierReference that can be statically determined to always resolve to a declarative environment record binding and the resolved binding is an
immutable binding.
It is an early Reference Error if IsValidSimpleAssignmentTarget(LeftHandSideExpression) is false.
NOTE When an assignment occurs within strict mode code, it
is an runtime error if lref in step 1.f.of the first algorithm or step 9 of the second algorithm it is an
unresolvable reference. If it is, a ReferenceError exception is thrown. The LeftHandSide
also may not be a reference to a data property with the attribute value {[[Writable]]:false}, to an accessor property with the attribute value {[[Set]]:undefined}, nor to a non-existent property of an object for which the IsExtensible predicate returns the value false. In these cases a TypeError
exception is thrown.
In certain circumstances when processing the production AssignmentExpression:LeftHandSideExpression=AssignmentExpression the following grammar is used to refine the interpretation of LeftHandSideExpression.
It is a Syntax Error if LeftHandSideExpression is either an ObjectLiteral or an ArrayLiteral and if the lexical token sequence matched
by LeftHandSideExpression cannot be parsed with no tokens left over using AssignmentPattern as the goal symbol.
It is a Syntax Error if LeftHandSideExpression is neither an ObjectLiteral nor an ArrayLiteral and IsValidSimpleAssignmentTarget(LeftHandSideExpression) is false.
It is a Syntax Error if LeftHandSideExpression is an IdentifierReference that can be statically determined to always resolve to a declarative environment record binding and the resolved binding is an
immutable binding.
It is a Syntax Error if LeftHandSideExpression is CoverParenthesisedExpressionAndArrowParameterList:(Expression) and Expression derives a production that would produce a Syntax Error according to these rules if that
production is substituted for LeftHandSideExpression. This rule is recursively applied.
NOTE The last rule means that the other rules are applied even if multiple levels of nested
parenthesises surround Expression.
If AssignmentRestElement is present, then return the result of performing
IteratorDestructuringAssignmentEvaluation of AssignmentRestElement with iterator as the argument.
If DestructuringAssignmentTarget is an ObjectLiteral or an ArrayLiteral then
Let nestedAssignmentPattern be the parse of the source code corresponding to
DestructuringAssignmentTarget using either AssignmentPattern or
AssignmentPattern[Yield] as the goal symbol depending upon whether this
AssignmentElement has the Yield parameter.
If Type(v) is not Object, then throw a
TypeError exception.
Return the result of performing DestructuringAssignmentEvaluation of nestedAssignmentPattern with
v as the argument.
NOTE Left to right evaluation order is maintained by evaluating a DestructuringAssignmentTarget that is not a destruturing pattern prior to accessing the iterator or
evaluating the Initialiser.
If DestructuringAssignmentTarget is an ObjectLiteral or an ArrayLiteral then
Let AssignmentPattern be the parse of the source code corresponding to
DestructuringAssignmentTarget using either AssignmentPattern or
AssignmentPattern[?Yield] as the goal symbol depending upon whether this
AssignmentElement has the Yield parameter.
If Type(v) is not Object, then throw a
TypeError exception.
Return the result of performing DestructuringAssignmentEvaluation of AssignmentPattern with v as
the argument.
Let lref be the result of evaluating DestructuringAssignmentTarget.
NOTE Steps 5 and 6 of the above algorithm ensure that the value of a StatementList is the value of the last value producing Statement in the StatementList. For example, the following calls to the eval function all return the value
1:
NOTE When a Block or CaseBlock production is
evaluated a new Declarative Environment Record is created and bindings
for each block scoped variable, constant, or function declarated in the block are instantiated in the environment
record.
Block Declaration Instantiation is performed as follows using arguments code and env.
code is the grammar production corresponding to the body of the block. env is the declarative environment record in which bindings are to be created.
Let declarations be the LexicalDeclarations of code.
NOTE A let and const declarations define variables that are scoped
to the running execution context’s LexicalEnvironment. The variables are created when their containing Lexical Environment is instantiated but may not be accessed in any way until the
variable’s LexicalBinding is evaluated. A variable defined by a LexicalBinding with an Initialiser is assigned the value of its Initialiser’sAssignmentExpression when
the LexicalBinding is evaluated, not when the variable is created. If a LexicalBinding in a let declaration does not have an Initialiser
the variable is assigned the value undefined when the LexicalBinding is evaluated.
It is a Syntax Error if the BoundNames of BindingIdentifier contains
"let".
It is a Syntax Error if Initialiser is not present and IsConstantDeclaration of the LexicalDeclaration containing this production is true.
BindingIdentifier:yield
It is a Syntax Error if this production is contained in strict code.
It is a Syntax Error if this production is contained within the FunctionBody of a GeneratorMethod, GeneratorDeclaration, or GeneratorExpression.
BindingIdentifier:Identifier
It is a Syntax Error if the BindingIdentifier is contained in strict code and if the Identifier is: arguments,
eval, implements, interface, let, package,
private, protected, public, or static.
NOTEundefined is passed for environment to indicate that a PutValue operation should be used to assign the initialisation value. This is the case for
var statements formal parameter lists of non-strict functions. In those cases a lexical binding is hosted
and preinitialised prior to evaluation of its initialiser.
NOTE A var statement declares variables that are scoped to the running execution context’s VariableEnvironment. Var variables are created when their containing Lexical Environment is instantiated and are initialised to undefined when
created. Within the scope of any VariableEnvironemnt a common Identifier may appear in more than
one VariableDeclaration but those declarations collective define only one variable. A variable
defined by a VariableDeclaration with an Initialiser is assigned the
value of its Initialiser’sAssignmentExpression when the VariableDeclaration is executed, not when the
variable is created.
NOTEundefined is passed for environment to indicate that a PutValue operation should be used to assign the initialisation value. This is the case for
var statements formal parameter lists of non-strict functions. In those cases a lexical binding is hosted
and preinitialised prior to evaluation of its initialiser.
VariableDeclaration:BindingIdentifier
Return the result of performing BindingInitialisation for BindingIdentifier passing value and
undefined as the arguments.
VariableDeclaration:BindingIdentifierInitialiser
Return the result of performing BindingInitialisation for BindingIdentifier passing value and
undefined as the arguments.
VariableDeclaration:BindingPatternInitialiser
Return the result of performing BindingInitialisation for BindingPattern passing value and
undefined as the arguments.
Return the result of performing BindingInitialisation for BindingIdentifier passing value and
undefined as the arguments.
NOTE If a VariableDeclaration is nested within a with statement and
the Identifier in the VariableDeclaration is the same as a property name of the binding
object of the with statement’s object environment record, then step
3 will assign value to the property instead of to the VariableEnvironment binding
of the Identifier.
NOTE When undefined is passed for environment it indicates that a PutValue operation should be used to assign the initialisation value. This is the case for
formal parameter lists of non-strict functions. In that case the formal parameter bindings are preinitialised in order
to deal with the possibility of multiple parameters with the same name.
NOTE When undefined is passed for environment it indicates that a PutValue operation should be used to assign the initialisation value. This is the case for
formal parameter lists of non-strict functions. In that case the formal parameter bindings are preinitialised in order
to deal with the possibility of multiple parameters with the same name.
With parameters obj, environment, and propertyName.
NOTE When undefined is passed for environment it indicates that a PutValue operation should be used to assign the initialisation value. This is the case for
formal parameter lists of non-strict functions. In that case the formal parameter bindings are preinitialised in order
to deal with the possibility of multiple parameters with the same name.
[lookahead ∉ {{, function, class, let [}]Expression[In, ?Yield];
NOTE An ExpressionStatement cannot start with an opening curly brace
because that might make it ambiguous with a Block. Also, an ExpressionStatement cannot start with the function or class keywords because
that would make it ambiguous with a FunctionDeclaration, a GeneratorDeclaration, or a ClassDeclaration. An ExpressionStatement cannot start with the two token sequence let [ because that would make
it ambiguous with a letLexicalDeclaration whose first LexicalBinding was an ArrayBindingPattern.
Each else for which the choice of associated if is ambiguous shall be associated with the
nearest possible if that would otherwise have no corresponding else.
If LoopContinues(exprValue,labelSet) is false, return
exprValue.
Return the result of performing ForBodyEvaluation with the first Expression as the testExpr argument,
the second Expression as the incrementExpr argument, Statement as the stmt argument, and
with labelSet.
Let varDcl be the result of evaluating VariableDeclarationList.
If LoopContinues(varDcl,labelSet) is false, return
varDcl.
Return the result of performing ForBodyEvaluation with the first Expression as the testExpr argument,
the second Expression as the incrementExpr argument, Statement as the stmt argument, and
with labelSet.
Let bodyResult be the result of performing ForBodyEvaluation with the first Expression as the
testExpr argument, the second Expression as the incrementExpr argument, Statement as the
stmt argument, and with labelSet.
It is a Syntax Error if LeftHandSideExpression is either an ObjectLiteral or an ArrayLiteral and if the lexical token sequence matched
by LeftHandSideExpression cannot be parsed with no tokens left over using AssignmentPattern as the goal symbol.
If LeftHandSideExpression is either an ObjectLiteral or an ArrayLiteral and if the lexical token sequence matched by LeftHandSideExpression can be parsed with no tokens left over using AssignmentPattern as the goal symbol then the following rules are not applied. Instead, the Early
Error rules for AssignmentPattern are used.
It is a Syntax Error if LeftHandSideExpression is a IdentifierReference that can be statically determined to always resolve to a declarative environment record binding and the resolved binding is an
immutable binding.
It is a Syntax Error if LeftHandSideExpression is neither an ObjectLiteral nor an ArrayLiteral and IsValidSimpleAssignmentTarget of LeftHandSideExpression is false.
It is a Syntax Error if the LeftHandSideExpression is CoverParenthesisedExpressionAndArrowParameterList:(Expression) and Expression derives a production that would produce a Syntax Error according to these rules if that
production is substituted for LeftHandSideExpression. This rule is recursively applied.
NOTE The last rule means that the other rules are applied even if multiple levels of nested
parenthesises surround Expression.
The abstract operation ForIn/OfExpressionEvaluation is called with arguments expr, iterationKind,
and labelSet. The value of iterationKind is either
enumerate or iterate.
Let exprRef be the result of evaluating the production that is expr.
The abstract operation ForIn/OfBodyEvaluation is called with arguments lhs, stmt, keys,lhsKind, and labelSet. The value of lhsKind is either assignment,
varBinding or lexicalBinding.
It is a Syntax Error if this production is not nested, directly or indirectly (but not crossing function boundaries),
within an IterationStatement.
ContinueStatement:continueNonResolvedIdentifier;
It is a Syntax Error if StringValue(NonResolvedIdentifier) does not appear in the CurrentLabelSet of an enclosing
(but not crossing function boundaries) IterationStatement.
It is a Syntax Error if this production is not nested, directly or indirectly (but not crossing function boundaries),
within an IterationStatement or a SwitchStatement.
BreakStatement:breakNonResolvedIdentifier;
It is a Syntax Error if StringValue(NonResolvedIdentifier)does not appear in the CurrentLabelSet of an enclosing
(but not crossing function boundaries) Statement.
NOTE A return statement causes a function to cease execution and return a value to
the caller. If Expression is omitted, the return value is undefined. Otherwise, the return
value is the value of Expression.
NOTE No matter how control leaves the embedded Statement, whether
normally or by some form of abrupt completion or exception, the LexicalEnvironment is always restored to its former state.
If clauseSelector.[[value]] is empty, then return Completion{[[type]]: clauseSelector.[[type]],
[[value]]: undefined, [[target]]: clauseSelector.[[target]]}.
Else, return clauseSelector.
Let found be the result of performing Strict Equality Comparison input ===
clauseSelector.
If found is true, then
Let R be the result of evaluating CaseClauseC.
If R.[[value]] is not empty, then let V =
R.[[value]].
If R is an abrupt completion, then return Completion{[[type]]: R.[[type]], [[value]]:
V, [[target]]: R.[[target]]}.
Let foundInB be false.
If found is false, then
Let B be a new List containing the CaseClause
items in the second CaseClauses, in source text order.
Repeat, letting C be in order each CaseClause in B
If foundInB is false, then
Let clauseSelector be the result of CaseSelectorEvaluation of C.
If clauseSelector.[[value]] is empty, then return
Completion{[[type]]:
clauseSelector.[[type]], [[value]]: undefined, [[target]]:
clauseSelector.[[target]]}.
Else, return clauseSelector.
Let foundInB be the result of performing Strict Equality Comparison input ===
clauseSelector.
If foundInB is true, then
Let R be the result of evaluating CaseClause C.
If R.[[value]] is not empty, then let V =
R.[[value]].
If R is an abrupt completion, then return
Completion{[[type]]: R.[[type]], [[value]]:
V, [[target]]: R.[[target]]}.
NOTE CaseSelectorEvaluation does not execute the associated StatementList. It simply evaluates the Expression and returns the value, which
the CaseBlock algorithm uses to determine which StatementList to start
executing.
NOTE A Statement may be prefixed by a label. Labelled statements are
only used in conjunction with labelled break and continue statements. ECMAScript has no
goto statement. A Statement can be part of a LabelledStatement, which itself can be part of a LabelledStatement, and so on.
The labels introduced this way are collectively referred to as the “current label set” when describing the
semantics of individual statements. A LabelledStatement has no semantic meaning other than the
introduction of a label to a label set. The label set of an IterationStatement or a SwitchStatement initially contains the single element empty. The label set of any other statement
is initially empty.
It is a Syntax Error if a LabelledStatement is enclosed by a LabelledStatement with the same IdentifierReference as the enclosed LabelledStatement. This does not apply to a LabelledStatement appearing within
the body of a FunctionDeclaration and a LabelledStatement that encloses,
directly or indirectly the FunctionDeclaration .
NOTE The try statement encloses a block of code in which an exceptional condition
can occur, such as a runtime error or a throw statement. The catch clause provides the
exception-handling code. When a catch clause catches an exception, its CatchParameter is bound to
that exception.
NOTEundefined is passed for environment to indicate that a PutValue operation should be used to assign the initialisation value. This is the case for
var statements formal parameter lists of non-strict functions. In those cases a lexical binding is hosted and
preinitialised prior to evaluation of its initialiser.
NOTE Evaluating the DebuggerStatement production may allow an
implementation to cause a breakpoint when run under a debugger. If a debugger is not present or active this statement has
no observable effect.
The production DebuggerStatement:debugger; is evaluated as follows:
If an implementation defined debugging facility is available and enabled, then
Perform an implementation defined debugging action.
Let result be an implementation defined Completion
value.
NOTE Various ECMAScript language elements cause the creation of ECMAScript function objects (9.1.14). Evaluation of such functions starts with the execution of their
[[Call]] internal method (9.2.1).
The following productions are used as an aid in specifying the semantics of certain ECMAScript language features. They
are not used when parsing ECMAScript source code.
FunctionBody:
ThrowTypeError
ThrowTypeError:
[empty]
14.1.1 Directive Prologues and the Use Strict Directive
A Directive Prologue is the longest sequence of ExpressionStatement productions occurring as the
initial StatementListItem productions of a FunctionBody or a ScriptBody and where each ExpressionStatement in the sequence consists entirely of
a StringLiteral token followed by a semicolon. The
semicolon may appear explicitly or may be inserted by automatic semicolon
insertion. A Directive Prologue may be an empty sequence.
A Use Strict Directive is an ExpressionStatement in a Directive Prologue whose StringLiteral is either the exact character sequences "usestrict" or
'usestrict'. A Use Strict Directive may not contain an EscapeSequence or LineContinuation.
A Directive Prologue may contain more than one Use Strict Directive. However, an implementation may issue a warning if
this occurs.
NOTE The ExpressionStatement productions of a Directive Prologue are
evaluated normally during evaluation of the containing production. Implementations may define implementation specific
meanings for ExpressionStatement productions which are not a Use Strict Directive and which occur
in a Directive Prologue. If an appropriate notification mechanism exists, an implementation should issue a warning if it
encounters in a Directive Prologue an ExpressionStatement that is not a Use Strict Directive and
which does not have a meaning defined by the implementation.
FunctionDeclaration:functionBindingIdentifier(FormalParameters){FunctionBody} and FunctionExpression:functionBindingIdentifieropt(FormalParameters){FunctionBody}
If the source code matching this production is strict code, the Early Error rules
for StrictFormalParameters:FormalParameters are applied.
It is a Syntax Error if IsSimpleParameterList of FormalParameters is false and any element of the BoundNames of FormalParameters also occurs in the VarDeclaredNames of
FunctionBody.
It is a Syntax Error if any element of the BoundNames of FormalParameters also occurs in the LexicallyDeclaredNames of FunctionBody.
NOTE The LexicallyDeclaredNames of a FunctionBody does not include identifiers bound using var or function declarations. Simple parameter
lists bind identifiers as VarDeclaredNames. Parameter lists that contain destructuring patterns, default value
initialisers, or a rest parameter bind identifiers as LexicallyDeclaredNames.
StrictFormalParameters:FormalParameters
It is a Syntax Error if BoundNames of FormalParameters
contains any duplicate elements.
FormalParameters:FormalParameterList
It is a Syntax Error if IsSimpleParameterList of FormalParameterList is false and BoundNames of
FormalParameterList contains any duplicate elements.
NOTE Multiple occurrences of the same Identifier in a FormalParamterList is only allowed for non-strict functions and generator functions that have simple
parameter lists.
FunctionStatementList:StatementList
It is a Syntax Error if the LexicallyDeclaredNames of StatementList contains any duplicate
entries.
It is a Syntax Error if any element of the LexicallyDeclaredNames of StatementList also
occurs in the VarDeclaredNames of StatementList.
NOTE The ExpectedArgumentCount of a FormalParameterList is the number of FormalParameters to the left of either the
rest parameter or the first FormalParameter with an Initialiser. A FormalParameter without an initialiser is allowed after the first parameter with an initialiser but such
parameters are considered to be optional with undefined as their default value.
FormalsList:FormalParameter
If HasInitialiser of FormalParameter is false return 0
Return 1.
FormalsList:FormalsList,FormalParameter
Let count be the ExpectedArgumentCount of FormalsList.
If HasInitialiser of FormalsList is true or HasInitialiser of FormalParameter is true,
then return count.
NOTE When undefined is passed for environment it indicates that a PutValue operation should be used to assign the initialisation value. This is the case for
formal parameter lists of non-strict functions. In that case the formal parameter bindings are preinitialised in order to
deal with the possibility of multiple parameters with the same name.
Let closure be the result of performing the FunctionCreate abstract operation
with arguments Normal, FormalParameters, FunctionBody, scope, and strict.
If ReferencesSuper of FunctionExpression is true, then
NOTE 1 The BindingIdentifier in a FunctionExpression can be referenced from inside the FunctionExpression'sFunctionBody to allow the function to call itself recursively. However, unlike in a FunctionDeclaration, the BindingIdentifier in a FunctionExpression cannot be referenced from and does not affect the scope enclosing the FunctionExpression.
NOTE 2 A prototype property is automatically created for every function defined
using a FunctionDeclaration or FunctionExpression, to allow for the
possibility that the function will be used as a constructor.
When processing the production ArrowParameters:CoverParenthesisedExpressionAndArrowParameterList the following grammar is used to refine the
interpretation of CoverParenthesisedExpressionAndArrowParameterList.
It is a Syntax Error if the lexical token sequence matched by CoverParenthesisedExpressionAndArrowParameterList cannot be parsed with no tokens left over using
ArrowFormalParameters as the goal symbol.
It is a Syntax Error if any early errors are present for CoveredFormalsList of CoverParenthesisedExpressionAndArrowParameterList.
Return the result of parsing the lexical token stream matched by
CoverParenthesisedExpressionAndArrowParameterList using ArrowFormalParameters as the goal symbol.
NOTE When undefined is passed for environment it indicates that a PutValue operation should be used to assign the initialisation value. This is the case for
formal parameter lists of non-strict functions. In that case the formal parameter bindings are preinitialised in order to
deal with the possibility of multiple parameters with the same name.
The code of this ConciseBody is strict mode code if it is contained in strict mode code or if any of the conditions in 10.2.1 apply. If the code of this ConciseBody is strict mode code, AssignmentExpression is evaluated in the following steps as
strict mode code. Otherwise, AssignmentExpression is evaluated in the
following steps as non-strict mode code.
Let exprRef be the result of evaluating AssignmentExpression.
If the code of this ArrowFunction is contained in strict mode code or if
any of the conditions in 10.2.1 apply, then let strict be true.
Otherwise let strict be false.
Let parameters be CoveredFormalsList of ArrowParameters.
Let closure be the result of performing the FunctionCreate abstract operation
with arguments Arrow, parameters, ConciseBody, scope, and strict.
Return closure.
NOTE Any reference to arguments, super, or this within
an ArrowFunction are resoved to their bindings in the lexically enclosing function. Even though an
ArrowFunction may contain references to super, the function object created in step 4
is not made into a method by performing MakeMethod. An ArrowFunction
that references super is always contained within a non-ArrowFunction and the
necessary state to implement super is accessible via the scope that is captured by the function
object of the ArrowFunction.
NOTE The single element of a PropertySetParameterList may not have a
default value Initialiser because set accessor are always called with an implicitly provided
argument.
It is a Syntax Error if IsSimpleParameterList of PropertySetParameterList is false and any element of the BoundNames of PropertySetParameterList also occurs in the VarDeclaredNames of FunctionBody.
It is a Syntax Error if IsSimpleParameterList of PropertySetParameterList is false and BoundNames of
PropertySetParameterList contains either ″eval″ or ″arguments″.
It is a Syntax Error if BoundNames of
PropertySetParameterList contains any duplicate elements.
It is a Syntax Error if any element of the BoundNames of PropertySetParameterList also occurs
in the LexicallyDeclaredNames of FunctionBody.
Let closure be the result of performing the FunctionCreate abstract operation
with arguments Method, StrictFormalParameters, FunctionBody, scope, and strict. If
functionPrototype was passed as a parameter then pass its value as the functionPrototype optional
argument of FunctionCreate.
If ReferencesSuper of MethodDefinition is true, then
Let formalParameterList be the production FormalParameters:[empty]
Let closure be the result of performing the FunctionCreate abstract operation
with arguments Method, formalParameterList, FunctionBody, scope, and strict.
If ReferencesSuper of MethodDefinition is true, then
Let closure be the result of performing the FunctionCreate abstract operation
with arguments Method, PropertySetParameterList, FunctionBody, scope, and strict.
If ReferencesSuper of MethodDefinition is true, then
NOTEYieldExpression cannot be used within the FormalParameters of a generator function because any expressions that are part of FormalParameters are evaluate before the resulting generator object is in a resumable state.
Supplemental Syntax
The following productions are used as an aid in specifying the semantics of certain ECMAScript language features. They
are not used when parsing ECMAScript source code.
GeneratorBody:
FunctionBody
Comprehension
NOTE: Abstract operations relating to generator objects are defined in 25.3.3.
It is a Syntax Error if any element of the BoundNames of StrictFormalParameters also occurs in the VarDeclaredNames of FunctionBody.
It is a Syntax Error if any element of the BoundNames of StrictFormalParameters also occurs in the LexicallyDeclaredNames of FunctionBody.
GeneratorDeclaration:function*BindingIdentifier(FormalParameters){FunctionBody} and GeneratorExpression:function*BindingIdentifieropt(FormalParameters){FunctionBody}
If the source code matching this production is strict code, the Early Error rules
for StrictFormalParameters:FormalParameters are applied.
It is a Syntax Error if IsSimpleParameterList of FormalParameters is false and any element of the BoundNames of FormalParameters also occurs in the VarDeclaredNames
of FunctionBody.
It is a Syntax Error if any element of the BoundNames of FormalParameters also occurs in the LexicallyDeclaredNames of FunctionBody.
Let G be the result of calling the GetThisBinding concrete method of env.
If Type(G) is not Object or if Type(G) is Object and G does not have a
[[GeneratorState]] internal slot or if Type(G) is Object and G has a [[GeneratorState]] internal slot and the value of G’s
[[GeneratorState]] internal slot is not
undefined, then
Let newG be the result of calling OrdinaryCreateFromConstructor(functionObject,
"%GeneratorPrototype%", ( [[GeneratorState]], [[GeneratorContext]]) ).
Using FunctionBody from the production that is being evaluated, let body be the supplemental syntactic
grammar production: GeneratorBody:FunctionBody .
Let F be the result of performing the GeneratorFunctionCreate
abstract operation with arguments Normal, FormalParameters, body, scope, and strict.
If ReferencesSuper of GeneratorDeclaration is true, then
Using FunctionBody from the production that is being evaluated, let body be the supplemental syntactic
grammar production: GeneratorBody:FunctionBody .
Let closure be the result of performing the GeneratorFunctionCreate
abstract operation with arguments Method, StrictFormalParameters, body, scope, and strict.
If ReferencesSuper of GeneratorMethod is true, then
If the GeneratorExpression is contained in strict code or if its
FunctionBody is strict code, then let strict be true.
Otherwise let strict be false.
Using FunctionBody from the production that is being evaluated, let body be the supplemental syntactic
grammar production: GeneratorBody:FunctionBody .
Let closure be the result of performing the GeneratorFunctionCreate
abstract operation with arguments Normal, FormalParameters, body, scope, and strict.
If ReferencesSuper of GeneratorExpression is true, then
If the GeneratorExpression is contained in strict code or if its
FunctionBody is strict code, then let strict be true.
Otherwise let strict be false.
Using FunctionBody from the production that is being evaluated, let body be the supplemental syntactic
grammar production: GeneratorBody:FunctionBody .
Call the CreateImmutableBinding concrete method of envRec passing name as the argument.
Let closure be the result of performing the GeneratorFunctionCreate
abstract operation with arguments Normal, FormalParameters, body, funcEnv, and strict.
If ReferencesSuper of GeneratorExpression is true, then
Let prototype be the result of the abstract operation ObjectCreate with the
intrinsic object %GeneratorPrototype% as its argument.
Perform the abstract operation MakeConstructor with arguments closure,
true, and prototype.
Call the InitialiseBinding concrete method of envRec passing name and closure as the
arguments.
Return closure.
NOTE 1 The BindingIdentifier in a GeneratorExpression can be referenced from inside the GeneratorExpression'sFunctionBody to allow the generator code to call itself recursively. However, unlike in a GeneratorDeclaration, the BindingIdentifier in a GeneratorExpression cannot be referenced from and does not affect the scope enclosing the GeneratorExpression.
It is a Syntax Error if PrototypePropertyNameList of ClassElementListcontains any duplicate entries, unless the following condition is true for each
duplicate entry: The duplicated entry occurs exactly twice in the list and one occurrence was obtained from a
get accessor MethodDefinition and the other occurrence was obtained from a
set accessor MethodDefinition.
It is a Syntax Error if StaticPropertyNameList of ClassElementListcontains any duplicate entries, unless the following condition is true for each
duplicate entry: The duplicated entry occurs exactly twice in the list and one occurrence was obtained from a
get accessor MethodDefinition and the other occurrence was obtained from a
set accessor MethodDefinition.
ClassElement:MethodDefinition
It is a Syntax Error if PropName of MethodDefinitionis″constructor″andSpecialMethod of
MethodDefinition is true.
ClassElement:staticMethodDefinition
It is a Syntax Error if PropName of MethodDefinitionis″prototype″.
If ClassElement is the production ClassElement:; then, return empty.
If IsStatic of ClassElement is true, return empty.
If PropName of ClassElement is not ″constructor″, return
empty.
Return ClassElement.
ClassElementList:ClassElementListClassElement
Let head be ConstructorMethod of ClassElementList.
If head is not empty, return head.
If ClassElement is the production ClassElement:; then, return empty.
If IsStatic of ClassElement is true, return empty.
If PropName of ClassElement is not ″constructor″, return
empty.
Return ClassElement.
NOTE Early Error rules ensure that there is only one method definition named ″constructor″ and that it is not an accessor property or generator
definition.
Let constructor be ConstructorMethod of ClassBody.
If constructor is empty, then
If ClassHeritageopt is present, then
Let constructor be the result of parsing the String "constructor(... args){return super(...args);}" using the syntactic grammar with the goal symbol MethodDefinition.
Else,
Let constructor be the result of parsing the String "constructor( ){ }" using the
syntactic grammar with the goal symbol MethodDefinition.
Let strict be true.
Let constructorInfo be the result of performing DefineMethod for constructor with arguments proto
and constructorParent as the optional functionPrototype argument.
Let F be constructorInfo.[[closure]]
Perform the abstract operation MakeConstructor with argument F and
false as the optional writablePrototype argument and proto as the optional prototype
argument.
If className is not undefined, then
Call the InitialiseBinding concrete method of envRec passing className and F as the
arguments.
Let desc be the PropertyDescriptor{[[Enumerable]]: false, [[Writable]]: true, [[Configurable]]:
true}.
Call the [[DefineOwnProperty]] internal method of proto with arguments "constructor" and
desc
Let protoMethods be PrototypeMethodDefinitions of ClassBody.
For each MethodDefinitionm in order from protoMethods
Let status be the result of performing PropertyDefinitionEvaluation for m with argument
proto.
Assert: nonterminal is a parsed grammar production.
If the source code matching nonterminal is not strict code, then return
false.
If nonterminal is not contained within a FunctionBody or ConciseBody, then return
false.
Let body be the FunctionBody or ConciseBody that most closely contains nonterminal.
If body is the FunctionBody of a GeneratorMethod, GeneratorDeclaration, or a
GeneratorExpression, then return false.
Return the result of HasProductionInTailPosition of body with argument nonterminal.
NOTE Tail Position calls are only defined in strict mode
code because of a common non-standard language extension (see 9.2.8) that enables observation of the chain of caller contexts.
NOTE A potential tail position call that is immediately followed by return GetValue of the call result is also a possible tail position call. Functional calls can not
return reference values, so such a GetValue operation will always returns the same value as
the actual function call result.
A tail position call must either release any transient internal resources associated with the currently executing
function execution context before invoking the target function or reuse those
resources in support of the target function.
NOTE 1 For example, a tail position call should only grow an implementation’s
activication record stack by the amount that the size of the target function’s activation record exceeds the size of
the calling function’s activation record. If the target function’s activation record is smaller, then the
total size of the stack should decrease.
It is a Syntax Error if the LexicallyDeclaredNames of StatementList contains any duplicate
entries.
It is a Syntax Error if any element of the LexicallyDeclaredNames
of StatementList also occurs in the VarDeclaredNames of StatementList.
It is a Syntax Error if StatementListContainssuper.
NOTE Additional error conditions relating to conflicting or duplicate declarations are checked
during module linking prior to evaluation of a Script. If any such errors are detected the Script is not evaluated.
Let status be the result of performing GlobalDeclarationInstantiation as described in 15.1.8 using ScriptBody, globalEnv, and
deletableBindings as arguments.
NOTE The processes for initiating the evaluation of a Script and for
dealing with the result of such an evaluation are defined by an ECMAScript implementation and not by this
specification.
NOTE When an execution context is established for
evaluating scripts, declarations are instantiated in the current global environment. Each global binding declarated in
the code is instantiated.
GlobalDeclarationInstantiation is performed as follows using arguments script,env,and deletableBindings. script is the ScriptBody that for which
the execution context is being established. env is the global environment record in which bindings are to be created.
deletableBindings is true if the bindings that are created should be deletable.
Let strict be IsStrict of script.
Let lexNames be the LexicallyDeclaredNames of script.
Let varNames be the VarDeclaredNames of script.
For each name in lexNames, do
If the result of calling env’sHasVarDeclaration concrete method
passing name as the argument is true, throw a SyntaxError exception.
If the result of calling env’sHasLexicalDeclaration
concrete method passing name as the argument is true, throw a SyntaxError exception.
For each name in varNames, do
If the result of calling env’sHasLexicalDeclaration
concrete method passing name as the argument is true, throw a SyntaxError exception.
Let varDeclarations be the VarScopedDeclarations of script.
NOTE Early errors specified in 15.1.1
prevent name conflicts between function/var declarations and let/const/class/module declarations as well as redeclaration
of let/const/class/module bindings for declaration contained within a single Script. However, such
conflicts and redeclarations that span more than one Script are detected as runtime errors during
GlobalDeclarationInstantiation. If any such errors are detected, no bindings are instantiated for the script.
Unlike explicit var or function declarations, properties that are directly created on the global object result in
global bindings that may be shadowed by let, const, class, and module declarations.
It is a Syntax Error if the LexicallyDeclaredNames of ModuleItemList contains any duplicate
entries.
It is a Syntax Error if the ExportedBindings of ModuleItemList contains any duplicate
entries.
It is a Syntax Error if any element of the LexicallyDeclaredNames of ModuleItemList also
occurs in the VarDeclaredNames of ModuleItemList.
It is a Syntax Error if ModuleItemList Contains super.
NOTE Additional error conditions relating to conflicting or duplicate declarations are
checked during module linking prior to evaluation of a Module. If any such errors are detected
the Module is not evaluated.
An ModuleImport imports a module and introduces a single binding within the containing module
environment. The value of such a binding as a Module object.
A Module object is a ordinary/exotic object whose own properties corresponding corresponding to the ExportedBindings of
the module identifed by the ModuleImportFromClause. Each property name
is the StringValue of of the corresponding exported binding. These
are the only properties of an Module object. Each one is a read-only property with attributes {[[Configurable]]: false, [[Enumerable]]: true}. Module objects are not extensible.
TO DO
Needs to decide whether a module object is an ordinary or an exotic object. Whether
properties are accessor or defined via [[Get]], etc.
NOTEExportSpecifier is used to export bindings from the enclosing
module Module. ExportSpecifier[NoReference] is used to export bindings from a referenced Module. In that
case IdentifierReference restrictions are not applied to the naming of the items too be exported
because they are not used to create local bindings.
Loader Records contain the state of a of distinct module loading context. Each Loader Record has the fields defined
in Table 33. Loader objects (26.3) are ECMAScript objects that permit
ECMAScript code to define and manage module loading contexts.
The Realm associated with the loader. All scripts and modules evaluated by this loader run in the scope of the global object associated with this Realm.
Record {[[Name]], [[Module]]} where [[Name]] is a String and [[Module]] is a Module Record
Normalized names bound to fully linked Module records. The list can contain modules whose code has not yet been evaluated. However, except for the case of cyclic imports, such modules are not exposed to user code.
The abstract operation CreateLoaderRecord creates and returns a new Loader Record. The argument realm is
the Realm record that will be associated with Loader. The argument object is
the either undefined or the Loader object that will reflect this Loader record.
A List of all LinkSets that require this Load request to succeed. There is a many-to-many relation between Load records and LinkSets. A single import() call can have a large dependency tree, involving many Load records. Many import() calls, if they depend on the same module, can be waiting for a single Load to complete.
[[Metadata]]
Object
An object passed to each loader hook which hooks may use for any purpose.
[[Address]]
Object | undefined
The result of the locate hook.
[[Source]]
String | undefined
The result of the translate hook.
[[Kind]]
One of: undefined, dynamic, declarative
Once the Load reaches the "loaded" state, either declarative or dynamic. If the instantiate hook returned undefined, the module is declarative, and load.[[Body]] contains a Module parse. Otherwise, the instantiate hook returned a ModuleFactory object and [[Execute]] contains the .execute callable object.
[[Body]]
undefined or a parse result
If [[Kind]] is declarative, the parse of a Module production. Otherwise undefined.
[[Execute]]
If [[Kind]] is dynamic, the value of factory.execute. Otherwise undefined.
If [[Status]] is not "loading", a List of pairs. Each pair consists of two strings: a module name as it appears in a module, import, or export from declaration in load.[[Body]], and the corresponding normalized module name.
[[Exception]]
If [[Status]] is "failed", the exception value that was thrown, causing the load to fail. Otherwise, null.
[[Module]]
The Module object produced by this load, or undefined.
A LoadRequest object is an ordinary Object, inheriting from Object.prototype with own data properties
whose values corresponding certain fields of a corresonding Load Record. A LoadRequest object is created when the value
of those fields need to be passed to an ECMAScript function. Every LoadRequest object has name, and
metadata properties corresponding to the [[Name]] and [[Metadata]] fields of a Load Record. A LoadRequest
object may also have address and source properties corresponding to the [[Address]] and
[[Source]] fields of a Load record.
The abstract operation CreateLoad creates and returns a new Load Record. The argument name is either
undefined, indicating an anonymous module, or a normalized module name.
The abstract operation CreateLoadRequestObject performed with arguments name, metadata, and
optional arguments address and source returns a new LoadRequest Object. It performs the following
steps:
Let obj be the result of calling ObjectCreate(%ObjectPrototype%, ()).
Assert: The following operations will never result in abrupt
completions.
The RequestLoad abstract operation normalizes the given module name, request, and returns a Promise object
that resolves to the value of a Load object for the given module.
The loader argument is a Loader record.
request is the (non-normalized) name of the module to be imported, as it appears in the import-declaration
or as the argument to loader.load() or loader.import().
refererName and refererAddress provide information about the context of the
import() call or import-declaration. This information is passed to all the loader hooks.
If the requested module is already in the loader's module registry, RequestLoad returns a Promise object
for a Load with the [[Status]] field set to "linked". If the requested module is loading or loaded but not
yet linked, RequestLoad returns a Promise object for an existing Load object from loader.[[Loads]].
Otherwise, RequestLoad starts loading the module and returns a Promise object for a new Load Record.
The following steps are taken:
Let F be a new anonymous function as defined by CallNormalize.
Let refererName be the value of F’s [[RefererName]] internal slot.
Let refererAddress be the value of F’s [[RefererAddress]] internal slot.
Let loaderObj be loader.[[LoaderObj]].
Let normalizeHook be the result of Get(loaderObj,
"normalize").
Let name be the result of calling the [[Call]] internal method of normalizeHook passing
loaderObj and (request, refererName, refererAddress) as arguments.
A CallLocate function is an anonymous built-in function that calls the locate loader hook. Each
CallLocate function has [[Loader]] and [[Load]] internal slots.
When a CallLocate function F is called, the following steps are taken:
Let loader be the value of F’s [[Loader]] internal slot.
Let load be the value of F’s [[Load]] internal slot.
Let loaderObj be loader.[[LoaderObj]].
Let hook be the result of Get(loaderObj, "locate").
A CallFetch function is an anonymous built-in function that calls the fetch loader hook. Each CallFetch
function has [[Loader]] and [[Load]] internal slots.
When a CallFetch function F is called with argument address, the following steps are taken:
Let loader be the value of F’s [[Loader]] internal slot.
Let load be the value of F’s [[Load]] internal slot.
If load.[[LinkSets]] is an empty List, return
undefined.
Set load.[[Address]] to address.
Let loaderObj be loader.[[LoaderObj]].
Let hook be the result of Get(loaderObj, "fetch").
The ProceedToTranslate abstract operation continues the asynchronous loading process at the translate
hook hook by performing performs the following steps:
Let F be a new function object as defined in CallTranslate.
A CallTranslate function is an anonymous built-in function that calls the translate loader hook. Each
CallTranslate function has [[Loader]] and [[Load]] internal slots.
When a CallTranslate function F is called with argument source, the following steps are
taken:
Let loader be the value of F’s [[Loader]] internal slot.
Let load be the value of F’s [[Load]] internal slot.
If load.[[LinkSets]] is an empty List, return
undefined.
Let hook be the result of Get(loader, "translate").
A CallInstantiate function is an anonymous built-in function that calls the instantiateloaderhook. Each CallInstantiate function has [[Loader]] and [[Load]] internal slots.
When a CallInstantiate function F is called with argument source, the following steps are
taken:
Let loader be the value of F’s [[Loader]] internal slot.
Let load be the value of F’s [[Load]] internal slot.
If load.[[LinkSets]] is an empty List, return
undefined.
Set load.[[Source]] to source.
Let loaderObj be loader.[[LoaderObj]].
Let hook be the result of Get(loaderObj,
"instantiate").
An InstantiateSucceeded function is an anonymous function that handles the result of the instantiate
hook.
Each InstantiateSucceeded function has [[Loader]] and [[Load]] internal slots.
When an InstantiateSucceeded function F is called with argument instantiateResult, the
following steps are taken:
Let loader be the value of F’s [[Loader]] internal slot.
Let load be the value of F’s [[Load]] internal slot.
If load.[[LinkSets]] is an empty List, return
undefined.
If instantiateResult is undefined, then
Let body be the result of parsing load.[[Source]], interpreted as UTF-16 encoded Unicode text as
described in clause 10.1.1, using Module as the goal symbol. Throw a SyntaxError exception if the parse
fails or if any static semantics errors are detected.
The ProcessLoadDependencies abstract operation is called after one module has nearly finished loading. It starts new
loads as needed to load the module's dependencies.
ProcessLoadDependencies also arranges for LoadSucceeded to be called.
A LoadSucceeded function is an anonymous function that transitions a Load Record from "loading" to
"loaded" and notifies all associated LinkSet Records of the change. This
function concludes the loader pipeline. It is called after all a newly loaded module's dependencies are successfully
processed.
Each LoadSucceeded function has a [[Load]] internal
slot.
When a LoadSucceeded function F is called, the following steps are taken:
Let load be the value of F’s [[Load]] internal slot.
Let F be a new anonymous function object as defined in AsyncStartLoadPartwayThrough.
Let state be the Record { [[Step]]: "translate", [[Loader]]: loader, [[ModuleName]]:
name, [[ModuleMetadata]]: metadata, [[ModuleSource]]: source, [[ModuleAddress]]:
address}.
An AsyncStartLoadPartwayThrough function is an anonymous function that is used as a Promise executor. When called it
creates a new Load Record and populates it with some information provided by the caller, so that loading can proceed
from either the locate hook, the fetch hook, or the translate hook. This
functionality is used to implement builtin methods like Loader.prototype.load, which permits the user to specify both the
normalized module name and the address.
Each AsyncStartLoadPartwayThrough function has internal slots [[StepState]].
When an AsyncStartLoadPartwayThrough function F is called with arguments resolve and
reject, the following steps are taken:
Let state be the value of F’s [[StepState]] internal slot.
Let loader be state.[[Loader]].
Let name be state.[[ModuleName]].
Let step be state.[[Step]].
Let source be state.[[ModuleSource]].
Repeat for each Record {[[key]], [[value]]} p that is an element of loader.[[ Modules], do
If SameValue(p.[[key]], name) is true, then throw a
TypeError exception.
Repeat for element of load or loader.[[ Modules], do
If SameValue(loads.[[Name]], name) is true, then throw a
TypeError exception.
Let load be the result of calling the CreateLoad(name).
Set load.[[Metadata]] to state.[[ModuleMetadata]].
The AddLoadToLinkSet abstract operation associates a LinkSet Record with a Load Record and each of its currently
known dependencies, indicating that the LinkSet cannot be linked until those Loads have finished successfully.
The following steps are taken:
Assert: load.[[Status]] is either "loading" or
"loaded".
Let loader be linkSet.[[Loader]].
If load is not already an element of the ListlinkSet.[[Loads]],
Append load to the end of the ListlinkSet.[[Loads]].
Append linkSet to the end of the Listload.[[LinkSets]].
If load.[[Status]] is "loaded", then
Repeat for each r that is a Record {[[Name]], [[NormalisedName]]} in load.[[Dependencies]],
If there is no element of loader.[[ Modules]] whose [[key]] field is equal to name,
If there is an element of loader.[[Loads]] whose [[Name]] field is equal to name,
The UpdateLinkSetOnLoad abstract operation is called immediately after a Load successfully finishes, after starting
Loads for any dependencies that were not already loading, loaded, or in the module registry.
This operation determines whether linkSet is ready to link, and if so, calls Link.
The LinkSetFailed abstract operation is called when a LinkSet fails. It detaches the given LinkSet Record from all
Load Records and rejects the linkSet.[[Done]] Promise.
The FinishLoad Abstract Operation removes a completed Load Record from all LinkSets and commits the newly loaded
Module to the registry. It performs the following steps:
Let name be load.[[Name]].
If name is not undefined, then
Assert: There is no Record {[[key]], [[value]]} p that is an
element of loader.[[ Modules]], such that SameValue(p.[[key]],
load.[[Name]]) is true.
Append the Record {[[key]]: load.[[Name]], [[value]]: load.[[Module]]} as the last element of
loader.[[ Modules]].
If load is an element of the Listloader.[[Loads]], then
A load record load1 has a linkage
dependency on a load record load2 if load2 is contained in load1.[[UnlinkedDependencies]] or there exists a load record load in load1.[[UnlinkedDependencies]] such that load
has a linkage dependency on load2.
The linkage graph of a List, list, of load records is the set of load records load such
that some load record in list has a linkage dependency on load.
A dependency chain from load1 to
load2 is a List of load records demonstrating the transitive linkage dependency
from load1 to load2.
A dependency cycle is a dependency chain whose first and last elements’ [[Name]] fields have the
same value.
A dependency chain is cyclic if it contains a subsequence that is a dependency cycle. A dependency
chain is acyclic if it is not cyclic.
A dependency chain is mixed if there are two elements with distinct values for their [[Kind]] fields. A
dependency group transition of kind kind is a two-element subsequence load1, load2 of a dependency chain such that load1.[[Kind]] is not equal to kind and load2.[[Kind]] is equal to kind.
The dependency group count of a dependency chain with first element load1 is the number of distinct dependency group transitions of kind load1.[[Kind]].
Let otherMod be the result of calling the LookupModuleDependency abstract operation passing M and
modReq as arguments.
If entry.[[Module]] is null and entry.[[LocalName]] is not null and
boundNames does not contain entry.[[LocalName]], then the following steps are taken:
Add the record {[[Module]]: otherMod, [[ImportName]]: entry.[[ImportName]], [[LocalName]]:
entry.[[LocalName]], [[ExportName]]: entry.[[ExportName]], [[Explicit]]: true} to
defs.
For each modReq in M.[[UnknownExportEntries]], do
Let otherMod be the result of calling the LookupModuleDependency abstract operation passing M and
modReq as arguments.
If otherMod is in visited, then the following steps are taken:
Let error be a new Syntax Error.
Add error to M.[[LinkErrors]].
Otherwise the following steps are taken:
Add otherMod to visited.
Let otherDefs be the result of calling the ResolveExportEntries abstract operation passing
otherMod and visited as arguments.
For each def of otherDefs, do
Add the record {[[Module]]: otherMod, [[ImportName]]: def.[[ExportName]], [[LocalName]]:
null, [[ExportName]]: def.[[ExportName]], [[Explicit]]: false} to defs.
If overlappingDefs has more than one record def such that def.[[Explicit]] is true, or
if it has length greater than 1 but contains no records def such that def.[[Explicit]] is true,
then the following steps are taken:
Let error be a new Syntax Error.
Add error to M.[[LinkErrors]].
Return error.
Let def be the unique record in overlappingDefs such that def.[[Explicit]] is true, or
if there is no such record let def be the unique record in overlappingDefs.
If def.[[LocalName]] is not null, then the following steps are taken:
Let binding be the record {[[Module]]: M, [[LocalName]]: def.[[LocalName]]}.
Let export be the record {[[ExportName]]: exportName, [[Binding]]: binding}.
Add export to exports.
Return binding.
Add ref to visited.
Let binding be the result of calling the ResolveExport abstract operation passing def.[[Module]] and
def.[[ImportName]] as arguments.
Module bodies are evaluated on demand, as late as possible. The loader uses the function EnsureEvaluated, defined below, to run scripts. The loader always calls EnsureEvaluated before returning a Module object to user code.
There is one way a module can be exposed to script before its body has been evaluated. In the case of an import cycle,
whichever module is evaluated first can observe the others before they are evaluated. Simply put, we have to start
somewhere: one of the modules in the cycle must run before the others.
An EvaluateLoadedModule function is an anonymous function that is used by Loader.prototype.module and Loader.prototype.import to ensure that a module
has been evaluated before it is passed to script code.
Each EvaluateLoadedModule function has a [[Loader]] internal
slot.
When a EvaluateLoadedModule function F is called with argument load, the following steps are
taken:
The abstract operation EnsureEvaluated walks the dependency graph of the module mod, evaluating any module
bodies that have not already been evaluated (including, finally, mod itself). Modules are evaluated in
depth-first, left-to-right, post order, stopping at cycles.
mod and its dependencies must already be linked.
The Listseen is used to detect cycles. mod
must not already be in the Listseen.
On success, mod and all its dependencies, transitively, will have started to evaluate exactly once.
An implementation must report most errors at the time the relevant ECMAScript language construct is evaluated. An early
error is an error that can be detected and reported prior to the evaluation of any construct in the Script containing the error. An implementation must report early errors in a Script
prior to the first evaluation of that Script. Early errors in eval code are reported at the time
eval is called but prior to evaluation of any construct within the eval code. All errors that are not early
errors are runtime errors.
An implementation must treat as an early error any instance of an early error that is specified in a static
An implementation shall not treat other kinds of errors as early errors even if the compiler can prove that a construct
cannot execute without error under any circumstances. An implementation may issue an early warning in such a case, but it should
not report the error until the relevant construct is actually executed.
An implementation shall report all errors as specified, except for the following:
An implementation may extend script syntax and regular expression pattern or flag syntax. To permit this, all operations
(such as calling eval, using a regular expression literal, or using the Function or
RegExp constructor) that are allowed to throw SyntaxError are permitted to exhibit
implementation-defined behaviour instead of throwing SyntaxError when they encounter an implementation-defined
extension to the script syntax or regular expression pattern or flag syntax.
An implementation may provide additional types, values, objects, properties, and functions beyond those described in this
specification. This may cause constructs (such as looking up a variable in the global scope) to have implementation-defined
behaviour instead of throwing an error (such as ReferenceError).
An implementation may define behaviour other than throwing RangeError for toFixed,
toExponential, and toPrecision when the fractionDigits or precision argument
is outside the specified range.
There are certain built-in objects available whenever an ECMAScript Script begins execution. One, the
global object, is part of the lexical environment of the executing program. Others are
accessible as initial properties of the global object or indirectly as properties of accessible built-in objects.
Unless specified otherwise, a built-in object that is callable as a function is a Built-in Function object with the
characteristics described in 9.3. Unless specified otherwise, the [[Extensible]] internal slot of a built-in object initially has the value
true. Every built-in object has a [[Realm]] internal slot
whose value is the code Realm for which the object was initially created.
Many built-in objects are functions: they can be invoked with arguments. Some of them furthermore are constructors: they are
functions intended for use with the new operator. For each built-in function, this specification describes the
arguments required by that function and properties of the Function object. For each built-in constructor, this specification
furthermore describes properties of the prototype object of that constructor and properties of specific object instances
returned by a new expression that invokes that constructor.
Unless otherwise specified in the description of a particular function, if a built-in function or constructor is given fewer
arguments than the function is specified to require, the function or constructor shall behave exactly as if it had been given
sufficient additional arguments, each such argument being the undefined value.
Unless otherwise specified in the description of a particular function, if a built-in function or constructor described is
given more arguments than the function is specified to allow, the extra arguments are evaluated by the call and then ignored by
the function. However, an implementation may define implementation specific behaviour relating to such arguments as long as the
behaviour is not the throwing of a TypeError exception that is predicated simply on the presence of an extra
argument.
NOTE Implementations that add additional capabilities to the set of built-in functions are
encouraged to do so by adding new functions rather than adding new parameters to existing functions.
Unless otherwise specified every built-in function and every built-in constructor has the Function prototype object, which is
the initial value of the expression Function.prototype (19.2.3), as the value of its [[Prototype]] internal slot.
Unless otherwise specified every built-in prototype object has the Object prototype object, which is the initial value of the
expression Object.prototype (19.1.3), as the value of
its [[Prototype]] internal slot, except the Object prototype
object itself.
Built-in function objects that are not identified as constructors do not implement the [[Construct]] internal method unless
otherwise specified in the description of a particular function.
Unless otherwise specified, every built-in function defined in clauses 18 through 26 are created as if by calling the CreateBuiltinFunction abstract operation (9.3.1).
Every built-in Function object, including constructors, has a length property whose value is an integer. Unless
otherwise specified, this value is equal to the largest number of named arguments shown in the subclause headings for the
function description, including optional parameters.
NOTE For example, the Function object that is the initial value of the slice property of the String prototype object is described under the subclause heading “String.prototype.slice (start, end)” which shows the two named arguments start
and end; therefore the value of the length property of that Function object is
2.
Unless otherwise specified, the length property of a built-in Function object has the attributes
{ [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: true }.
Every built-in Function object, including constructors, that is not identified as an anonymous function has a
name property whose value is a String. Unless otherwise specified, this value is the name that is given to the
function in this specification. For functions that are specified as properties of objects, the name value is the property name
string used to access the function. Functions that are specified as get or set accessor functions of built-in properties have
"get " or "set " prepended to the property name string. The value of the name property
is explicitly specified for each built-in functions whose property key is a symbols value.
Unless otherwise specified, the name property of a built-in Function object has the attributes
{ [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: true }.
Every other data property described in clauses 18 through 26 has the attributes { [[Writable]]: true, [[Enumerable]]:
false, [[Configurable]]: true } unless otherwise specified.
Every accessor property described in clauses 18 through 26 has the attributes {[[Enumerable]]: false,
[[Configurable]]: true } unless otherwise specified. If only a get accessor function is described, the set accessor
function is the default value, undefined. If only a set accessor is function is described the get accessor is the
default value, undefined.
The unique global object is created before control enters any execution
context.
The global object does not have a [[Construct]] internal method; it is not possible to use the global object as a
constructor with the new operator.
The global object does not have a [[Call]] internal method; it is not possible to invoke the global object as a
function.
The value of the [[Prototype]] internal slot of the global
object is implementation-dependent.
In addition to the properties defined in this specification the global object may have additional host defined properties.
This may include a property whose value is the global object itself; for example, in the HTML document object model the
window property of the global object is the global object itself.
The value of undefined is undefined (see 6.1.1). This property has the attributes { [[Writable]]:
false, [[Enumerable]]: false, [[Configurable]]: false }.
Let script be the ECMAScript code that is the result of parsing x, interpreted as UTF-16 encoded
Unicode text as described in 10.1.1, for the goal symbol
Script. If the parse fails or any early errors are detected, throw a SyntaxError exception (but see also clause 16).
If script Contains ScriptBody is false, return undefined.
Let strictScript be IsStrict of script.
If this is a direct call to eval (18.2.1.1), let direct be
true, otherwise let direct be false.
If direct is true and the code that made the direct call to eval is strict code, then let strictCaller be true. Otherwise, let
strictCaller be false.
NOTE The eval code cannot instantiate variable or function bindings in the variable
environment of the calling context that invoked the eval if either the code of the calling context or the eval code is
strict code. Instead such bindings are instantiated in a new VariableEnvironment that is only accessible to the eval code.
A direct call to the eval function is one that is expressed as a CallExpression that meets all
of the following conditions:
The Reference that is the result of evaluating the MemberExpression
in the CallExpression has an environment record as its base value and its reference name is "eval".
If the base value of the Reference has true acalls its
withEnvironment value, then its binding object is an object that uses the ordinary definition of the [[Call]] internal
method (9.3.1)
The result of calling the abstract operation GetValue with that Reference as the argument is the standard built-in function defined in 18.2.1.
NOTE A reliable way for ECMAScript code to test if a value X is a NaN is an expression of the form X !== X. The
result will be true if and only if X is a NaN.
Let trimmedString be a substring of inputString consisting of the leftmost character that is not a
StrWhiteSpaceChar and all characters to the right of that character. (In other words, remove leading white
space.) If inputString does not contain any such characters, let trimmedString be the empty string.
If neither trimmedString nor any prefix of trimmedString satisfies the syntax of a
StrDecimalLiteral (see 7.1.3.1), return NaN.
Let numberString be the longest prefix of trimmedString, which might be trimmedString itself,
that satisfies the syntax of a StrDecimalLiteral.
Return the Number value for the MV of numberString.
NOTEparseFloat may interpret only a leading portion of string as a
Number value; it ignores any characters that cannot be interpreted as part of the notation of an decimal literal, and no
indication is given that any such characters were ignored.
The parseInt function produces an integer value dictated by interpretation of the contents of the
string argument according to the specified radix. Leading white space in string is ignored.
If radix is undefined or 0, it is assumed to be 10
except when the number begins with the character pairs 0x or 0X, in which case a radix of 16 is
assumed. If radix is 16, the number may also optionally begin
with the character pairs 0x or 0X.
When the parseInt function is called, the following steps are taken:
Let S be a newly created substring of inputString consisting of the first character that is not a
StrWhiteSpaceChar and all characters following that character. (In other words, remove leading white space.) If
inputString does not contain any such characters, let S be the empty string.
Let sign be 1.
If S is not empty and the first character of S is a minus sign -, let sign be
−1.
If S is not empty and the first character of S is a plus sign + or a minus sign -, then
remove the first character from S.
If the length of S is at least 2 and the first two characters of S are either
“0x” or “0X”, then remove the first two characters from S and let
R = 16.
If S contains any character that is not a radix-R digit, then let Z be the substring of S
consisting of all characters before the first such character; otherwise, let Z be S.
If Z is empty, return NaN.
Let mathInt be the mathematical integer value that is represented by Z in radix-R notation, using
the letters A-Z and a-z for digits with values 10 through 35. (However, if R is 10
and Z contains more than 20 significant digits, every significant digit after the 20th may be replaced by a
0 digit, at the option of the implementation; and if R is not 2, 4, 8, 10, 16, or 32, then
mathInt may be an implementation-dependent approximation to the mathematical integer value that is represented
by Z in radix-R notation.)
Let number be the Number value for mathInt.
Return sign × number.
NOTEparseInt may interpret only a leading portion of string as an
integer value; it ignores any characters that cannot be interpreted as part of the notation of an integer, and no
indication is given that any such characters were ignored.
Uniform Resource Identifiers, or URIs, are Strings that identify resources (e.g. web pages or files) and transport
protocols by which to access them (e.g. HTTP or FTP) on the Internet. The ECMAScript language itself does not provide any
support for using URIs except for functions that encode and decode URIs as described in 18.2.6.2, 18.2.6.3, 18.2.6.4 and 18.2.6.4.
NOTE Many implementations of ECMAScript provide additional functions and methods that
manipulate web pages; these functions are beyond the scope of this standard.
A URI is composed of a sequence of components separated by component separators. The general form is:
Scheme:First/Second;Third?Fourth
where the italicised names represent components and “:”, “/”,
“;” and “?” are reserved characters used as separators. The
encodeURI and decodeURI functions are intended to work with complete URIs; they assume that
any reserved characters in the URI are intended to have special meaning and so are not encoded. The
encodeURIComponent and decodeURIComponent functions are intended to work with the individual
component parts of a URI; they assume that any reserved characters represent text and so must be encoded so that they
are not interpreted as reserved characters when the component is part of a complete URI.
The following lexical grammar specifies the form of encoded URIs.
Syntax
uri:::
uriCharactersopt
uriCharacters:::
uriCharacteruriCharactersopt
uriCharacter:::
uriReserved
uriUnescaped
uriEscaped
uriReserved:::one of
;/?:@&=+$,
uriUnescaped:::
uriAlpha
DecimalDigit
uriMark
uriEscaped:::
%HexDigitHexDigit
uriAlpha:::one of
abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
uriMark:::one of
-_.!~*'()
NOTE The above syntax is based upon RFC 2396 and does not reflect changes introduced by the
more recent RFC 3986.
Runtime Semantics
When a character to be included in a URI is not listed above or is not intended to have the special meaning sometimes
given to the reserved characters, that character must be encoded. The character is transformed into its UTF-8 encoding,
with surrogate pairs first converted from UTF-16 to the corresponding code point value. (Note that for code units in the
range [0,127] this results in a single octet with the same value.) The resulting sequence of octets is then transformed
into a String with each octet represented by an escape sequence of the form “%xx”.
The unescaping and decoding process is described by the abstract operation Decode taking two String arguments
string and reservedSet.
Let strLen be the number of characters in string.
Let R be the empty String.
Let k be 0.
Repeat
If k equals strLen, return R.
Let C be the character at position k within string.
If C is not ‘%’, then
Let S be the String containing only the character C.
Else C is ‘%’,
Let start be k.
If k + 2 is greater than or equal to strLen, throw a URIError exception.
If the characters at position (k+1) and (k + 2) within string do not represent
hexadecimal digits, throw a URIError exception.
Let B be the 8-bit value represented by the two hexadecimal digits at position (k + 1) and
(k + 2).
Increment k by 2.
If the most significant bit in B is 0, then
Let C be the character with code unit value B.
If C is not in reservedSet, then
Let S be the String containing only the character C.
Else C is in reservedSet,
Let S be the substring of string from position start to position k
included.
Else the most significant bit in B is 1,
Let n be the smallest non-negative number such that (B << n) & 0x80 is
equal to 0.
If n equals 1 or n is greater than 4, throw a URIError exception.
Let Octets be an array of 8-bit integers of size n.
Put B into Octets at position 0.
If k + (3 × (n – 1)) is greater than or equal to strLen, throw a
URIError
exception.
Let j be 1.
Repeat, while j < n
Increment k by 1.
If the character at position k within string is not "%″, throw a
URIError
exception.
If the characters at position (k +1) and (k + 2) within string do not
represent hexadecimal digits, throw a URIError exception.
Let B be the 8-bit value represented by the two hexadecimal digits at position (k +
1) and (k + 2).
If the two most significant bits in B are not 10, throw a URIError exception.
Increment k by 2.
Put B into Octets at position j.
Increment j by 1.
Let V be the value obtained by applying the UTF-8 transformation to Octets, that is,
from an array of octets into a 21-bit value. If Octets does not contain a valid UTF-8 encoding
of a Unicode code point throw a URIError exception.
If V < 0x10000, then
Let C be the character with code unit value V.
If C is not in reservedSet, then
Let S be the String containing only the character C.
Else C is in reservedSet,
Let S be the substring of string from position start to position k
included.
Else V ≥ 0x10000,
Let L be (((V – 0x10000) & 0x3FF) + 0xDC00).
Let H be ((((V – 0x10000) >> 10) & 0x3FF) + 0xD800).
Let S be the String containing the two characters with code unit values H and
L.
Let R be a new String value computed by concatenating the previous value of R and S.
Increase k by 1.
NOTE This syntax of Uniform Resource Identifiers is based upon RFC 2396 and does not
reflect the more recent RFC 3986 which replaces RFC 2396. A formal description and implementation of UTF-8 is given
in RFC 3629.
In UTF-8, characters are encoded using sequences of 1 to 6 octets. The only octet of a "sequence" of one has the
higher-order bit set to 0, the remaining 7 bits being used to encode the character value. In a sequence of n octets,
n>1, the initial octet has the n higher-order bits set to 1, followed by a bit set to 0. The remaining bits of that
octet contain bits from the value of the character to be encoded. The following octets all have the higher-order bit set
to 1 and the following bit set to 0, leaving 6 bits in each to contain bits from the character to be encoded. The
possible UTF-8 encodings of ECMAScript characters are specified in Table 37.
to account for the addition of 0x10000 as in Surrogates, section 3.7, of the Unicode Standard.
The range of code unit values 0xD800-0xDFFF is used to encode surrogate pairs; the above transformation combines a
UTF-16 surrogate pair into a UTF-32 representation and encodes the resulting 21-bit value in UTF-8. Decoding
reconstructs the surrogate pair.
RFC 3629 prohibits the decoding of invalid UTF-8 octet sequences. For example, the invalid sequence C0 80 must not
decode into the character U+0000. Implementations of the Decode algorithm are required to throw a URIError when encountering such invalid
sequences.
The decodeURI function computes a new version of a URI in which each escape sequence and UTF-8 encoding of
the sort that might be introduced by the encodeURI function is replaced with the character that it
represents. Escape sequences that could not have been introduced by encodeURI are not replaced.
When the decodeURI function is called with one argument encodedURI, the following steps are
taken:
The decodeURIComponent function computes a new version of a URI in which each escape sequence and UTF-8
encoding of the sort that might be introduced by the encodeURIComponent function is replaced with the
character that it represents.
When the decodeURIComponent function is called with one argument encodedURIComponent, the
following steps are taken:
Let componentString be ToString(encodedURIComponent).
The encodeURI function computes a new version of a URI in which each instance of certain characters is
replaced by one, two, three, or four escape sequences representing the UTF-8 encoding of the character.
When the encodeURI function is called with one argument uri, the following steps
are taken:
The encodeURIComponent function computes a new version of a URI in which each instance of certain
characters is replaced by one, two, three, or four escape sequences representing the UTF-8 encoding of the character.
When the encodeURIComponent function is called with one argument uriComponent, the
following steps are taken:
The Object constructor is the %Object% intrinsic object and the initial value of the Object property of
the global object. When Object is called as a function rather than as a constructor, it performs a type
conversion.
The Object constructor is designed to be subclassable. It may be used as the value of an
extends clause of a class declaration.
NOTE Subclass constructors that inherit from the Object constructor typically should not
include a super call to Object as it performs no initialization action on its
this value and does not return its this value as its value.
When Object function is called with optional argument value, the following steps are taken:
If value is null, undefined or not supplied, return the result of the abstract operation ObjectCreate with the intrinsic object %ObjectPrototype% as its argument.
When Object is called as part of a new expression , it creates a new object:
Let F be the Object function object on which the new operator was applied.
Let argumentsList be the argumentsList argument of the [[Construct]] internal method that was invoked
by the new operator.
Return the result of calling the [[Call]] internal method of F, providing undefined and
argumentsList as the arguments.
The above steps defined the [[Construct]] internal method of the Object constructor. Object may not be implemented as
an ECMAScript function object because this definition differs from the
definition of [[Construct]] used by ECMAScript function objects.
The assign function is used to copy the values of all of the enumerable own properties from a source
object to a target object. When the assign function is called, the following steps are taken:
19.1.2.3 Object.defineProperties ( O, Properties )
The defineProperties function is used to add own properties and/or update the attributes of existing own
properties of an object. When the defineProperties function is called, the following steps are taken:
Return the result of the abstract operation ObjectDefineProperties with
arguments O and Properties.
If an implementation defines a specific order of enumeration for the for-in statement, that same enumeration order
must be used to order the list elements in step 3 of this algorithm.
NOTE An exception in defining an individual property in step 7 does not terminate the
process of defining other properties. All valid property definitions are processed.
19.1.2.4 Object.defineProperty ( O, P, Attributes )
The defineProperty function is used to add an own property and/or update the attributes of an existing own
property of an object. When the defineProperty function is called, the following steps are taken:
If Type(O) is not Object throw a TypeError
exception.
19.1.2.8.1 GetOwnPropertyKeys ( O, Type ) Abstract Operation
The abstract operation GetOwnPropertyKeys is called with arguments O and Type
where O is an Object and Type is one of the ECMAScript specification types String or
Symbol. The following steps are taken:
If an implementation defines a specific order of enumeration for the for-in statement, the same order must be used for
the elements of the array returned in step 8.
NOTE The ordering of steps 1 and 3 is chosen to ensure that any exception that would have
been thrown by step 1 in previous editions of this specification will continue to be thrown even if the this
value is undefined or null.
NOTE The ordering of steps 1 and 2 preserves the behaviour specified by previous editions of
this specification for the case where V is not an object and the this value is undefined or null.
Let desc be the result of calling the [[GetOwnProperty]] internal method of O passing P as the
argument.
If desc is undefined, return false.
Return the value of desc.[[Enumerable]].
NOTE 1 This method does not consider objects in the prototype chain.
NOTE 2 The ordering of steps 1 and 2 is chosen to ensure that any exception that would have
been thrown by step 1 in previous editions of this specification will continue to be thrown even if the this
value is undefined or null.
When the toLocaleString method is called, the following steps are taken:
Let O be the this value.
Return the result of Invoke(O, "toString").
NOTE 1 This function is provided to give all Objects a generic toLocaleString
interface, even though not all may use it. Currently, Array, Number, and Date
provide their own locale-sensitive toLocaleString methods.
NOTE 2 The first parameter to this function is likely to be used in a future version of this
standard; it is recommended that implementations do not use this parameter position for anything else.
If tag is any of "Arguments", "Array", "Boolean",
"Date", "Error", "Function", "Number",
"RegExp", or "String" and SameValue(tag,
builtinTag) is false, then let tag be the string value "~" concatenated with
the current value of tag.
Return the String value that is the result of concatenating the three Strings "[object ", tag, and "]".
NOTE Historically, this function was occasionally used to access the string value of the
[[Class]] internal slot that was used in previous editions
of this specification as a nominal type tag for various built-in objects. The above definition of toString
preserves the ability to use it as a reliable test for those specific kinds of built-in objects but it does not provide
a reliable type testing mechanism for other kinds of built-in or program defined objects.
The Function constructor is the %Function% intrinsic object and the initial value of the Function property
of the global object. When Function is called as a function rather than as a constructor, it creates and
initialises a new Function object. Thus the function call Function(…) is equivalent to the object creation expression new Function(…) with the same arguments. However, if the
this value passed in the call is an Object with a [[Code]] internal slot whose value is undefined, it initialises the this value using the argument values. This permits
Function to be used both as factory method and to perform constructor instance initialisation.
Function may be subclassed and subclass constructors may perform a super invocation of the
Function constructor to initialise subclass instances. However, all syntactic forms for defining function
objects create instances of Function. There is no syntactic means to create instances of
Function subclasses except for the built-in Generator Function subclass.
The last argument specifies the body (executable code) of a function; any preceding arguments specify formal
parameters.
When the Function function is called with some arguments p1, p2, … ,
pn, body (where n might be 0, that is,
there are no “p” arguments, and where body might also not be provided), the following
steps are taken:
Let argCount be the total number of arguments passed to this function invocation.
Let P be the empty String.
If argCount = 0, let bodyText be the empty String.
Else if argCount = 1, let bodyText be that argument.
Let parameters be the result of parsing P, interpreted as UTF-16 encoded Unicode text as described in
clause 10.1.1, using FormalParameters as the goal
symbol. Throw a SyntaxError exception if the parse fails.
Let body be the result of parsing bodyText, interpreted as UTF-16 encoded Unicode text as described in
clause 10.1.1, using FunctionBody as the goal
symbol. Throw a SyntaxError exception if the parse fails or if any static semantics errors are detected.
If IsSimpleParameterList of parameters is false and any element of the BoundNames of parameters
also occurs in the VarDeclaredNames of body, then throw a SyntaxError exception.
If any element of the BoundNames of parameters also occurs in the LexicallyDeclaredNames of body, then
throw a SyntaxError exception.
If bodyText is strict mode code (see 10.2.1) then let strict be true, else let strict be
false.
A prototype property is automatically created for every function created using the Function
constructor, to provide for the possibility that the function will be used as a constructor.
NOTE It is permissible but not necessary to have one argument for each formal parameter to be
specified. For example, all three of the following expressions produce the same result:
The Function constructor is itself a built-in Function object. The value of the [[Prototype]] internal slot of the Function constructor is
%FunctionPrototype%, the intrinsic Function prototype object (19.2.3).
The value of the [[Extensible]] internal slot of the
Function constructor is true.
The Function constructor has the following properties:
Let obj be the result of calling FunctionAllocate with arguments
proto and false.
Return obj.
The value of the name property of this function is "[Symbol.create]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: true }.
NOTE The Function @@create function passes false as
the strict parameter to FunctionAllocate. This causes the allocated ECMAScript function object to have the internal methods of a non-strict
function. The Function constructor may reset the functions [[Strict]] internal slot to true. It is up to
the implementation whether this also changes the internal methods.
19.2.3 Properties of the Function Prototype Object
The Function prototype object is itself a Built-in Function object. When invoked, it accepts any arguments and returns
undefined.
NOTE The Function prototype object is specified to be a function object to ensure
compatibility with ECMAScript code that was created prior to the 6th Edition of this specification.
The value of the [[Prototype]] internal slot of the
Function prototype object is the intrinsic object %ObjectPrototype% (19.1.3). The initial value of the [[Extensible]] internal slot of the Function prototype object is
true.
The Function prototype object does not have a prototype property.
The value of The length property of the Function prototype object is 0.
The value of the name property of the Function prototype object is the empty String.
Perform the PrepareForTailCall abstract operation.
Return the result of calling the [[Call]] internal method of func, providing thisArg as
thisArgument and argList as argumentsList.
The length property of the apply method is 2.
NOTE The thisArg value is passed without modification as the this value. This is a
change from Edition 3, where an undefined or null thisArg is replaced with the global object and ToObject is applied to all other values and that result is passed as the this value.
The bind method takes one or more arguments, thisArg and (optionally) arg1, arg2, etc,
and returns a new function object by performing the following steps:
Let Target be the this value.
If IsCallable(Target) is false, throw a TypeError exception.
Let A be a new (possibly empty) List consisting of all
of the argument values provided after thisArg (arg1, arg2 etc), in order.
Let F be the result of the abstract operation BoundFunctionCreate with
arguments Target, thisArg, and A.
Let L be the larger of 0 and the result of targetLen minus the number of elements of
A.
Else let L be 0.
Call the [[DefineOwnProperty]] internal method of F with arguments "length" and
PropertyDescriptor {[[Value]]: L, [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]:
true}.
If this method was called with more than one argument then in left to right order starting with arg1 append
each argument as the last element of argList
Perform the PrepareForTailCall abstract operation.
Return the result of calling the [[Call]] internal method of func, providing thisArg as
thisArgument and argList as argumentsList.
The length property of the call method is 1.
NOTE The thisArg value is passed without modification as the this value. This is a
change from Edition 3, where an undefined or null thisArg is replaced with the global object and ToObject is applied to all other values and that result is passed as the this value.
An implementation-dependent String source code representation of the this object is returned. This
representation has the syntax of a FunctionDeclarationFunctionExpression, GeneratorDeclaration, GeneratorExpession, ClassDeclaration,
ClassExpression, ArrowFunction, MethodDefinition, or GeneratorMethod depending upon the actual
characteristics of the object. In particular that the use and placement of white space, line terminators, and
semicolons within the representation String is implementation-dependent.
If the object was defined using ECMAScript code and the returned string representation is in the form of a FunctionDeclarationFunctionExpression,
GeneratorDeclaration, GeneratorExpession, ClassDeclaration, ClassExpression, or ArrowFunction
then the representation must be such that if the string is evaluated, using eval in a lexical context that is
equivalent to the lexical context used to create the original object, it will result in a new functionally equivalent
object. The returned source code must not mention freely any variables that were not mentioned freely by the original
function’s source code, even if these “extra” names were originally in scope. If the source code string
does meet these criteria then it must be a string for which eval will throw a SyntaxError
exception.
The toString function is not generic; it throws a TypeError exception if its this value does
not have a [[Call]] internal method. Therefore, it cannot be transferred to other kinds of objects for use as a
method.
The value of the name property of this function is "[Symbol.hasInstance]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false,
[[Configurable]]: false }.
NOTE This is the default implementation of @@hasInstance that most functions
inherit. @@hasInstance is called by the instanceof operator to deterimine whether a value is
an instance of a specific constructor. An expression such as
v instanceof F
evaluates as
F[@@hasInstance](v)
A constructor function can control which objects are recognised as its instances by instanceof by
exposing a different @@hasInstance method on the function.
This property is non-writable and non-configurable to prevent tampering that could be used to globally expose the
target function of a bound function.
Function instances that correspond to strict mode functions and function instances created using the Function.prototype.bind method (19.2.3.2) have properties named caller and
arguments that throw a TypeError exception. An ECMAScript implementation must not associate any
implementation specific behaviour with accesses of these properties from strict mode function code.
The Function instances have the following properties:
The value of the length property is an integer that indicates the typical number of arguments expected by
the function. However, the language permits the function to be invoked with some other number of arguments. The behaviour
of a function when invoked on a number of arguments other than the number specified by its length property
depends on the function. This property has the attributes { [[Writable]]: false, [[Enumerable]]: false,
[[Configurable]]: true }.
The value of the name property is an String that is descriptive of the function. The name has no semantic
significance but is typically a variable or property name that is used to refer to the function at its point of definition
in ECMAScript code. This property has the attributes { [[Writable]]: false, [[Enumerable]]: false,
[[Configurable]]: true }.
Anonymous functions objects that do not have a contextual name associated with them by this specification do not have a
name own property but inherit the name property of %FunctionPrototype%.
Function instances that can be used as a constructor have a prototype property. Whenever such a function
instance is created another ordinary object is also created and is the initial value of the function’s
prototype property. Unless otherwise specified, the value of the prototype property is used to initialise the
[[Prototype]] internal slot of a newly created ordinary
object before the Function object is invoked as a constructor for that newly created object.
This property has the attributes { [[Writable]]: true, [[Enumerable]]: false, [[Configurable]]:
false }.
NOTE Function objects created using Function.prototype.bind, or by evaluating a MethodDefinition (that is not a GeneratorMethod) or an ArrowFunction grammar production do not have a prototype property.
The Boolean constructor is the %Boolean% intrinsic object and the initial value of the Boolean property of
the global object. When Boolean is called as a function rather than as a constructor, it performs a type
conversion. However, if the this value passed in the call is an Object with an uninitialised [[BooleanData]] internal slot, it initialises the this value using the
argument value. This permits Boolean to be used both to perform type conversion and to perform constructor
instance initialisation.
The Boolean constructor is designed to be subclassable. It may be used as the value of an
extends clause of a class declaration. Subclass constructors that intended to inherit the specified
Boolean behaviour must include a super call to the Boolean constructor to
initialise the [[BooleanData]] state of subclass instances.
The value of the name property of this function is "[Symbol.create]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]:
true }.
NOTE [[BooleanData]] is initially assigned the value undefined as
a flag to indicate that the instance has not yet been initialised by the Boolean constructor. This flag value is never
directly exposed to ECMAScript code; hence implementations may choose to encode the flag in some other manner.
Boolean instances are ordinary objects that inherit properties from the Boolean prototype object. Boolean instances have
a [[BooleanData]] internal slot. The [[BooleanData]] internal slot is the Boolean value represented by this Boolean
object.
The Symbol constructor is the %Symbol% intrinsic object and the initial value of the Symbol property of
the global object. When Symbol is called as a function rather than as a constructor, it returns a new Symbol
value.
The Symbol constructor is not intended to be used with the new operator or to be subclassed.
It may be used as the value of an extends clause of a class declaration but a super call to the
Symbol constructor will not initialise the state of subclass instances.
For each element e of the GlobalSymbolRegistry List,
If SameValue(e.[[key]], stringKey) is true, then return
e.[[symbol]].
Assert: GlobalSymbolRegistry does not current contain an entry for
stringKey.
Let newSymbol be a new unique Symbol value whose [[Description]] is stringKey.
Append the record { [[key]]: stringKey, [[symbol]]: newSymbol) to the GlobalSymbolRegistry List.
Return newSumbol.
The GlobalSymbolRegistry is a List that is globally available.
It is shared by all Code Realms. Prior to the evaluation of any ECMAScript code it is initialised as an empty List. Elements of the GlobalSymbolRegistry are Records with the
structure defined in Table 38.
If s does not have a [[SymbolData]] internal
slot, then throw a TypeError exception.
Return the value of s’s [[SymbolData]] internal slot.
19.4.3.4 Symbol.prototype [ @@toPrimitive ] ( hint )
This function is called by ECMAScript language operators to convert an object to a primitive value. The allowed values
for hint are "default", "number", and "string". Implicit conversion of
Symbol objects to primitive values is not allowed.
When the @@toPrimitive method is called with argument hint, the following steps are taken:
Throw a TypeError exception.
The value of the name property of this function is "[Symbol.toPrimitive]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: true }.
Symbol instances are ordinary objects that inherit properties from the Symbol prototype object. Symbol instances have a
[[SymbolData]] internal slot. The [[SymbolData]] internal slot is the Symbol value represented by this Symbol
object.
Instances of Error objects are thrown as exceptions when runtime errors occur. The Error objects may also serve as base
objects for user-defined exception classes.
The Error constructor is the %Error% intrinsic object and the initial value of the Error property of the
global object. When Error is called as a function rather than as a constructor, it creates and initialises a
new Error object. Thus the function call Error(…) is
equivalent to the object creation expression new Error(…)
with the same arguments. However, if the this value passed in the call is an Object with an uninitialised
[[ErrorData]] internal slot, it initialises the this
value using the argument value rather than creating a new object. This permits Error to be used both as
factory method and to perform constructor instance initialisation.
The Error constructor is designed to be subclassable. It may be used as the value of an
extends clause of a class declaration. Subclass constructors that intended to inherit the specified
Error behaviour should include a super call to the Error constructor to initialise
subclass instances.
When the Error function is called with argument message the following steps are taken:
Let func be this Error function object.
Let O be the this value.
If Type(O) is not Object or Type(O) is Object and O does not have an
[[ErrorData]] internal slot or Type(O) is Object and O has an [[ErrorData]] internal slot and the value of [[ErrorData]] is not
undefined, then
The value of the name property of this function is "[Symbol.create]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: true }.
NOTE [[ErrorData]] is initially assigned the value undefined as a
flag to indicate that the instance has not yet been initialised by the Error constructor. This flag value is never
directly exposed to ECMAScript code; hence implementations may choose to encode the flag in some other manner.
Error instances are ordinary objects that inherit properties from the Error prototype object and have an [[ErrorData]] internal slot whose initial value is undefined. The only specified uses of [[ErrorData]] is to flag whether or not an Error instance has
been initialised by the Error constructor and to identify them as Error objects within Object.prototype.toString.
A new instance of one of the NativeError objects below is thrown when a runtime error is detected. All of these
objects share the same structure, as described in 19.5.6.
When an ECMAScript implementation detects a runtime error, it throws a new instance of one of the NativeError
objects defined in 19.5.5. Each of these objects has the
structure described below, differing only in the name used as the constructor name instead of NativeError, in the
name property of the prototype object, and in the implementation-defined message property of the
prototype object.
For each error object, references to NativeError in the definition should be replaced with the appropriate error
object name from 19.5.5.
When a NativeError constructor is called as a function rather than as a constructor, it creates and
initialises a new object. A call of the object as a function is equivalent to calling it as a constructor with the same
arguments. However, if the this value passed in the call is an Object with an uninitialised [[ErrorData]] internal slot, it initialises the this value using the
argument value. This permits a NativeError to be used both as factory method and to perform constructor instance
initialisation.
The NativeError constructor is designed to be subclassable. It may be used as the value of an
extends clause of a class declaration. Subclass constructors that intended to inherit the specified
NativeError behaviour should include a super call to the NativeError constructor to
initialise subclass instances.
When a NativeError function is called with argument message the following steps are taken:
Let func be this NativeError function object.
Let O be the this value.
If Type(O) is not Object or Type(O) is Object and O does not have an
[[ErrorData]] internal slot or Type(O) is Object and O has an [[ErrorData]] internal slot and the value of [[ErrorData]] is not
undefined, then
The actual value of the string passed in step 3.a is either "%EvalErrorPrototype%",
"%RangeErrorPrototype%", "%ReferenceErrorPrototype%", "%SyntaxErrorPrototype%",
"%TypeErrorPrototype%", or "%URIErrorPrototype%" corresponding to which NativeError
constructor is being defined.
The actual value passed as NativeErrorPrototype in step 2 is either
"%EvalErrorPrototype%", "%RangeErrorPrototype%", "%ReferenceErrorPrototype%",
"%SyntaxErrorPrototype%", "%TypeErrorPrototype%", or "%URIErrorPrototype%"
corresponding to which NativeError constructor is being defined.
The value of the name property of this function is "[Symbol.create]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: true }.
NOTE [[ErrorData]] is initially assigned the value undefined as
a flag to indicate that the instance has not yet been initialised by the NativeError constructor. This flag
value is never directly exposed to ECMAScript code; hence implementations may choose to encode the flag in some other
manner.
19.5.6.3 Properties of the NativeError Prototype Objects
Each NativeError prototype object is an ordinary object. It is not an Error instance and does not have an
[[ErrorData] internal slot.
The value of the [[Prototype]] internal slot of each
NativeError prototype object is the standard built-in Error prototype object (19.5.3).
The initial value of the constructor property of the prototype for a given NativeError
constructor is the NativeError constructor function itself (19.5.6.1).
The initial value of the name property of the prototype for a given NativeError constructor is a
string consisting of the name of the constructor (the name used instead of NativeError).
NativeError instances are ordinary objects that inherit properties from their NativeError prototype
object and have an [[ErrorData]] internal slot whose initial
value is undefined. The only specified use of [[ErrorData]] is to flag whether or not an Error
or NativeError instance has been initialised by its constructor.
The Number constructor is the %Number% intrinsic object and the initial value of the Number property of
the global object. When Number is called as a function rather than as a constructor, it performs a type
conversion. However, if the this value passed in the call is an Object with an uninitialised [[NumberData]] internal slot, it initialises the this value using the
argument value. This permits Number to be used both to perform type conversion and to perform constructor
instance initialisation.
The Number constructor is designed to be subclassable. It may be used as the value of an
extends clause of a class declaration. Subclass constructors that intended to inherit the specified
Number behaviour must include a super call to the Number constructor to initialise
the [[NumberData]] state of subclass instances.
The value of Number.EPSILON is the difference between 1 and the smallest value greater than 1 that is representable as
a Number value, which is approximately 2.2204460492503130808472633361816 x 10-16.
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]:
false }.
NOTE This function differs from the global isNaN function (18.2.3) is that it does not convert its argument to a Number before determining whether it
is NaN.
The value of Number.MIN_VALUE is the smallest positive value of the Number type, which is approximately
5 × 10‑324.
In the IEEE-764 double precision binary representation, the smallest possible value is a denormalized number. If an
implementation does not support denormalized values, the value of Number.MIN_VALUE must be the smallest
non-zero positive value that can actually be represented by the implementation.
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]:
false }.
The value of the Number.parseFloat data property is the same built-in function object that is the value of
the parseFloat property of the global object defined in 18.2.4.
The value of the Number.parseInt data property is the same built-in function object that is the value of
the parseInt property of the global object defined in 18.2.5.
The value of the name property of this function is "[Symbol.create]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: true }.
NOTE [[NumberData]] is initially assigned the value undefined as a
flag to indicate that the instance has not yet been initialised by the Number constructor. This flag value is never
directly exposed to ECMAScript code; hence implementations may choose to encode the flag in some other manner.
The Number prototype object is an ordinary object. It is not a Number instance and does not have a [[NumberData]] internal slot.
The value of the [[Prototype]] internal slot of the
Number prototype object is the standard built-in Object prototype object (19.1.3).
Unless explicitly stated otherwise, the methods of the Number prototype object defined below are not generic and the
this value passed to them must be either a Number value or an object that has a [[NumberData]] internal slot that has been initialised to a Number value.
The abstract operation thisNumberValue(value) performs the
following steps:
If Type(value) is Object and value has a
[[NumberData]] internal slot, then
Let n be the value of value’s [[NumberData]] internal slot.
If n is not undefined, then return n
Throw a TypeError exception.
The phrase “this Number value” within the specification of a method refers to the result returned by
calling the abstract operation thisNumberValue with the this
value of the method invocation passed as the argument.
Return a String containing this Number value represented in decimal exponential notation with one digit before the
significand's decimal point and fractionDigits digits after the significand's decimal point. If
fractionDigits is undefined, include as many significand digits as necessary to uniquely specify the
Number (just like in ToString except that in this case the Number is always output in
exponential notation). Specifically, perform the following steps:
Return the concatenation of the Strings s and "Infinity".
If f < 0 or f > 20, throw a RangeError exception.
If x = 0, then
Let m be the String consisting of f+1 occurrences of the code unit 0x0030.
Let e = 0.
Else x ≠ 0,
If fractionDigits is not undefined, then
Let e and n be integers such that 10f ≤ n <
10f+1 and for which the exact mathematical value of n ×
10e–f – x is as close to zero as possible. If there are two such
sets of e and n, pick the e and n for which n ×
10e–f is larger.
Else fractionDigits is undefined,
Let e, n, and f be integers such that f ≥ 0, 10f ≤
n < 10f+1, the number value for n × 10e–f
is x, and f is as small as possible. Note that the decimal representation of n has
f+1 digits, n is not divisible by 10, and the least significant digit of n is not
necessarily uniquely determined by these criteria.
Let m be the String consisting of the digits of the decimal representation of n (in order, with no
leading zeroes).
If f ≠ 0, then
Let a be the first element of m, and let b be the remaining f elements of
m.
Let m be the concatenation of the three Strings a, ".", and b.
If e = 0, then
Let c = "+".
Let d = "0".
Else
If e > 0, then let c = "+".
Else e ≤ 0,
Let c = "-".
Let e = –e.
Let d be the String consisting of the digits of the decimal representation of e (in order, with no
leading zeroes).
Let m be the concatenation of the four Strings m, "e", c, and d.
Return the concatenation of the Strings s and m.
The length property of the toExponential method is 1.
If the toExponential method is called with more than one argument, then the behaviour is undefined (see clause 17).
An implementation is permitted to extend the behaviour of toExponential for values of
fractionDigits less than 0 or greater than 20. In this case toExponential would not necessarily
throw RangeError for such values.
NOTE For implementations that provide more accurate conversions than required by the rules
above, it is recommended that the following alternative version of step 12.b.i be used as a guideline:
Let e, n, and f be integers such that f ≥ 0, 10f ≤ n <
10f+1, the number value for n × 10e–f is x, and f is
as small as possible. If there are multiple possibilities for n, choose the value of n for which
n × 10e–f is closest in value to x. If there are two such
possible values of n, choose the one that is even.
Note toFixed returns a String containing this Number value represented in
decimal fixed-point notation with fractionDigits digits after the decimal point. If fractionDigits
is undefined, 0 is assumed.
Let n be an integer for which the exact mathematical value of n ÷ 10f –
x is as close to zero as possible. If there are two such n, pick the larger n.
If n = 0, let m be the String "0". Otherwise, let m be the String consisting
of the digits of the decimal representation of n (in order, with no leading zeroes).
If f ≠ 0, then
Let k be the number of elements in m.
If k ≤ f, then
Let z be the String consisting of f+1–k occurrences of the code unit
0x0030.
Let m be the concatenation of Strings z and m.
Let k = f + 1.
Let a be the first k–f elements of m, and let b be the remaining
f elements of m.
Let m be the concatenation of the three Strings a, ".", and b.
Return the concatenation of the Strings s and m.
The length property of the toFixed method is 1.
If the toFixed method is called with more than one argument, then the behaviour is undefined (see clause 17).
An implementation is permitted to extend the behaviour of toFixed for values of fractionDigits
less than 0 or greater than 20. In this case toFixed would not necessarily throw RangeError for such
values.
NOTE The output of toFixed may be more precise than toString for
some values because toString only prints enough significant digits to distinguish the number from adjacent number
values. For example,
(1000000000000000128).toString() returns "1000000000000000100", while
(1000000000000000128).toFixed(0) returns "1000000000000000128".
An ECMAScript implementation that includes the ECMA-402 International API must implement the
Number.prototype.toLocaleString method as specified in the ECMA-402 specification. If an ECMAScript
implementation does not include the ECMA-402 API the following specification of the toLocaleString method is
used.
Produces a String value that represents this Number value formatted according to the conventions of the host
environment’s current locale. This function is implementation-dependent, and it is permissible, but not encouraged,
for it to return the same thing as toString.
The meaning of the optional parameters to this method are defined in the ECMA-402 specification; implementations that
do not include ECMA-402 support must not use those parameter position for anything else.
The length property of the toLocaleString method is 0.
Return a String containing this Number value represented either in decimal exponential notation with one digit before
the significand's decimal point and precision–1 digits
after the significand's decimal point or in decimal fixed notation with precision significant digits. If
precision is undefined, call ToString (7.1.9)
instead. Specifically, perform the following steps:
Return the concatenation of the Strings s and "Infinity".
If p < 1 or p > 21, throw a RangeError exception.
If x = 0, then
Let m be the String consisting of p occurrences of the code unit 0x0030 (the Unicode character
‘0’).
Let e = 0.
Else x ≠ 0,
Let e and n be integers such that 10p–1 ≤ n <
10p and for which the exact mathematical value of n ×
10e–p+1 – x is as close to zero as possible. If there are two such
sets of e and n, pick the e and n for which n ×
10e–p+1 is larger.
Let m be the String consisting of the digits of the decimal representation of n (in order, with no
leading zeroes).
Let a be the first element of m, and let b be the remaining p–1 elements
of m.
Let m be the concatenation of the three Strings a, ".", and b.
If e > 0, then
Let c = "+".
Else e < 0,
Let c = "-".
Let e = –e.
Let d be the String consisting of the digits of the decimal representation of e (in order,
with no leading zeroes).
Return the concatenation of the five Strings s, m, "e", c, and
d.
If e = p–1, then return the concatenation of the Strings s and m.
If e ≥ 0, then
Let m be the concatenation of the first e+1 elements of m, the code unit 0x002E (Unicode
character ‘.’), and the remaining p–
(e+1) elements of m.
Else e < 0,
Let m be the concatenation of the String "0.", –(e+1) occurrences of code unit
0x0030 (the Unicode character ‘0’), and the String m.
Return the concatenation of the Strings s and m.
The length property of the toPrecision method is 1.
If the toPrecision method is called with more than one argument, then the behaviour is undefined (see clause 17).
An implementation is permitted to extend the behaviour of toPrecision for values of precision
less than 1 or greater than 21. In this case toPrecision would not necessarily throw RangeError for
such values.
The optional radix should be an integer value in the inclusive range 2 to 36. If radix not present or is
undefined the Number 10 is used as the value of radix.
If ToInteger(radix) is the Number
10 then this Number value is given as an argument to the ToString abstract operation; the resulting String value is returned.
If ToInteger(radix) is not an
integer between 2 and 36 inclusive throw a RangeError exception. If ToInteger(radix) is an integer from 2 to 36, but not 10, the result is a String
representation of this Number value using the specified radix. Letters a-z are used for digits
with values 10 through 35. The precise algorithm is implementation-dependent if the radix is not 10, however the algorithm
should be a generalisation of that specified in 7.1.12.1.
The toString function is not generic; it throws a TypeError exception if its this value is
not a Number or a Number object. Therefore, it cannot be transferred to other kinds of objects for use as a method.
Number instances are ordinary objects that inherit properties from the Number prototype object. Number instances also
have a [[NumberData]] internal slot. The [[NumberData]] internal slot is the Number value represented by this Number
object.
The value of the [[Prototype]] internal slot of the Math
object is the standard built-in Object prototype object (19.1.3).
The Math is not a function object. It does not have a [[Construct]] internal method; it is not possible to use the Math
object as a constructor with the new operator. The Math object also does not have a [[Call]] internal method;
it is not possible to invoke the Math object as a function.
NOTE In this specification, the phrase “the Number value for x” has a
technical meaning defined in 6.1.6.
Each of the following Math object functions applies the ToNumber abstract
operation to each of its arguments (in left-to-right order if there is more than one). If ToNumber returns an abrupt completion,
that Completion Record is immediately returned. Otherwise, the
function performs a computation on the resulting Number value(s). The value returned by each function is a Number.
In the function descriptions below, the symbols NaN, −0, +0, −∞ and +∞ refer to the Number
values described in 6.1.6.
NOTE The behaviour of the functions acos, acosh, asin,
asinh, atan, atanh, atan2, cbrt, cos,
cosh, exp, hypot, log,log1p, log2,
log10, pow, sin, sinh, sqrt, tan, and
tanh is not precisely specified here except to require specific results for certain argument values that
represent boundary cases of interest. For other argument values, these functions are intended to compute approximations
to the results of familiar mathematical functions, but some latitude is allowed in the choice of approximation
algorithms. The general intent is that an implementer should be able to use the same mathematical library for ECMAScript
on a given hardware platform that is available to C programmers on that platform.
Although the choice of algorithms is left to the implementation, it is recommended (but not specified by this standard)
that implementations use the approximation algorithms for IEEE 754 arithmetic contained in fdlibm, the freely
distributable mathematical library from Sun Microsystems (http://www.netlib.org/fdlibm).
Returns an implementation-dependent approximation to the arc tangent of the quotient y/x of the arguments y and x, where the signs of y
and x are used to determine the quadrant of the result. Note that it is intentional and traditional for the
two-argument arc tangent function that the argument named y be first and the argument named x be
second. The result is expressed in radians and ranges from −π
to +π.
If either x or y is NaN, the result is NaN.
If y>0 and x is +0, the result is an implementation-dependent approximation to +π/2.
If y>0 and x is −0, the result is an implementation-dependent approximation to +π/2.
If y is +0 and x>0, the result is +0.
If y is +0 and x is +0, the result is +0.
If y is +0 and x is −0, the result is an implementation-dependent approximation to +π.
If y is +0 and x<0, the result is an implementation-dependent approximation to +π.
If y is −0 and x>0, the result is −0.
If y is −0 and x is +0, the result is −0.
If y is −0 and x is −0, the result is an implementation-dependent approximation to
−π.
If y is −0 and x<0, the result is an implementation-dependent approximation to
−π.
If y<0 and x is +0, the result is an implementation-dependent approximation to −π/2.
If y<0 and x is −0, the result is an implementation-dependent approximation to
−π/2.
If y>0 and y is finite and x is +∞, the result is +0.
If y>0 and y is finite and x is −∞, the result if an implementation-dependent
approximation to +π.
If y<0 and y is finite and x is +∞, the result is −0.
If y<0 and y is finite and x is −∞, the result is an implementation-dependent
approximation to −π.
If y is +∞ and x is finite, the result is an implementation-dependent approximation to
+π/2.
If y is −∞ and x is finite, the result is an implementation-dependent approximation to
−π/2.
If y is +∞ and x is +∞, the result is an implementation-dependent approximation to
+π/4.
If y is +∞ and x is −∞, the result is an implementation-dependent approximation to
+3π/4.
If y is −∞ and x is +∞, the result is an implementation-dependent approximation to
−π/4.
If y is −∞ and x is −∞, the result is an implementation-dependent
approximation to −3π/4.
Returns the smallest (closest to −∞) Number value that is not less than x and is equal to
a mathematical integer. If x is already an integer, the result is x.
If x is NaN, the result is NaN.
If x is +0, the result is +0.
If x is −0, the result is −0.
If x is +∞, the result is +∞.
If x is −∞, the result is −∞.
If x is less than 0 but greater than -1, the result is −0.
The value of Math.ceil(x) is the same as the value of -Math.floor(-x).
Returns an implementation-dependent approximation to the exponential function of x (e raised to
the power of x, where e is the base of the natural logarithms).
Returns an implementation-dependent approximation to subtracting 1 from the exponential function of x (e
raised to the power of x, where e is the base of the natural logarithms). The result is computed in a way
that is accurate even when the value of x is close 0.
Returns the greatest (closest to +∞) Number value that is not greater than x and is equal to a
mathematical integer. If x is already an integer, the result is x.
If x is NaN, the result is NaN.
If x is +0, the result is +0.
If x is −0, the result is −0.
If x is +∞, the result is +∞.
If x is −∞, the result is −∞.
If x is greater than 0 but less than 1, the result is +0.
NOTE The value of Math.floor(x) is the
same as the value of -Math.ceil(-x).
Math.hypot returns an implementation-dependent approximation of the square root of the sum of squares of
its arguments.
If no arguments are passed, the result is +0.
If any argument is +∞, the result is +∞.
If any argument is −∞, the result is +∞.
If no argument is +∞ or −∞, and any argument is NaN, the result is NaN.
If all arguments are either +0 or -0, the result is +0.
The length property of the hypot function is 2.
NOTE Implementations should take care to avoid the loss of precision from overflows and
underflows that are prone to occur in naive implementations when this function is called with more than two
arguments.
Returns an implementation-dependent approximation to the natural logarithm of 1 + x. The result is computed in
a way that is accurate even when the value of x is close to zero.
Given zero or more arguments, calls ToNumber on each of the arguments and returns the
largest of the resulting values.
If no arguments are given, the result is −∞.
If any value is NaN, the result is NaN.
The comparison of values to determine the largest value is done using the Abstract Relational Comparison algorithm
(7.2.8) except that +0 is considered to be larger than −0.
Given zero or more arguments, calls ToNumber on each of the arguments and returns the
smallest of the resulting values.
If no arguments are given, the result is +∞.
If any value is NaN, the result is NaN.
The comparison of values to determine the smallest value is done using the Abstract Relational Comparison algorithm
(7.2.8) except that +0 is considered to be larger than −0.
Returns a Number value with positive sign, greater than or equal to 0 but less than 1, chosen randomly or pseudo
randomly with approximately uniform distribution over that range, using an implementation-dependent algorithm or strategy.
This function takes no arguments.
Each Math.random function created for distinct code Realms must produce a distinct sequence of values from
successive calls.
Returns the Number value that is closest to x and is equal to a mathematical integer. If two integer Number
values are equally close to x, then the result is the Number value that is closer to +∞. If x is already an integer, the result is x.
If x is NaN, the result is NaN.
If x is +0, the result is +0.
If x is −0, the result is −0.
If x is +∞, the result is +∞.
If x is −∞, the result is −∞.
If x is greater than 0 but less than 0.5, the result is +0.
If x is less than 0 but greater than or equal to -0.5, the result is −0.
NOTE 1Math.round(3.5) returns 4, but Math.round(–3.5) returns –3.
NOTE 2 The value of Math.round(x) is the same as the value of Math.floor(x+0.5), except when x is −0 or is less than 0 but greater than or equal to
-0.5; for these cases Math.round(x) returns −0, but Math.floor(x+0.5)
returns +0.
20.3.1 Overview of Date Objects and Definitions of Abstract Operations
The following functions are abstract operations that operate on time values (defined in 20.3.1.1). Note that, in every case, if any argument to one of these functions
is NaN, the result will be NaN.
A Date object contains a Number indicating a particular instant in time to within a millisecond. Such a Number is
called a time value. A time value may also be NaN, indicating that the Date object does not represent a
specific instant of time.
Time is measured in ECMAScript in milliseconds since 01 January, 1970 UTC. In time values leap seconds are ignored. It
is assumed that there are exactly 86,400,000 milliseconds per day. ECMAScript Number values can represent all integers
from –9,007,199,254,740,992 to 9,007,199,254,740,992; this range suffices to measure times to millisecond precision
for any instant that is within approximately 285,616 years, either forward or backward, from 01 January, 1970 UTC.
The actual range of times supported by ECMAScript Date objects is slightly smaller: exactly –100,000,000 days to
100,000,000 days measured relative to midnight at the beginning of 01 January, 1970 UTC. This gives a range of
8,640,000,000,000,000 milliseconds to either side of 01 January, 1970 UTC.
The exact moment of midnight at the beginning of 01 January, 1970 UTC is represented by the value +0.
ECMAScript uses an extrapolated Gregorian system to map a day number to a year number and to determine the month and
date within that year. In this system, leap years are precisely those which are (divisible by 4) and ((not divisible by 100) or (divisible by
400)). The number of days in year number y is therefore
defined by
DaysInYear(y) = 365 if (ymodulo 4) ≠ 0 = 366 if (ymodulo 4) = 0 and (ymodulo 100) ≠ 0 = 365 if (ymodulo 100) = 0 and (ymodulo 400) ≠ 0 = 366 if (ymodulo 400) = 0
All non-leap years have 365 days with the usual number of days per
month and leap years have an extra day in February. The day number of the first day of year y is given by:
A date number is identified by an integer in the range 1 through
31, inclusive. The mapping DateFromTime(t) from a time valuet to a month number is defined by:
An implementation of ECMAScript is expected to determine the local time zone adjustment. The local time zone adjustment
is a value LocalTZA measured in milliseconds which when added to UTC represents the local standard time. Daylight
saving time is not reflected by LocalTZA.
NOTE It is recommended that implementations use the time zone information of the IANA Time
Zone Database.
An implementation dependent algorithm using best available information on time zones to determine the local daylight
saving time adjustment DaylightSavingTA(t), measured in milliseconds. An implementation of ECMAScript is expected
to make its best effort to determine the local daylight saving time adjustment.
The operator MakeTime calculates a number of milliseconds from its four arguments, which must be ECMAScript Number
values. This operator functions as follows:
If hour is not finite or min is not finite or sec is not finite or ms is not finite,
return NaN.
Let t be h*msPerHour+m*msPerMinute+s*msPerSecond+milli, performing the arithmetic according to IEEE 754 rules (that is, as if using the
ECMAScript operators * and +).
Find a value t such that YearFromTime(t) is ym and MonthFromTime(t) is mn and DateFromTime(t) is 1; but if this is not possible (because some argument is out
of range), return NaN.
The operator MakeDate calculates a number of milliseconds from its two arguments, which must be ECMAScript Number
values. This operator functions as follows:
If day is not finite or time is not finite, return NaN.
The operator TimeClip calculates a number of milliseconds from its argument, which must be an ECMAScript Number value.
This operator functions as follows:
Return ToInteger(time) + (+0). (Adding a positive zero converts
−0 to +0.)
NOTE The point of step 3 is that an implementation is permitted a choice of internal
representations of time values, for example as a 64-bit signed integer or as a 64-bit floating-point value. Depending on
the implementation, this internal representation may or may not distinguish −0 and +0.
ECMAScript defines a string interchange format for date-times based upon a simplification of the ISO 8601 Extended
Format. The format is as follows: YYYY-MM-DDTHH:mm:ss.sssZ
Where the fields are as follows:
YYYYis the decimal digits of the year 0000 to 9999 in the
Gregorian calendar.
-“-” (hyphen) appears literally twice in the string.
MMis the month of the year from 01 (January) to 12
(December).
DDis the day of the month from 01 to 31.
T“T” appears literally in the string, to indicate the beginning of the time element.
HHis the number of complete hours that have passed since
midnight as two decimal digits from 00 to 24.
:“:” (colon) appears literally twice in the string.
mmis the number of complete minutes since the start of the
hour as two decimal digits from 00 to 59.
ssis the number of complete seconds since the start of the
minute as two decimal digits from 00 to 59.
.“.” (dot) appears literally in the string.
sssis the number of complete milliseconds since the start of
the second as three decimal digits.
Zis the time zone offset specified as
“Z” (for UTC) or either
“+” or “-” followed by a time expressionHH:mm
This format includes date-only forms:
YYYY YYYY-MM YYYY-MM-DD
It also includes “date-time” forms that consist of one of the above date-only forms immediately followed
by one of the following time forms with an optional time zone offset appended:
THH:mm THH:mm:ss THH:mm:ss.sss
All numbers must be base 10. If the MM or
DD fields are absent “01” is used as the value. If the HH,
mm, or ss fields are absent “00” is used as the value and the value
of an absent sss field is “000”. If the time zone offset is absent, the date-time
is interpreted as a local time.
Illegal values (out-of-bounds as well as syntax errors) in a format string means that the format string is not a
valid instance of this format.
NOTE 1 As every day both starts and ends with midnight, the two notations 00:00 and 24:00 are available to
distinguish the two midnights that can be associated with one date. This means that the following two notations refer
to exactly the same point in time: 1995-02-04T24:00 and 1995-02-05T00:00
NOTE 2 There exists no international standard that specifies abbreviations for civil time
zones like CET, EST, etc. and sometimes the same abbreviation is even used for two very different time zones. For this
reason, ISO 8601 and this format specifies numeric representations of date and time.
ECMAScript requires the ability to specify 6 digit years (extended
years); approximately 285,426 years, either forward or backward, from
01 January, 1970 UTC. To represent years before 0 or after 9999, ISO 8601 permits the expansion of the year representation, but only by
prior agreement between the sender and the receiver. In the simplified ECMAScript format such an expanded year
representation shall have 2 extra year digits and is always prefixed
with a + or – sign. The year 0 is considered positive and hence
prefixed with a + sign.
NOTE Examples of extended years:
-283457-03-21T15:00:59.008Z 283458 B.C. -000001-01-01T00:00:00Z 2
B.C. +000000-01-01T00:00:00Z 1 B.C. +000001-01-01T00:00:00Z
1 A.D. +001970-01-01T00:00:00Z 1970 A.D. +002009-12-15T00:00:00Z
2009 A.D. +287396-10-12T08:59:00.992Z 287396 A.D.
The Date constructor is the %Date% intrinsic object and the initial value of the Date property of the
global object. When Date is called as a function rather than as a constructor, it returns a String
representing the current time (UTC). However, if the this value passed in the call is an Object with an
uninitialised [[DateValue]] internal slot, Date
initialises the this object using the argument value. This permits Date to be used both as a function
for creating data strings and to perform constructor instance initialisation.
The Date constructor is designed to be subclassable. It may be used as the value of an
extends clause of a class declaration. Subclass constructors that intended to inherit the specified
Date behaviour must include a super call to the Date constructor to initialise the
[[DateValue]] state of subclass instances.
20.3.2.1 Date (year, month [, date [, hours [, minutes [, seconds [, ms ] ] ] ] ] )
This description applies only if the Date constructor is called with at least two arguments.
When the Date function is called the following steps are taken:
Let numberOfArgs be the number of arguments passed to this constructor call.
Return the result computed as if by the expression (new Date()).toString() where Date
is this function and toString is the standard built-in method Date.prototype.toString.
Let tv be the result of parsing v as a date, in exactly the same manner as for the
parse method (20.3.3.2). If the parse resulted in an abrupt completion, tv is the Completion Record.
Return the result computed as if by the expression (new Date()).toString() where Date
is this function and toString is the standard built-in method Date.prototype.toString.
If Type(O) is Object and O has a [[DateValue]] internal slot and the value of [[DateValue]] is
undefined, then
Set the [[DateValue]] internal slot of O to
the time value (UTC) identifying the current time.
Return O.
Else,
Return the result computed as if by the expression (new Date()).toString() where Date
is this function and toString is the standard built-in method Date.prototype.toString.
The parse function applies the ToString operator to its argument. If ToString results in an abrupt completion
the Completion Record is immediately returned. Otherwise,
parse interprets the resulting String as a date and time; it returns a Number, the UTC time value corresponding to the date and time. The String may be interpreted as
a local time, a UTC time, or a time in some other time zone, depending on the contents of the String. The function first
attempts to parse the format of the String according to the rules (including extended years) called out in Date Time
String Format (20.3.1.15). If the String does not conform to that format the
function may fall back to any implementation-specific heuristics or implementation-specific date formats. Unrecognisable
Strings or dates containing illegal element values in the format String shall cause Date.parse to return
NaN.
If x is any Date object whose milliseconds amount is zero within a particular implementation of ECMAScript,
then all of the following expressions should produce the same numeric value in that implementation, if all the properties
referenced have their initial values:
x.valueOf()
Date.parse(x.toString())
Date.parse(x.toUTCString())
Date.parse(x.toISOString())
However, the expression
Date.parse(x.toLocaleString())
is not required to produce the same Number value as the preceding three expressions and, in general, the value produced
by Date.parse is implementation-dependent when given any String value that does not conform to the Date Time
String Format (20.3.1.15) and that could not be produced in that implementation
by the toString or toUTCString method.
The initial value of Date.prototype is the built-in Date prototype object (20.3.4).
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]:
false }.
20.3.3.4
Date.UTC (year, month [, date [, hours [, minutes [, seconds [, ms ] ] ] ] ] )
When the UTC function is called with fewer than two arguments, the behaviour is implementation-dependent.
When the UTC function is called with two to seven arguments, it computes the date from year,
month and (optionally) date, hours, minutes, seconds and
ms. The following steps are taken:
NOTE The UTC function differs from the Date constructor in two ways: it returns a time value as a Number, rather than creating a Date object, and it interprets
the arguments in UTC rather than as local time.
The value of the name property of this function is "[Symbol.create]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: true }.
NOTE [[DateValue]] is initially assigned the value undefined as a
flag to indicate that the instance has not yet been initialised by the Date constructor. This flag value is never
directly exposed to ECMAScript code; hence implementations may choose to encode the flag in some other manner.
The Date prototype object is itself an ordinary object. It is not a Date instance and does not have a [[DateValue]] internal slot.
The value of the [[Prototype]] internal slot of the Date
prototype object is the standard built-in Object prototype object (20.3.4).
Unless explicitly defined otherwise, the methods of the Date prototype object defined below are not generic and the
this value passed to them must be an object that has a [[DateValue]] internal slot that has been initialised to a time value.
The abstract operation thisTimeValue(value) performs the
following steps:
If Type(value) is Object and value has a
[[DateValue]] internal slot, then
Let n be the Number that is the value of value’s [[DateValue]] internal slot.
If n is not undefined, then return n.
Throw a TypeError exception.
In following descriptions of functions that are properties of the Date prototype object, the phrase “this Date
object” refers to the object that is the this value for the invocation of the function. The phrase
“this time value” within the specification of a method refers to
the result returned by calling the abstract operation thisTimeValue
with the this value of the method invocation passed as the argument.
This function returns a String value. The contents of the String are implementation-dependent, but are intended to
represent the “date” portion of the Date in the current time zone in a convenient, human-readable form.
This function returns a String value representing the instance in time corresponding to this time value. The format of the String is the Date Time string
format defined in 20.3.1.15. All fields are present in the String. The time
zone is always UTC, denoted by the suffix Z. If this time value
is not a finite Number or if the year is not a value that can be represented in that format (if necessary using extended
year format), a RangeError exception is thrown.
If IsCallable(toISO) is false, throw a TypeError exception.
Return the result of calling the [[Call]] internal method of toISO with O as thisArgument and
an empty List as argumentsList.
NOTE 1 The argument is ignored.
NOTE 2 The toJSON function is intentionally generic; it does not require that
its this value be a Date object. Therefore, it can be transferred to other kinds of objects for use as a method.
However, it does require that any such object have a toISOString method. An object is free to use the
argument key to filter its stringification.
An ECMAScript implementation that includes the ECMA-402 International API must implement the
Date.prototype.toLocaleDateString method as specified in the ECMA-402 specification. If an ECMAScript
implementation does not include the ECMA-402 API the following specification of the toLocaleDateString
method is used.
This function returns a String value. The contents of the String are implementation-dependent, but are intended to
represent the “date” portion of the Date in the current time zone in a convenient, human-readable form that
corresponds to the conventions of the host environment’s current locale.
The meaning of the optional parameters to this method are defined in the ECMA-402 specification; implementations that
do not include ECMA-402 support must not use those parameter position for anything else.
The length property of the toLocaleDateString method is 0.
An ECMAScript implementation that includes the ECMA-402 International API must implement the
Date.prototype.toLocaleString method as specified in the ECMA-402 specification. If an ECMAScript
implementation does not include the ECMA-402 API the following specification of the toLocaleString method is
used.
This function returns a String value. The contents of the String are implementation-dependent, but are intended to
represent the Date in the current time zone in a convenient, human-readable form that corresponds to the conventions of
the host environment’s current locale.
The meaning of the optional parameters to this method are defined in the ECMA-402 specification; implementations that
do not include ECMA-402 support must not use those parameter position for anything else.
The length property of the toLocaleString method is 0.
An ECMAScript implementation that includes the ECMA-402 International API must implement the
Date.prototype.toLocaleTimeString method as specified in the ECMA-402 specification. If an ECMAScript
implementation does not include the ECMA-402 API the following specification of the toLocaleString method is
used.
This function returns a String value. The contents of the String are implementation-dependent, but are intended to
represent the “time” portion of the Date in the current time zone in a convenient, human-readable form that
corresponds to the conventions of the host environment’s current locale.
The meaning of the optional parameters to this method are defined in the ECMA-402 specification; implementations that
do not include ECMA-402 support must not use those parameter position for anything else.
The length property of the toLocaleTimeString method is 0.
This function returns a String value. If this time value is
NaN, the String value is "Invalid Date", otherwise the contents of the String are implementation-dependent,
but are intended to represent the Date in the current time zone in a convenient, human-readable form.
NOTE For any Date value d whose
milliseconds amount is zero, the result of Date.parse(d.toString()) is equal to d.valueOf(). See 20.3.3.2.
This function returns a String value. The contents of the String are implementation-dependent, but are intended to
represent the “time” portion of the Date in the current time zone in a convenient, human-readable form.
This function returns a String value. The contents of the String are implementation-dependent, but are intended to
represent this time value in a convenient, human-readable form
in UTC.
NOTE The intent is to produce a String representation of a date that is more readable than
the format specified in 20.3.1.15. It is not essential that the chosen format
be unambiguous or easily machine parsable. If an implementation does not have a preferred human-readable format it is
recommended to use the format defined in 20.3.1.15 but with a space rather
than a “T” used to separate the date and time elements.
The valueOf function returns a Number, which is this time value.
20.3.4.45 Date.prototype [ @@toPrimitive ] ( hint )
This function is called by ECMAScript language operators to convert an object to a primitive value. The allowed values
for hint are "default", "number", and "string". Date objects, are
unique among built-in ECMAScript object in that they treat "default" as being equivalent to
"string", All other built-in ECMAScript objects treat "default" as being equivalent to
"number".
When the @@toPrimitive method is called with argument hint, the following steps are taken:
Let O be the this value.
If Type(O) is not Object, then throw a TypeError
exception.
If hint is the string value "string" or the string value "default" , then
Let tryFirst be "string".
Else if hint is the string value "number", then
Let tryFirst be "number".
Else, throw a TypeError exception.
Return the result of OrdinaryToPrimitive(O,tryFirst).
The value of the name property of this function is "[Symbol.toPrimitive]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: true }.
Date instances are ordinary objects that inherit properties from the Date prototype object. Date instances also have a
[[DateValue]] internal slot. The [[DateValue]] internal slot is the time value represented by this Date object.
The String constructor is the %String% intrinsic object and the initial value of the String property of
the global object. When String is called as a function rather than as a constructor, it performs a type
conversion. However, if the this value passed in the call is an Object with an uninitialised [[StringData]] internal slot, it initialises the this value using the
argument value. This permits String to be used both to perform type conversion and to perform constructor
instance initialisation.
The String constructor is designed to be subclassable. It may be used as the value of an
extends clause of a class declaration. Subclass constructors that intended to inherit the specified
String behaviour must include a super call to the String constructor to initialise
the [[StringData]] state of subclass instances.
If Type(O) is Object and O has a [[StringData]] internal slot and the value of [[StringData]] is
undefined, then
Let length be the number of code unit elements in s.
Let status be the result of DefinePropertyOrThrow(O,
"length", PropertyDescriptor{[[Value]]: length, [[Writable]]: false, [[Enumerable]]:
false, [[Configurable]]: false }).
The String.fromCharCode function may be called with a variable number of arguments which form the rest
parameter codeUnits. The following steps are taken:
Assert: codeUnits is a well-formed rest parameter object.
Let length be the result of Get(codeUnits,
"length").
The String.fromCodePoint function may be called with a variable number of arguments which form the rest
parameter codePoints. The following steps are taken:
Assert: codePoints is a well-formed rest parameter object.
Let length be the result of Get(codePoints,
"length").
The String.raw function may be called with a variable number of arguments. The first argument is
callSite and the remainder of the arguments form the rest parameter substitutions. The following
steps are taken:
Assert: substitutions is a well-formed rest parameter object.
Append in order the code unit elements of nextSub to the end of stringElements.
Let nextIndex be nextIndex + 1.
The length property of the raw function is 1.
NOTE String.raw is intended for use as a tag function of a Tagged Template String (12.2.7). When called as such the first argument will be a well formed template call
site object and the rest parameter will contain the substitution values.
Let obj be the result of calling StringCreate (proto).
Return obj.
The value of the name property of this function is "[Symbol.create]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]:
true }.
NOTE [[StringData]] is initially assigned the value undefined as a
flag to indicate that the instance has not yet been initialised by the String constructor. This flag value is never
directly exposed to ECMAScript code; hence implementations may choose to encode the flag in some other manner.
The String prototype object is itself an ordinary object. It is not a String instance and does not have a
[[StringData]] internal slot.
The value of the [[Prototype]] internal slot of the
String prototype object is the standard built-in Object prototype object (19.1.3).
Unless explicitly stated otherwise, the methods of the String prototype object defined below are not generic and the
this value passed to them must be either a String value or an object that has a [[StringData]] internal slot that has been initialised to a String value.
The abstract operation thisStringValue(value) performs the
following steps:
If Type(value) is Object and value has a
[[StringData]] internal slot, then
Let s be the value of value’s [[StringData]] internal slot.
If s is not undefined, then return s.
Throw a TypeError exception.
The phrase “this String value” within the specification of a method refers to the result returned by
calling the abstract operation thisStringValue with the this
value of the method invocation passed as the argument.
NOTE Returns a single element String containing the code unit at element position
pos in the String value resulting from converting this object to a String. If there is no element at that
position, the result is the empty String. The result is a String value, not a String object.
If pos is a value of Number type that is an integer, then the result of
x.charAt(pos) is equal to the result of
x.substring(pos,pos+1).
When the charAt method is called with one argument pos, the following steps are taken:
If position < 0 or position ≥ size, return the empty String.
Return a String of length 1, containing one code unit from S, namely the code unit at position
position, where the first (leftmost) code unit in S is considered to be at position 0, the next one at
position 1, and so on.
NOTE The charAt function is intentionally generic; it does not require that its
this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
NOTE Returns a Number (a nonnegative integer less than 216) that is the code unit value of the string element at position pos in the String
resulting from converting this object to a String. If there is no element at that position, the result is
NaN.
When the charCodeAt method is called with one argument pos, the following steps are taken:
Return a value of Number type, whose value is the code unit value of the element at position position in the
String S, where the first (leftmost) element in S is considered to be at position 0, the next one at
position 1, and so on.
NOTE The charCodeAt function is intentionally generic; it does not require that
its this value be a String object. Therefore it can be transferred to other kinds of objects for use as a
method.
NOTE Returns a nonnegative integer Number less than 1114112 (0x110000) that is the UTF-16 encoded code point value starting at the string element at position
pos in the String resulting from converting this object to a String. If there is no element at that position,
the result is undefined. If a valid UTF-16 surrogate pair does not begin at pos,
the result is the code unit at pos.
When the codePointAt method is called with one argument pos, the following steps are taken:
NOTE The codePointAt function is intentionally generic; it does not require that
its this value be a String object. Therefore it can be transferred to other kinds of objects for use as a
method.
NOTE When the concat method is called with zero or more arguments, it returns a
String consisting of the string elements of this object (converted to a String) followed by the string elements of each
of the arguments converted to a String. The result is a String value, not a String object.
The following steps are taken:
Assert: args is a well-formed rest parameter object.
Let R be the String value consisting of the string elements in the previous value of R followed by
the string elements of nextString.
Return R.
The length property of the concat method is 1.
NOTE The concat function is intentionally generic; it does not require that its
this value be a String object. Therefore it can be transferred to other kinds of objects for use as a method.
Let searchLen be the number of elements in searchStr.
If there exists any integer k not smaller than start such that k + searchLen is not
greater than len, and for all nonnegative integers j less than searchLen, the character at
position k+j of S is the same as the character at position j of searchStr, return
true; but if there is no such integer k, return false.
The length property of the contains method is 1.
NOTE 1 If searchString appears as a substring of the result of converting this object
to a String, at one or more positions that are greater than or equal to position, then return true;
otherwise, returns false. If position is undefined, 0 is assumed, so as to search all of the
String.
NOTE 2 The contains function is intentionally generic; it does not require that its
this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
Let searchLength be the number of elements in searchStr.
Let start be end - searchLength.
If start is less than 0, return false.
If the searchLength sequence of elements of S starting at start is the same as the full element
sequence of searchStr, return true.
Otherwise, return false.
The length property of the endsWith method is 1.
NOTE 1 Returns true if the sequence of elements of searchString converted to a
String is the same as the corresponding elements of this object (converted to a String) starting at endPosition
– length(this). Otherwise returns false.
NOTE 2 Throwing an exception if the first argument is a RegExp is specified in order to allow
future editions to define extends that allow such argument values.
NOTE 3 The endsWith function is intentionally generic; it does not require that its
this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
If searchString appears as a substring of the result of converting this object to a String, at one or more
positions that are greater than or equal to position, then the index of the smallest such position is returned;
otherwise, ‑1 is returned. If position is undefined, 0 is assumed, so as to search
all of the String.
The indexOf method takes two arguments, searchString and position, and performs the
following steps:
Let searchLen be the number of elements in searchStr.
Return the smallest possible integer k not smaller than start such that k+ searchLen is
not greater than len, and for all nonnegative integers j less than searchLen, the code unit at
position k+j of S is the same as the code unit at position j of searchStr; but if
there is no such integer k, then return the value -1.
The length property of the indexOf method is 1.
NOTE The indexOf function is intentionally generic; it does not require that its
this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
If searchString appears as a substring of the result of converting this object to a String at one or more
positions that are smaller than or equal to position, then the index of the greatest such position is returned;
otherwise, ‑1 is returned. If position is undefined, the length of the String value
is assumed, so as to search all of the String.
The lastIndexOf method takes two arguments, searchString and position, and performs
the following steps:
If numPos is NaN, let pos be +∞; otherwise, let pos be ToInteger(numPos).
Let len be the number of elements in S.
Let start be min(max(pos, 0), len).
Let searchLen be the number of elements in searchStr.
Return the largest possible nonnegative integer k not larger than start such that k+
searchLen is not greater than len, and for all nonnegative integers j less than
searchLen, the code unit at position k+j of S is the same as the code unit at position
j of searchStr; but if there is no such integer k, then return the value -1.
The length property of the lastIndexOf method is 1.
NOTE The lastIndexOf function is intentionally generic; it does not require that
its this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
An ECMAScript implementation that includes the ECMA-402 International API must implement the localeCompare
method as specified in the ECMA-402 specification. If an ECMAScript implementation does not include the ECMA-402 API the
following specification of the localeCompare method is used.
When the localeCompare method is called with argument that, it returns a Number other than
NaN that represents the result of a locale-sensitive String comparison of the this value (converted to a
String) with that (converted to a String). The two Strings are S and That.
The two Strings are compared in an implementation-defined fashion. The result is intended to order String values in the
sort order specified by the system default locale, and will be negative, zero, or positive, depending on whether
S comes before That in the sort order, the Strings are equal, or S comes
after That in the sort order, respectively.
Before perform the comparisons the following steps are performed to prepare the Strings:
The meaning of the optional second and third parameters to this method are defined in the ECMA-402 specification;
implementations that do not include ECMA-402 support must not use those parameter position for anything else.
The localeCompare method, if considered as a function of two arguments this and that, is
a consistent comparison function (as defined in 22.1.3.24) on the set of all
Strings.
The actual return values are implementation-defined to permit implementers to encode additional information in the
value, but the function is required to define a total ordering on all Strings. If the implementation performs
language-sensitive comparisions it must return 0 when comparing Strings that are considered canonically
equivalent by the Unicode standard.
If no language-sensitive comparison at all is available from the host environment, this function may perform a bitwise
comparison.
The length property of the localeCompare method is 1.
NOTE 1 The localeCompare method itself is not directly suitable as an argument
to Array.prototype.sort because the latter requires a function of
two arguments.
NOTE 2 This function is intended to rely on whatever language-sensitive comparison
functionality is available to the ECMAScript environment from the host environment, and to compare according to the
rules of the host environment’s current locale. This function must treat Strings that are canonically equivalent
according to the Unicode standard as identical. It is also recommended that this function not honour Unicode
compatibility equivalences or decompositions. For a definition and discussion of canonical equivalence see the Unicode
Standard, chapters 2 and 3, as well as Unicode Annex #15, Unicode Normalization Forms and Unicode Technical Note #5
Canonical Equivalence in Applications. Also see Unicode Technical Stardard #10, Unicode Collation Algorithm.
NOTE 3 The localeCompare function is intentionally generic; it does not require
that its this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
Return the result of Invoke(rx, "match", ( S )). .
NOTE The match function is intentionally generic; it does not require that its
this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
21.1.3.12 String.prototype.normalize ( form = "NFC"
)
When the normalize method is called with one argument form, the following steps are taken:
If f is not one of "NFC", "NFD", "NFKC", or "NFKD", then throw a RangeError Exception.
Let ns be the String value is the result of normalizing S into the normalization form named by
f as specified in Unicode Standard Annex #15, UnicodeNormalizatoin Forms.
Return ns.
The length property of the normalize method is 0.
NOTE The normalize function is intentionally generic; it does not require that
its this value be a String object. Therefore it can be transferred to other kinds of objects for use as a
method.
Let T be a String value that is made from n copies of S appended together. If n is 0,
T is the empty String.
Return T.
NOTE 1 This method creates a String consisting of the string elements of this object
(converted to String) repeated count time.
NOTE 2 The repeat function is intentionally generic; it does not require that
its this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
Search string for the first occurrence of searchString and let pos be the index position
within string of the first code unit of the matched substring and let matched be
searchString. If no occurrences of searchString were found, return string.
Let replValue be the result of calling the [[Call]] internal method of replaceValue passing
undefined as the this value and a List
containing matched, pos, and string as the argument list.
Let replStr be the result of the abstract operation GetReplaceSubstitution(matched, string, pos,
captures).
Let tailPos be pos + the number of code units in matched.
Let newString be the String formed by concatenating the first pos code units of string,
replStr, and the trailing substring of string starting at index tailPos. If pos is 0,
the first element of the concatenation will be the empty String.
Return newString.
NOTE The replace function is intentionally generic; it does not require that
its this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
Assert: captures is a possibly empty List of Strings.
Let tailPos be position + matchLength.
Let m be the number of elements in captures.
Let result be a String value derived from matched by replacing code unit elements in matched
by replacement text as specified in Table 39. These $ replacements are done
left-to-right, and, once such a replacement is performed, the new replacement text is not subject to further
replacements.
Return result.
Table 39 — Replacement Text Symbol Substitutions
Code units
Unicode Characters
Replacement text
0x0024, 0x0024
$$
$
0x0024, 0x0026
$&
matched
0x0024, 0x0060
$`
If position is 0, the replacement is the empty String. Otherwise the replacement is the substring of string that starts at index 0 and whose last code point is at index position -1.
0x0024, 0x0027
$'
If tailPos ≥ stringLength, the replacement is the empty String. Otherwise the replacement is the substring of string that starts at index tailPos and continues to the end of string.
0x0024, N where 0x0031 ≤ N ≤ 0x0039
$nwhere nis one of1 2 3 4 5 6 7 8 9and$nis not followed by a decimal digit
The nth element of captures, where n is a single digit in the range 1 to 9. If n≤m and the nth element of captures is undefined, use the empty String instead. If n>m, the result is implementation-defined.
0x0024, N, N where 0x0030 ≤ N ≤ 0x0039
$nnwhere nis one of0 1 2 3 4 5 6 7 8 9
The nnth elemet of captures, where nn is a two-digit decimal number in the range 01 to 99. If nn≤m and the nnth element of captures is undefined, use the empty String instead. If nn is 00 or nn>m, the result is implementation-defined.
0x0024
$in any context that does not match on of the above.
Return the result of Invoke(rx, "search", (string)).
NOTE The search function is intentionally generic; it does not require that its
this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
The slice method takes two arguments, start and end, and returns a substring of the
result of converting this object to a String, starting from element position start and running to, but not
including, element position end (or through the end of the String if end is undefined). If
start is negative, it is treated as sourceLength+start where sourceLength is the length of the String. If
end is negative, it is treated as sourceLength+end where sourceLength is the length of the String. The result is a
String value, not a String object. The following steps are taken:
If end is undefined, let intEnd be len; else let intEnd be ToInteger(end).
If intStart is negative, let from be max(len + intStart,0); else let from be
min(intStart, len).
If intEnd is negative, let to be max(len + intEnd,0); else let to be
min(intEnd, len).
Let span be max(to – from,0).
Return a String value containing span consecutive elements from S beginning with the element at
position from.
The length property of the slice method is 2.
NOTE The slice function is intentionally generic; it does not require that its
this value be a String object. Therefore it can be transferred to other kinds of objects for use as a method.
Returns an Array object into which substrings of the result of converting this object to a String have been stored.
The substrings are determined by searching from left to right for occurrences of separator; these occurrences
are not part of any substring in the returned array, but serve to divide up the String value. The value of
separator may be a String of any length or it may be a RegExp object.
When the split method is called, the following steps are taken:
NOTE The value of separator may be an empty String, an empty regular expression,
or a regular expression that can match an empty String. In this case, separator does not match the empty
substring at the beginning or end of the input String, nor does it match the empty substring at the end of the
previous separator match. (For example, if separator is the empty String, the String is split up into
individual code unit elements; the length of the result array equals the length of the String, and each substring
contains one code unit.) If separator is a regular expression, only the first match at a given position of
the this String is considered, even if backtracking could yield a non-empty-substring match at that position.
(For example, "ab".split(/a*?/) evaluates to the array ["a","b"], while
"ab".split(/a*/) evaluates to the array["","b"].)
If the this object is (or converts to) the empty String, the result depends on whether separator
can match the empty String. If it can, the result array contains no elements. Otherwise, the result array contains one
element, which is the empty String.
If separator is a regular expression that contains capturing parentheses, then each time
separator is matched the results (including any undefined results) of the capturing parentheses are
spliced into the output array. For example,
If separator is undefined, then the result array contains just one String, which is the
this value (converted to a String). If limit is not undefined, then the output array is
truncated so that it contains no more than limit elements.
The abstract operation SplitMatch takes three parameters, a String S, an integer q, and a
String R, and performs the following in order to return either false or the end index of a match:
Type(R) must be String. Let r be the number of
code units in R.
Let s be the number of code units in S.
If q+r > s then return false.
If there exists an integer i between 0 (inclusive) and r (exclusive) such that the code unit at
position q+i of S is different from the code unit at position i of R, then
return false.
Return q+r.
The length property of the split method is 2.
NOTE The split function is intentionally generic; it does not require that
its this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
21.1.3.18 String.prototype.startsWith (searchString [, position ] )
Let searchLength be the number of elements in searchStr.
If searchLength+start is greater than len, return false.
If the searchLength sequence of elements of S starting at start is the same as the full element
sequence of searchStr, return true.
Otherwise, return false.
The length property of the startsWith method is 1.
NOTE 1 This method returns true if the sequence of elements of searchString
converted to a String is the same as the corresponding elements of this object (converted to a String) starting at
position. Otherwise returns false.
NOTE 2 Throwing an exception if the first argument is a RegExp is specified in order to allow
future editions to define extends that allow such argument values.
NOTE 3 The startsWith function is intentionally generic; it does not require that its
this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
The substring method takes two arguments, start and end, and returns a substring of the
result of converting this object to a String, starting from element position start and running to, but not
including, element position end of the String (or through the end of the String is end is
undefined). The result is a String value, not a String object.
If either argument is NaN or negative, it is replaced with zero; if either argument is larger than the length of
the String, it is replaced with the length of the String.
If end is undefined, let intEnd be len; else let intEnd be ToInteger(end).
Let finalStart be min(max(intStart, 0), len).
Let finalEnd be min(max(intEnd, 0), len).
Let from be min(finalStart, finalEnd).
Let to be max(finalStart, finalEnd).
Return a String whose length is to - from, containing code units from S, namely the code units
with indices from through to −1, in ascending order.
The length property of the substring method is 2.
NOTE The substring function is intentionally generic; it does not require that
its this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
This function interprets a string value as a sequence of code points, as described in 6.1.4.
This function works exactly the same as toLowerCase except that its result is intended to yield the
correct result for the host environment’s current locale, rather than a locale-independent result. There will only
be a difference in the few cases (such as Turkish) where the rules for that language conflict with the regular Unicode
case mappings.
NOTE 1 The first parameter to this function is likely to be used in a future version of this
standard; it is recommended that implementations do not use this parameter position for anything else.
NOTE 2 The toLocaleLowerCase function is intentionally generic; it does not
require that its this value be a String object. Therefore, it can be transferred to other kinds of objects for
use as a method.
This function interprets a string value as a sequence of code points, as described in 6.1.4.
This function works exactly the same as toUpperCase except that its result is intended to yield the
correct result for the host environment’s current locale, rather than a locale-independent result. There will only
be a difference in the few cases (such as Turkish) where the rules for that language conflict with the regular Unicode
case mappings.
NOTE 1 The first parameter to this function is likely to be used in a future version of this
standard; it is recommended that implementations do not use this parameter position for anything else.
NOTE 2 The toLocaleUpperCase function is intentionally generic; it does not
require that its this value be a String object. Therefore, it can be transferred to other kinds of objects for
use as a method.
Let cpList be a List containing in order the code
points as defned in 6.1.4 of S, starting at the
first element of S.
For each code point c in cpList, if the Unicode Character Database provides a language insensitive
lower case equivalent of c then replace c in cpList with that equivalent code point(s).
For each code point c in cpList, in order, append to cuList the elements of the UTF-16
Encoding (10.1.1) of c.
Let L be a String whose elements are, in order, the elements of cuList .
Return L.
The result must be derived according to the locale-insensitive case mappings in the Unicode Character
Database (this explicitly includes not only the UnicodeData.txt file, but also all locale-insensitive mappings in the
SpecialCasings.txt file that accompanies it).
NOTE 1 The case mapping of some code points may produce multiple code points . In this case
the result String may not be the same length as the source String. Because both toUpperCase and
toLowerCase have context-sensitive behaviour, the functions are not symmetrical. In other words,
s.toUpperCase().toLowerCase() is not necessarily equal to s.toLowerCase().
NOTE 2 The toLowerCase function is intentionally generic; it does not require
that its this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
This function interprets a string value as a sequence of code points, as described in 6.1.4.
This function behaves in exactly the same way as String.prototype.toLowerCase, except that code points are mapped to
their uppercase equivalents as specified in the Unicode Character Database.
NOTE The toUpperCase function is intentionally generic; it does not require that
its this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
Let T be a String value that is a copy of S with both leading and trailing white space removed. The
definition of white space is the union of WhiteSpace and LineTerminator. When determining whether a
Unicode code point is in Unicode general category “Zs”, code unit sequences are interpreted as UTF-16
encoded code point sequences as specified in 6.1.4.
Return T.
NOTE The trim function is intentionally generic; it does not require that its
this value be a String object. Therefore, it can be transferred to other kinds of objects for use as a
method.
When the @@iterator method is called it returns an Iterator object (25.1.2) that
iterates over the code points of a String value, returning each code point as a String value. The following steps are
taken:
String instances are String exotic objects and have the internal methods specified for such objects. String instances
inherit properties from the String prototype object. String instances also have a [[StringData]] internal slot.
String instances have a length property, and a set of enumerable properties with integer indexed
names.
The number of elements in the String value represented by this String object.
Once a String object is initialised, this property is unchanging. It has the attributes { [[Writable]]: false,
[[Enumerable]]: false, [[Configurable]]: false }.
An String Iterator is an object, that represents a specific iteration over some specific String instance object. There
is not a named constructor for String Iterator objects. Instead, String iterator objects are created by calling certain
methods of String instance objects.
Several methods of String objects return Iterator objects. The abstract operation CreateStringIterator with argument
string is used to create such iterator objects. It performs the following steps:
All String Iterator Objects inherit properties from the %StringIteratorPrototype% intrinsic object. The
%StringIteratorPrototype% object is an ordinary object and its [[Prototype]] internal slot is the %ObjectPrototype% intrinsic object. In
addition, %StringIteratorPrototype% has the following properties:
String Iterator instances are ordinary objects that inherit properties from the %StringIteratorPrototype% intrinsic
object. String Iterator instances are initially created with the internal slots listed in Table
42.
Table 40 — Internal Slots of String Iterator Instances
Internal Slot
Description
[[IteratedString]]
The String value whose elements are being iterated.
[[StringIteratorNextIndex]]
The integer index of the next string index to be examined by this iteration.
The RegExp constructor applies the following grammar to the input pattern String. An error occurs if the
grammar cannot interpret the String as an expansion of Pattern.
A regular expression pattern is converted into an internal procedure using the process described below. An
implementation is encouraged to use more efficient algorithms than the ones listed below, as long as the results are the
same. The internal procedure is used as the value of a RegExp object’s [[RegExpMatcher]] internal slot.
A Pattern is either a BMP pattern or a Unicode pattern depending upon whether or not its
associated flags contains a "u". A BMP pattern matches against a String interpreted as consisting of a
sequence of Unicode code units. A Unicode pattern matches against a String interpreted as consisting of Unicode code
points encoded using UTF-16. In the context of describing the behaviour of a BMP pattern “character” means a
Unicode code unit. In the context of describing the behaviour of a Unicode pattern “character” means a
Unicode code point. In either context, “character value” means the numeric value of the code unit or code
point.
The semantics of Pattern is defined as if a Pattern was a List of SourceCharacter values. Each SourceCharacter corresponding to a Unicode code point. If a BMP pattern contains a non-BMP SourceCharacter the entire pattern is encoded using UTF-16 and the individual code units of that
encoding are used as the elements of the List.
NOTE For example, consider a pattern expressed in source code as the single non-BMP character
U+1D11E (MUSICAL SYMBOL G CLEF). Interpreted as a Unicode pattern, it would be a single element (character) List consisting of the single code point 0x1D11E. However,
interpreted as a BMP pattern, it is first UTF-16 encoded to produce a two element List consisting the code units 0xD834 and 0xDDE.
Patterns are passed to the RegExp constructor as ECMAScript string values in which non-BMP characters are UTF-16
encoded. The single charcter MUSICAL SYMBOL G CLEF pattern, expressed as a string value, is a String of length 2 whose
elements were the code units 0xD834 and 0xDDE. So no further translation of the string would be necessary to process it
as a BMP pattern consisting of two pattern characters. However, to process it as a Unicode pattern the string value
must treated as if it was UTF-16 decoded into a List consisting of
a single pattern character, the code unit U+1D11E.
An implementation may not actually perform such translations to or from UTF-16, but the semantics of this specification
requires that the result of pattern matching be as if such transations were performed.
The descriptions below use the following variables:
Input is a List consisting of all of
the characters, in order, of the String being matched by the regular expression pattern. Each character is either a
code units or a code points, depending upon the kind of pattern involved. The notation input[n] means the nth character of input, where n can range between 0 (inclusive)
and InputLength (exclusive).
InputLength is the number of characters in Input.
NcapturingParens is the total number of left capturing parentheses (i.e. the total number
of times the Atom::(Disjunction) production is expanded) in the pattern. A left
capturing parenthesis is any ( pattern character that is matched by the ( terminal of the
Atom::(Disjunction) production.
IgnoreCase is true if the RegExp object's [[OriginalFlags]] internal slot contains "i" and otherwise is
false.
Multiline is true if the RegExp object’s [[OriginalFlags]] internal slot contains "m" and otherwise is
false.
Unicode is true if the RegExp object’s [[OriginalFlags]] internal slot contains "u" and otherwise is
false.
Furthermore, the descriptions below use the following internal data structures:
A CharSet is a mathematical set of characters, either code units or code points depending
up the state of the Unicode flag. “All characters” means either all code unit
values or all code point values also depending upon the state if Unicode.
A State is an ordered pair (endIndex,
captures) where endIndex is an integer and captures is a List of NcapturingParens values. States are used to represent partial match states in the regular expression matching algorithms. The
endIndex is one plus the index of the last input character matched so far by the pattern, while
captures holds the results of capturing parentheses. The nth element of captures is either a List that represents the value obtained by the nth set of capturing parentheses or undefined if
the nth set of capturing parentheses hasn’t
been reached yet. Due to backtracking, many States may be in use at any time during the
matching process.
A MatchResult is either a State or the special token failure
that indicates that the match failed.
A Continuation procedure is an internal closure (i.e. an internal procedure with some
arguments already bound to values) that takes one State argument and returns a MatchResult result. If an internal closure references variables bound in the function that creates
the closure, the closure uses the values that these variables had at the time the closure was created. The Continuation attempts to match the remaining portion (specified by the closure's already-bound
arguments) of the pattern against Input, starting at the intermediate state given by its State argument. If the match succeeds, the Continuation returns the final
State that it reached; if the match fails, the Continuation returns
failure.
A Matcher procedure is an internal closure that takes two arguments -- a State and a Continuation -- and returns a MatchResult result. A Matcher attempts to match a middle subpattern
(specified by the closure's already-bound arguments) of the pattern against Input, starting at
the intermediate state given by its State argument. The Continuation
argument should be a closure that matches the rest of the pattern. After matching the subpattern of a pattern to
obtain a new State, the Matcher then calls Continuation on that new State to test if the rest of the pattern can match
as well. If it can, the Matcher returns the State returned by Continuation; if not, the Matcher may try different choices at its choice
points, repeatedly calling Continuation until it either succeeds or all possibilities have
been exhausted.
An AssertionTester procedure is an internal closure that takes a State argument and returns a Boolean result. The assertion tester tests a specific condition
(specified by the closure's already-bound arguments) against the current place in Input and
returns true if the condition matched or false if not.
An EscapeValue is either a character or an integer. An EscapeValue
is used to denote the interpretation of a DecimalEscape escape sequence: a character
ch means that the escape sequence is interpreted as the character ch, while an integer
n means that the escape sequence is interpreted as a backreference to the nth set of capturing parentheses.
The production Pattern::Disjunction evaluates as follows:
Evaluate Disjunction to obtain a Matcher m.
Return an internal closure that takes two arguments, a String str and an integer index, and performs
the following:
If Unicode is true, then let Input be a List of consisting of the sequence of code points of
str interpreted as a UTF-16 encoded Unicode string. Otherwise, let Input be a List of consisting the sequence of code units that are the
elements of str. Input will be used throughout the algorithms in 21.2.2. Each element of Input is considered to be a character.
Let listIndex be the index into Input of the character that was obtained from element index
of str.
Let InputLength be the number of character contained in Input. This variable will be used
throughout the algorithms in 21.2.2.
Let c be a Continuation that always returns its State argument as a successful MatchResult.
Let cap be a List of NcapturingParensundefined values, indexed 1 through NcapturingParens.
Let x be the State (listIndex, cap).
Call m(x, c) and return its result.
NOTE A Pattern evaluates ("compiles") to an internal procedure value. RegExp.prototype.exec can then apply this procedure to a String and an
offset within the String to determine whether the pattern would match starting at exactly that offset within the String,
and, if it does match, what the values of the capturing parentheses would be. The algorithms in 21.2.2 are designed so that compiling a pattern may throw a SyntaxError
exception; on the other hand, once the pattern is successfully compiled, applying its result internal procedure to find
a match in a String cannot throw an exception (except for any host-defined exceptions that can occur anywhere such as
out-of-memory).
The production Disjunction::Alternative evaluates by evaluating Alternative to obtain a Matcher and returning that Matcher.
The production Disjunction::Alternative|Disjunction evaluates as
follows:
Evaluate Alternative to obtain a Matcher m1.
Evaluate Disjunction to obtain a Matcher m2.
Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and
performs the following:
Call m1(x, c) and let r be its result.
If r isn't failure, return r.
Call m2(x, c) and return its result.
NOTE The | regular expression operator separates two alternatives. The pattern
first tries to match the left Alternative (followed by the sequel of the regular expression); if
it fails, it tries to match the right Disjunction (followed by the sequel of the regular
expression). If the left Alternative, the right Disjunction, and the
sequel all have choice points, all choices in the sequel are tried before moving on to the next choice in the left Alternative. If choices in the left Alternative are exhausted, the right Disjunction is tried instead of the left Alternative. Any capturing
parentheses inside a portion of the pattern skipped by | produce undefined values instead of
Strings. Thus, for example,
The production Alternative::[empty] evaluates by returning a Matcher that takes two arguments, a State x
and a Continuation c, and returns the result of calling c(x).
The production Alternative::AlternativeTerm evaluates as follows:
Evaluate Alternative to obtain a Matcher m1.
Evaluate Term to obtain a Matcher m2.
Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and
performs the following:
Create a Continuation d that takes a State argument y and returns the result of calling
m2(y, c).
Call m1(x, d) and return its result.
NOTE Consecutive Terms try to simultaneously match consecutive
portions of Input. If the left Alternative, the right Term, and the sequel of the regular expression all have choice points, all choices in the sequel are
tried before moving on to the next choice in the right Term, and all choices in the right Term are tried before moving on to the next choice in the left Alternative.
The production Term::Assertion evaluates by returning an internal Matcher closure that takes two arguments, a State
x and a Continuation c, and performs the following:
Evaluate Assertion to obtain an AssertionTester t.
Call t(x) and let r be the resulting Boolean value.
If r is false, return failure.
Call c(x) and return its result.
The production Term::Atom evaluates by evaluating Atom to obtain a Matcher and returning
that Matcher.
The production Term::AtomQuantifier evaluates as follows:
Evaluate Atom to obtain a Matcher m.
Evaluate Quantifier to obtain the three results: an integer min, an integer (or ∞) max,
and Boolean greedy.
If max is finite and less than min, then throw a SyntaxError exception.
Let parenIndex be the number of left capturing parentheses in the entire regular expression that occur to
the left of this production expansion's Term. This is the total number of times the Atom::(Disjunction) production is expanded prior to this production's
Term plus the total number of Atom::(Disjunction) productions enclosing
this Term.
Let parenCount be the number of left capturing parentheses in the expansion of this production's
Atom. This is the total number of Atom::(Disjunction)
productions enclosed by this production's Atom.
Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and
performs the following:
Call RepeatMatcher(m, min, max, greedy, x, c, parenIndex,
parenCount) and return its result.
The abstract operation RepeatMatcher takes eight parameters, a
Matcher m, an integer min, an integer (or ∞) max, a Boolean greedy, a
State x, a Continuation c, an integer parenIndex, and an integer parenCount,
and performs the following:
If max is zero, then call c(x) and return its result.
Create an internal Continuation closure d that takes one State argument y and performs the
following:
If min is zero and y's endIndex is equal to x's endIndex, then return
failure.
If min is zero then let min2 be zero; otherwise let min2 be min–1.
If max is ∞, then let max2 be ∞; otherwise let max2 be
max–1.
Call RepeatMatcher(m, min2, max2, greedy, y, c, parenIndex,
parenCount) and return its result.
For every integer k that satisfies parenIndex < k and k ≤
parenIndex+parenCount, set cap[k] to undefined.
Let e be x's endIndex.
Let xr be the State (e, cap).
If min is not zero, then call m(xr, d) and return its result.
If greedy is false, then
Call c(x) and let z be its result.
If z is not failure, return z.
Call m(xr, d) and return its result.
Call m(xr, d) and let z be its result.
If z is not failure, return z.
Call c(x) and return its result.
NOTE 1 An Atom followed by a Quantifier is
repeated the number of times specified by the Quantifier. A Quantifier
can be non-greedy, in which case the Atom pattern is repeated as few times as possible while
still matching the sequel, or it can be greedy, in which case the Atom pattern is repeated as
many times as possible while still matching the sequel. The Atom pattern is repeated rather
than the input character sequence that it matches, so different repetitions of the Atom can
match different input substrings.
NOTE 2 If the Atom and the sequel of the regular expression all
have choice points, the Atom is first matched as many (or as few, if non-greedy) times as
possible. All choices in the sequel are tried before moving on to the next choice in the last repetition of Atom. All choices in the last (nth) repetition of Atom are tried
before moving on to the next choice in the next-to-last (n–1)st repetition of Atom; at which point it may turn out that more or fewer repetitions of Atom
are now possible; these are exhausted (again, starting with either as few or as many as possible) before moving on to
the next choice in the (n-1)st repetition of Atom and so on.
Compare
/a[a-z]{2,4}/.exec("abcdefghi")
which returns "abcde" with
/a[a-z]{2,4}?/.exec("abcdefghi")
which returns "abc".
Consider also
/(aa|aabaac|ba|b|c)*/.exec("aabaac")
which, by the choice point ordering above, returns the array
["aaba", "ba"]
and not any of:
["aabaac", "aabaac"]
["aabaac", "c"]
The above ordering of choice points can be used to write a regular expression that calculates the greatest common
divisor of two numbers (represented in unary notation). The following example calculates the gcd of 10 and 15:
NOTE 3 Step 4 of the RepeatMatcher clears Atom's captures each time Atom is repeated. We can see its behaviour in the regular expression
/(z)((a+)?(b+)?(c))*/.exec("zaacbbbcac")
which returns the array
["zaacbbbcac", "z", "ac", "a", undefined, "c"]
and not
["zaacbbbcac", "z", "ac", "a", "bbb", "c"]
because each iteration of the outermost * clears all captured Strings contained in the quantified
Atom, which in this case includes capture Strings numbered 2, 3, 4, and 5.
NOTE 4 Step 1 of the RepeatMatcher's d closure states that, once the minimum
number of repetitions has been satisfied, any more expansions of Atom that match the empty
character sequence are not considered for further repetitions. This prevents the regular expression engine from
falling into an infinite loop on patterns such as:
The production Assertion::^ evaluates by returning an internal AssertionTester closure that takes a State argument
x and performs the following:
Let e be x's endIndex.
If e is zero, return true.
If Multiline is false, return false.
If the character Input[e–1] is one of LineTerminator, return true.
Return false.
NOTE Even when the y flag is used with a pattern, ^ always
matches only at the beginning of Input, or (if Multiline is true) at the beginning of a line.
The production Assertion::$ evaluates by returning an internal AssertionTester closure that takes a State argument
x and performs the following:
Let e be x's endIndex.
If e is equal to InputLength, return true.
If Multiline is false, return false.
If the character Input[e] is one of LineTerminator, return true.
Return false.
The production Assertion::\b evaluates by returning an internal AssertionTester closure that takes
a State argument x and performs the following:
Let e be x's endIndex.
Call IsWordChar(e–1) and let a be the Boolean result.
Call IsWordChar(e) and let b be the Boolean result.
If a is true and b is false, return true.
If a is false and b is true, return true.
Return false.
The production Assertion::\B evaluates by returning an internal AssertionTester closure that takes
a State argument x and performs the following:
Let e be x's endIndex.
Call IsWordChar(e–1) and let a be the Boolean result.
Call IsWordChar(e) and let b be the Boolean result.
If a is true and b is false, return false.
If a is false and b is true, return false.
Return true.
The production Assertion::(?=Disjunction) evaluates as follows:
Evaluate Disjunction to obtain a Matcher m.
Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and
performs the following steps:
Let d be a Continuation that always returns its State argument as a successful MatchResult.
The production Atom::PatternCharacter evaluates as follows:
Let ch be the character represented by PatternCharacter.
Let A be a one-element CharSet containing the character ch.
Call CharacterSetMatcher(A, false) and return its Matcher result.
The production Atom::. evaluates as follows:
Let A be the set of all characters except LineTerminator.
Call CharacterSetMatcher(A, false) and return its Matcher result.
The production Atom::\AtomEscape evaluates by evaluating AtomEscape to obtain a Matcher
and returning that Matcher.
The production Atom::CharacterClass evaluates as follows:
Evaluate CharacterClass to obtain a CharSet A and a Boolean invert.
Call CharacterSetMatcher(A, invert) and return its Matcher result.
The production Atom::(Disjunction) evaluates as follows:
Evaluate Disjunction to obtain a Matcher m.
Let parenIndex be the number of left capturing parentheses in the entire regular expression that occur to
the left of this production expansion's initial left parenthesis. This is the total number of times the Atom::(Disjunction) production is expanded prior to this production's
Atom plus the total number of Atom::(Disjunction) productions enclosing
this Atom.
Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and
performs the following steps:
Create an internal Continuation closure d that takes one State argument y and performs the
following steps:
The abstract operation Canonicalize takes a character parameter ch and performs the following steps:
If IgnoreCase is false, return ch.
If the file CaseFolding.txt of the Unicode Character Database does not provides a simple or common case folding
mapping for ch, return ch.
Else, Let u be the result of apply that mapping to ch.
If Unicode is true, return u.
If u’s code point > 65535, return ch
If ch's code unit value ≥ 128 and u's code unit value < 128, then return ch.
Return u.
NOTE 1 Parentheses of the form (Disjunction) serve both to group the components of the Disjunction pattern together and to
save the result of the match. The result can be used either in a backreference (\ followed by a nonzero
decimal number), referenced in a replace String, or returned as part of an array from the regular expression matching
internal procedure. To inhibit the capturing behaviour of parentheses, use the form (?:Disjunction) instead.
NOTE 2 The form (?=Disjunction)
specifies a zero-width positive lookahead. In order for it to succeed, the pattern inside Disjunction must match at the current position, but the current position is not advanced before
matching the sequel. If Disjunction can match at the current position in several ways, only
the first one is tried. Unlike other regular expression operators, there is no backtracking into a (?=
form (this unusual behaviour is inherited from Perl). This only matters when the Disjunction
contains capturing parentheses and the sequel of the pattern contains backreferences to those captures.
For example,
/(?=(a+))/.exec("baaabac")
matches the empty String immediately after the first b and therefore returns the array:
["", "aaa"]
To illustrate the lack of backtracking into the lookahead, consider:
/(?=(a+))a*b\1/.exec("baaabac")
This expression returns
["aba", "a"]
and not:
["aaaba", "a"]
NOTE 3 The form (?!Disjunction)
specifies a zero-width negative lookahead. In order for it to succeed, the pattern inside Disjunction must fail to match at the current position. The current position is not advanced before
matching the sequel. Disjunction can contain capturing parentheses, but backreferences to them
only make sense from within Disjunction itself. Backreferences to these capturing parentheses
from elsewhere in the pattern always return undefined because the negative lookahead must fail for the pattern
to succeed. For example,
/(.*?)a(?!(a+)b\2c)\2(.*)/.exec("baaabaac")
looks for an a not immediately followed by some positive number n of a's, a
b, another n a's (specified by the first \2) and a c. The second
\2 is outside the negative lookahead, so it matches against undefined and therefore always
succeeds. The whole expression returns the array:
["baaabaac", "ba", undefined, "abaac"]
In case-insignificant matches all characters are implicitly case-folded using the simple mapping provided by the
Unicode standard immediately before they are compared. The simple mapping always maps to a single code point, so it does
not map, for example "ß" (U+00DF into "SS". It may however map a code point outside the
Basic Latin range to a character within, for example, “ſ” (U+017F) to “s”. Such characters
are not mapped if Unicode is false. This prevents Unicode code points
such as U+0131 and U+017F from matching regular expressions such as /[a‑z]/i, but they will match
/[a‑z]/ui
If s is undefined, then call c(x) and return its result.
Let e be x's endIndex.
Let len be s's length.
Let f be e+len.
If f>InputLength, return failure.
If there exists an integer i between 0 (inclusive) and len (exclusive) such that
Canonicalize(s[i]) is not the same character value as Canonicalize(Input
[e+i]), then return failure.
Let y be the State (f, cap).
Call c(y) and return its result.
The production AtomEscape::CharacterEscape evaluates as follows:
Evaluate CharacterEscape to obtain a character ch.
Let A be a one-element CharSet containing the character ch.
Call CharacterSetMatcher(A, false) and return its Matcher result.
The production AtomEscape::CharacterClassEscape evaluates as follows:
Evaluate CharacterClassEscape to obtain a CharSet A.
Call CharacterSetMatcher(A, false) and return its Matcher result.
NOTE An escape sequence of the form \ followed by a nonzero decimal number
n matches the result of the nth set of capturing parentheses (see 0). It is an error if the
regular expression has fewer than n capturing parentheses. If the regular expression has n or more
capturing parentheses but the nth one is undefined because it has not captured anything, then the
backreference always succeeds.
The production CharacterEscape::ControlEscape evaluates by returning the character according to Table
41.
Table 41 — ControlEscape Character Values
ControlEscape
Character Value
Code Point
Name
Symbol
t
9
U+0009
horizontal tab
<HT>
n
10
U+000A
line feed (new line)
<LF>
v
11
U+000B
vertical tab
<VT>
f
12
U+000C
form feed
<FF>
r
13
U+000D
carriage return
<CR>
The production CharacterEscape::cControlLetter evaluates as follows:
Let ch be the character represented by ControlLetter.
Let i be ch's character value.
Let j be the remainder of dividing i by 32.
Return the character whose character value is j.
The production CharacterEscape::HexEscapeSequence evaluates by evaluating the CV of the HexEscapeSequence
(see 11.8.4) and returning its character result.
The production CharacterEscape::RegExpUnicodeEscapeSequence evaluates by returning the result of evaluating RegExpUnicodeEscapeSequence .
The production CharacterEscape::IdentityEscape evaluates by returning the character represented by IdentityEscape.
The production RegExpUnicodeEscapeSequence::LeadSurragate\uTrailSurragate evaluates as
follows:
Let lead be the result of evaluating LeadSurragate.
Let trail be the result of evaluating TrailSurragate.
The production RegExpUnicodeEscapeSequence::uHex4Digits evaluates by evaluating the CV of Hex4Digits (see 11.8.4.2) and returning its character result.
The production RegExpUnicodeEscapeSequence::u{HexDigits} evaluates by evaluating the MV of
the HexDigits (see 11.8.3.1) and returning its character
result.
The production LeadSurragate::Hex4Digits evaluates by evaluating the CV of Hex4Digits (see 11.8.4.2) and returning its character result.
The production TailSurragate::Hex4Digits evaluates by evaluating the CV of Hex4Digits (see 11.8.4.2) and returning its character result.
The production DecimalEscape::DecimalIntegerLiteral evaluates as follows:
Let i be the MV of DecimalIntegerLiteral.
If i is zero, return the EscapeValue consisting of the character U+0000 (NULL).
Return the EscapeValue consisting of the integer i.
The definition of “the MV of DecimalIntegerLiteral” is in 11.8.3.
NOTE If \ is followed by a decimal number n whose first digit is not
0, then the escape sequence is considered to be a backreference. It is an error if n is greater
than the total number of left capturing parentheses in the entire regular expression. \0 represents the
<NUL> character and cannot be followed by a decimal digit.
The production CharacterClassEscape::d evaluates by returning the ten-element set of characters containing the characters
0 through 9 inclusive.
The production CharacterClassEscape::D evaluates by returning the set of all characters not included in the set returned by CharacterClassEscape::d
.
The production CharacterClassEscape::s evaluates by returning the set of characters containing the characters that are on the
right-hand side of the WhiteSpace (11.2) or LineTerminator (11.3) productions.
The production CharacterClassEscape::S evaluates by returning the set of all characters not included in the set returned by CharacterClassEscape::s
.
The production CharacterClassEscape::w evaluates by returning the set of characters containing the sixty-three characters:
a
b
c
d
e
f
g
h
i
j
k
l
m
n
o
p
q
r
s
t
u
v
w
x
y
z
A
B
C
D
E
F
G
H
I
J
K
L
M
N
O
P
Q
R
S
T
U
V
W
X
Y
Z
0
1
2
3
4
5
6
7
8
9
_
The production CharacterClassEscape::W evaluates by returning the set of all characters not included in the set returned by CharacterClassEscape::w
.
The production NonemptyClassRangesNoDash::ClassAtom evaluates by evaluating ClassAtom to obtain a CharSet and
returning that CharSet.
The production NonemptyClassRangesNoDash::ClassAtomNoDashNonemptyClassRangesNoDash evaluates as follows:
Evaluate ClassAtomNoDash to obtain a CharSet A.
Evaluate NonemptyClassRangesNoDash to obtain a CharSet B.
Return the union of CharSets A and B.
The production NonemptyClassRangesNoDash::ClassAtomNoDash-ClassAtomClassRanges evaluates as follows:
Evaluate ClassAtomNoDash to obtain a CharSet A.
Evaluate ClassAtom to obtain a CharSet B.
Evaluate ClassRanges to obtain a CharSet C.
Call CharacterRange(A, B) and let D be the resulting CharSet.
Return the union of CharSets D and C.
NOTE 1ClassRanges can expand into single ClassAtoms and/or ranges of two ClassAtoms separated by dashes. In the latter
case the ClassRanges includes all characters between the first ClassAtom
and the second ClassAtom, inclusive; an error occurs if either ClassAtom
does not represent a single character (for example, if one is \w) or if the first ClassAtom's
character value is greater than the second ClassAtom's character value.
NOTE 2 Even if the pattern ignores case, the case of the two ends of a range is significant
in determining which characters belong to the range. Thus, for example, the pattern /[E-F]/i matches only
the letters E, F, e, and f, while the pattern /[E-f]/i
matches all upper and lower-case letters in the Unicode Basic Latin block as well as the symbols [,
\, ], ^, _, and `.
NOTE 3 A - character can be treated literally or it can denote a range. It is
treated literally if it is the first or last character of ClassRanges, the beginning or end
limit of a range specification, or immediately follows a range specification.
The production ClassAtomNoDash::SourceCharacterbut not one of\or]or-
evaluates by returning a one-element CharSet containing the character represented by SourceCharacter.
The production ClassAtomNoDash::\ClassEscape evaluates by evaluating ClassEscape
to obtain a CharSet and returning that CharSet.
The production ClassEscape::DecimalEscape evaluates as follows:
Evaluate DecimalEscape to obtain an EscapeValue E.
If E is not a character then throw a SyntaxError exception.
Let ch be E's character.
Return the one-element CharSet containing the character ch.
The production ClassEscape::b evaluates by returning the CharSet containing the one character <BS> U+0008
(BACKSPACE).
The production ClassEscape::CharacterEscape evaluates by evaluating CharacterEscape to obtain a
character and returning a one-element CharSet containing that character.
The production ClassEscape::CharacterClassEscape evaluates by evaluating CharacterClassEscape to
obtain a CharSet and returning that CharSet.
NOTE A ClassAtom can use any of the escape sequences that are allowed
in the rest of the regular expression except for \b, \B, and backreferences. Inside a CharacterClass, \b means the backspace character, while \B and
backreferences raise errors. Using a backreference inside a ClassAtom causes an error.
The RegExp constructor is the %RegExp% intrinsic object and the initial value of the RegExp property of
the global object. When RegExp is called as a function rather than as a constructor, it creates and
initialises a new RegExp object. Thus the function call RegExp(…) is equivalent to the object creation expression new RegExp(…) with the same arguments. However, if the this value
passed in the call is an Object with a [[RegExpMatcher]] internal slot whose value is undefined, it initialises the this value using the argument values. This permits
RegExp to be used both as factory method and to perform constructor instance initialisation.
The RegExp constructor is designed to be subclassable. It may be used as the value of an
extends clause of a class declaration. Subclass constructors that intended to inherit the specified
RegExp behaviour must include a super call to the RegExp constructor to initialise
subclass instances.
If Type(O) is not Object or Type(O) is Object and O does not have a
[[RegExpMatcher]] internal slot or Type(O) is Object and O has a [[RegExpMatcher]] internal slot and the value of [[RegExpMatcher]] is not
undefined, then
If Type(pattern) is Object and O has a
[[RegExpMatcher]] internal slot and flags
is undefined, then
Return pattern;
Let O be the result of calling the abstract operation RegExpAlloc with
argument func.
If Type(pattern) is Object and pattern has a
[[RegExpMatcher]] internal slot, then
If the value of pattern’s [[RegExpMatcher]] internal slot is undefined, then throw a
TypeError exception.
If flags is not undefined, then throw a TypeError exception.
Let P be the value of pattern’s [[OriginalSource]] internal slot.
Let F be the value of pattern’s [[OriginalFlags]] internal slot.
Else,
Let P be pattern.
Let F be flags.
Return the result of the abstract operation RegExpInitialise with arguments
O,P, and F .
NOTE If pattern is supplied using a StringLiteral, the usual escape
sequence substitutions are performed before the String is processed by RegExp. If pattern must contain an escape
sequence to be recognised by RegExp, any backslash \ characters must be escaped within the StringLiteral to prevent them being removed when the contents of the StringLiteral are formed.
When the abstract operation RegExpAlloc with argument constructor is called, the following steps are
taken:
Let obj be the result of calling OrdinaryCreateFromConstructor(constructor,
"%RegExpPrototype%", ( [[RegExpMatcher]], [[OriginalSource]], [[OriginalFlags]])).
Let status be the result of DefinePropertyOrThrow(obj,
"lastIndex", PropertyDescriptor {[[Writable]]: true, [[Enumberable]]: false,
[[Configurable]]: false}).
NOTE [[RegExpMatcher]] is initially assigned the value undefined
as a flag to indicate that the instance has not yet been initialised by the RegExp
constructor. This flag value is never directly exposed to ECMAScript code; hence implementations may choose to encode
the flag in some other manner.
If F contains any character other than "g", "i", "m",
"u", or "y" or if it contains the same character more than once, then throw a
SyntaxError exception.
Parse P interpreted as UTF-16 encoded Unicode code points using the grammars in 21.2.1. If F contains "u" the goal symbol for the parse is
Pattern[U]. Otherwise the goal symbol for the parse is Pattern.Throw a SyntaxError
exception if P did not conform to the grammar or if all characters of P where not matched by the
parse.
Set obj’s [[RegExpMatcher]] internal
slot to the internal procedure obtained by evaluating ("compiling") the step 3’s parse of P and
applying the semantics provided in 21.2.2.
Set the value of obj’s [[OriginalSource]] internal slot to P.
Set the value of obj’s [[OriginalFlags]] internal slot to F.
Let putStatus be the result of Put(obj, "lastIndex",
0, true).
When the abstract operation EscapeRegExpPattern with arguments P and F is called, the following
occurs:
Let S be a String in the form of a Pattern (Pattern[U] if F contains
"u") equivalent to P interpreted as UTF-16 encoded Unicode code points, in which certain code
points are escaped as described below. S may or may not be identical to P; however, the internal
procedure that would result from evaluating S as a Pattern (Pattern[U] if F contains
"u") must behave identically to the internal procedure given by the constructed object's [[RegExpMatcher]]
internal slot. Separate calls to this abstract operation
using the same values for P and F must produce identical results.
The characters / or any LineTerminator occurring in the pattern shall be escaped
in S as necessary to ensure that the String value formed by concatenating the Strings "/",
S, "/", and F can be parsed (in an appropriate lexical context) as a RegularExpressionLiteral that behaves identically to the constructed regular expression. For example,
if P is "/", then S could be "\/" or "\u002F", among other
possibilities, but not "/", because /// followed by F would be parsed as a SingleLineComment rather than a RegularExpressionLiteral. If P is
the empty String, this specification can be met by letting S be "(?:)".
The RegExp prototype object is an ordinary object. It is not a RegExp instance and does not have a [[RegExpMatcher]] internal slot or any of the other internal slots of RegExp
instance objects.
The value of the [[Prototype]] internal slot of the
RegExp prototype object is the standard built-in Object prototype object (19.1.3).
The RegExp prototype object does not have a valueOf property of its own; however, it inherits the
valueOf property from the Object prototype object.
Performs a regular expression match of string against the regular expression and returns an Array object
containing the results of the match, or null if string did not match.
The String ToString(string) is
searched for an occurrence of the regular expression pattern as follows:
Let R be the this value.
If Type(R) is not Object, then throw a TypeError
exception.
If R does not have a [[RegExpMatcher]] internal
slot, then throw a TypeError exception.
If the value of R’s [[RegExpMatcher]] internal slot is undefined, then throw a
TypeError exception.
If searchValue.global is false, then search string for the first match of the regular
expression searchValue. If searchValue.global is true, then search string for all
matches of the regular expression searchValue. Do the search in the same manner as in RegExp.prototype.match, including the update of
searchValue.lastIndex. Let m be the number of left capturing parentheses in
searchValue (using NcapturingParens as specified in 21.2.2.1).
If replaceValue is a function, then
For each matched substring, call the function with the following m + 3 arguments. Argument 1 is the
substring that matched. If searchValue is a regular expression, the next m arguments are all of
the captures in the MatchResult (see 21.2.2.1). Argument m + 2 is the offset
within string where the match occurred, and argument m + 3 is string. The result is a
String value derived from the original input by replacing each matched substring with the corresponding return
value of the function call, converted to a String if need be.
Else,
Let newstring denote the result of converting replaceValue to a String. The result is a String
value derived from the original input String by replacing each matched substring with a String derived from
newstring by replacing elements in newstring by replacement text as specified in Table 39. These $ replacements are done left-to-right, and, once such a
replacement is performed, the new replacement text is not subject to further replacements. For example,
"$1,$2".replace(/(\$(\d))/g, "$$1-$1$2") returns "$1-$11,$1-$22". A $ in
newstring that does not match any of the forms below is left as is.
Search the value string from its beginning for an occurrence of the regular expression pattern rx. Let
result be a Number indicating the offset within string where the pattern matched, or –1 if there
was no match. If an abrupt completion occurs during the
search, result is that Completion Record. The
lastIndex and global properties of regexp are ignored when performing the search.
The lastIndex property of regexp is left unchanged.
Returns an Array object into which substrings of the result of converting string to a String have been
stored. The substrings are determined by searching from left to right for matches of the this value regular
expression; these occurrences are not part of any substring in the returned array, but serve to divide up the String
value.
The this value may be an empty regular expression or a regular expression that can match an empty String. In
this case, regular expression does not match the empty substring at the beginning or end of the input String, nor does it
match the empty substring at the end of the previous separator match. (For example, if the regular expression matches the
empty String, the String is split up into individual code unit elements; the length of the result array equals the length
of the String, and each substring contains one code unit.) Only the first match at a given position of the this
String is considered, even if backtracking could yield a non-empty-substring match at that position. (For example,
/a*?/.split("ab") evaluates to the array ["a","b"], while /a*/.split("ab")
evaluates to the array["","b"].)
If the string is (or converts to) the empty String, the result depends on whether the regular expression can
match the empty String. If it can, the result array contains no elements. Otherwise, the result array contains one
element, which is the empty String.
If the regular expression that contains capturing parentheses, then each time separator is matched the
results (including any undefined results) of the capturing parentheses are spliced into the output array.
For example,
RegExp instances are ordinary objects that inherit properties from the RegExp prototype object. RegExp instances have
internal slots [[RegExpMatcher]], [[OriginalSource]], and [[OriginalFlags]]. The value of the [[RegExpMatcher]] internal
slot is an implementation dependent representation of the Pattern of the RegExp object.
NOTE Prior to the 6th Edition, RegExp instances were specified as
having the own data properties source, global, ignoreCase, and
multiline. Those properties are now specified as accessor properties of RegExp.prototype.
RegExp instances also have the following property:
The value of the lastIndex property specifies the String position at which to start the next match. It is
coerced to an integer when used (see 21.2.5.2). This property shall have the
attributes { [[Writable]]: true, [[Enumerable]]: false, [[Configurable]]: false }.
Array objects are exotic objects that give special treatment to a certain class of property names. See 9.4.2 for a definition of this special treatment.
An Array object, O, is said to be sparse if the following algorithm returns true:
The Array constructor is the %Array% intrinsic object and the initial value of the Array property of the
global object. When Array is called as a function rather than as a constructor, it creates and initialises a
new Array object. Thus the function call Array(…) is
equivalent to the object creation expression new Array(…) with the same arguments. However, if the this value passed
in the call is an Object with an [[ArrayInitialisationState]] internal slot whose value is undefined, it initialises the this value using the argument values. This permits
Array to be used both as factory method and to perform constructor instance initialisation.
The Array constructor is designed to be subclassable. It may be used as the value of an
extends clause of a class declaration. Subclass constructors that intended to inherit the specified
Array behaviour must include a super call to the Array constructor to initialise
subclass instances.
Let mappedValue be the result of calling the [[Call]] internal method of mapfn with
T as thisArgument and a List
containing nextValue as argumentsList.
Let mappedValue be the result of calling the [[Call]] internal method of mapfn with
T as thisArgument and a List
containing kValue, k, and items as argumentsList.
NOTE The from function is an intentionally generic factory method; it does not
require that its this value be the Array constructor. Therefore it can be transferred to or inherited by any
other constructors that may be called with a single numeric argument.
NOTE 1 The items argument is assumed to be a well-formed rest argument value.
NOTE 2 The of function is an intentionally generic factory method; it does not
require that its this value be the Array constructor. Therefore it can be transferred to or inherited by other
constructors that may be called with a single numeric argument.
Let obj be the result of calling ArrayCreate with arguments undefined
and proto.
Return obj.
The value of the name property of this function is "[Symbol.create]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]:
true }.
NOTE 1 Passing undefined as the first argument to ArrayCreate causes the
[[ArrayInitialisationState]] internal slot of the array to
be initially assigned the value false. This is a flag used to
indicate that the instance has not yet been initialised by the Array constructor. This flag value is never
directly exposed to ECMAScript code; hence implementations may choose to encode the flag in any unobservable manner.
NOTE 2 The Array @@create function is intentionally generic; it does not require
that its this value be the Array constructor object. It can be transferred to other constructor functions for use
as a @@create method. When used with other constructors, this function will create an exotic Array object
whose [[Prototype]] value is obtained from the associated constructor.
The value of the [[Prototype]] internal slot of the Array
prototype object is the intrinsic object %ObjectPrototype%.
The Array prototype object is itself an ordinary object. It is not an Array instance and does not have a
length property .
NOTE The Array prototype object does not have a valueOf property of its own;
however, it inherits the valueOf property from the standard built-in Object prototype Object.
When the concat method is called with zero or more arguments item1, item2, etc.,
it returns an array containing the array elements of the object followed by the array elements of each argument in
order.
The following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
Let items be a List whose first element is O
and whose subsequent elements are, in left to right order, the arguments that were passed to this function
invocation.
Repeat, while items is not empty
Remove the first element from items and let E be the value of the element.
NOTE 1 The explicit setting of the length property in step 10 is necessary to
ensure that its value is correct in situations where the trailing elements of the result Array are not present.
NOTE 2 The concat function is intentionally generic; it does not require that
its this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a
method. Whether the concat function can be applied successfully to an exotic object that is not an Array
is implementation-dependent.
22.1.3.1.1 IsConcatSpreadable ( O ) Abstract Operation
The abstract operation IsConcatSpreadable with argument O performs the following steps:
The initial value of Array.prototype.constructor is the standard built-in Array
constructor.
22.1.3.3 Array.prototype.copyWithin (target, start, end = this.length)
The copyWithin method takes up to three arguments target, start and end.
The end argument is optional with the length of the this object as its default value. If
target is negative, it is treated as length+target where length is the length of the array. If start is
negative, it is treated as length+start. If end
is negative, it is treated as length+end. The following
steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
The length property of the copyWithin method is 2.
NOTE 1 The copyWithin function is intentionally generic; it does not require
that its this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a
method. Whether the copyWithin function can be applied successfully to an exotic object that is not an
Array is implementation-dependent.
callbackfn should be a function that accepts three arguments and returns a value that is coercible to the
Boolean value true or false. every calls callbackfn once for each element present in
the array, in ascending order, until it finds one where callbackfn returns false. If such an element is
found, every immediately returns false. Otherwise, if callbackfn returned true for
all elements, every will return true. callbackfn is called only for elements of the array
which actually exist; it is not called for missing elements of the array.
If a thisArg parameter is provided, it will be used as the this value for each invocation of
callbackfn. If it is not provided, undefined is used instead.
callbackfn is called with three arguments: the value of the element, the index of the element, and the
object being traversed.
every does not directly mutate the object on which it is called but the object may be mutated by the calls
to callbackfn.
The range of elements processed by every is set before the first call to callbackfn. Elements
which are appended to the array after the call to every begins will not be visited by callbackfn.
If existing elements of the array are changed, their value as passed to callbackfn will be the value at the
time every visits them; elements that are deleted after the call to every begins and before
being visited are not visited. every acts like the "for all" quantifier in mathematics. In particular, for an
empty array, it returns true.
When the every method is called with one or two arguments, the following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
Let testResult be the result of calling the [[Call]] internal method of callbackfn with
T as thisArgument and a List containing
kValue, k, and O as argumentsList.
NOTE The every function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the every function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
22.1.3.6 Array.prototype.fill (value, start = 0, end = this.length)
The fill method takes up to three arguments value, start and end. The
start and end arguments are optional with default values of 0 and the length of the this
object. If start is negative, it is treated as length+start where length is the length of the array. If end is
negative, it is treated as length+end. The following steps
are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
NOTE 1 The fill function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the fill function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
callbackfn should be a function that accepts three arguments and returns a value that is coercible to the
Boolean value true or false. filter calls callbackfn once for each element in the
array, in ascending order, and constructs a new array of all the values for which callbackfn returns
true. callbackfn is called only for elements of the array which actually exist; it is not called for
missing elements of the array.
If a thisArg parameter is provided, it will be used as the this value for each invocation of
callbackfn. If it is not provided, undefined is used instead.
callbackfn is called with three arguments: the value of the element, the index of the element, and the
object being traversed.
filter does not directly mutate the object on which it is called but the object may be mutated by the
calls to callbackfn.
The range of elements processed by filter is set before the first call to callbackfn. Elements
which are appended to the array after the call to filter begins will not be visited by callbackfn.
If existing elements of the array are changed their value as passed to callbackfn will be the value at the time
filter visits them; elements that are deleted after the call to filter begins and before being
visited are not visited.
When the filter method is called with one or two arguments, the following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
Let selected be the result of calling the [[Call]] internal method of callbackfn with T
as thisArgument and a List containing
kValue, k, and O as argumentsList.
NOTE The filter function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the filter function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
predicate should be a function that accepts three arguments and returns a value that is coercible to the
Boolean value true or false. find calls
predicate once for each element present in the array, in ascending order, until it finds one where
predicate returns true. If such an element is found, find immediately
returns that element value. Otherwise, find returns undefined.
predicate is called only for elements of the array which actually exist; it is not called for missing elements
of the array.
If a thisArg parameter is provided, it will be used as the this value for each invocation of
predicate. If it is not provided, undefined is used instead.
predicate is called with three arguments: the value of the element, the index of the element, and the object
being traversed.
find does not directly mutate the object on which it is called but the object may be mutated by the calls
to predicate.
The range of elements processed by find is set before the first call to callbackfn. Elements
that are appended to the array after the call to find begins will not be visited by callbackfn. If
existing elements of the array are changed, their value as passed to predicate will be the value at the time
that find visits them; elements that are deleted after the call to find begins and before being
visited are not visited.
When the find method is called with one or two arguments, the following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
Let testResult be the result of calling the [[Call]] internal method of predicate with
T as thisArgument and a List containing
kValue, k, and O as argumentsList.
NOTE The find function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the find function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
predicate should be a function that accepts three arguments and returns a value that is coercible to the
Boolean value true or false. findIndex calls predicate once for each element present
in the array, in ascending order, until it finds one where predicate returns true. If such an element is
found, findIndex immediately returns the index of that element value. Otherwise, findIndex
returns -1. predicate is called only for elements of the array which actually exist; it is not called for
missing elements of the array.
If a thisArg parameter is provided, it will be used as the this value for each invocation of
predicate. If it is not provided, undefined is used instead.
predicate is called with three arguments: the value of the element, the index of the element, and the object
being traversed.
findIndex does not directly mutate the object on which it is called but the object may be mutated by the
calls to predicate.
The range of elements processed by findIndex is set before the first call to callbackfn.
Elements that are appended to the array after the call to findIndex begins will not be visited by
callbackfn. If existing elements of the array are changed, their value as passed to predicate will
be the value at the time that findIndex visits them; elements that are deleted after the call to
findIndex begins and before being visited are not visited.
When the findIndex method is called with one or two arguments, the following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
Let testResult be the result of calling the [[Call]] internal method of predicate with
T as thisArgument and a List containing
kValue, k, and O as argumentsList.
NOTE The findIndex function is intentionally generic; it does not require that
its this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the findIndex function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
callbackfn should be a function that accepts three arguments. forEach calls
callbackfn once for each element present in the array, in ascending order. callbackfn is called only
for elements of the array which actually exist; it is not called for missing elements of the array.
If a thisArg parameter is provided, it will be used as the this value for each invocation of
callbackfn. If it is not provided, undefined is used instead.
callbackfn is called with three arguments: the value of the element, the index of the element, and the
object being traversed.
forEach does not directly mutate the object on which it is called but the object may be mutated by the
calls to callbackfn.
The range of elements processed by forEach is set before the first call to callbackfn. Elements
which are appended to the array after the call to forEach begins will not be visited by
callbackfn. If existing elements of the array are changed, their value as passed to callback will be the value
at the time forEach visits them; elements that are deleted after the call to forEach begins and
before being visited are not visited.
When the forEach method is called with one or two arguments, the following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
Let funcResult be the result of calling the [[Call]] internal method of callbackfn with
T as thisArgument and a List containing
kValue, k, and O as argumentsList.
NOTE The forEach function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the forEach function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
indexOf compares searchElement to the elements of the array, in ascending order, using the
Strict Equality Comparison algorithm (7.2.10), and if found at one or more
positions, returns the index of the first such position; otherwise, -1 is returned.
The optional second argument fromIndex defaults to 0 (i.e. the whole array is searched). If it is greater
than or equal to the length of the array, -1 is returned, i.e. the array will not be searched. If it is negative, it is
used as the offset from the end of the array to compute fromIndex. If the computed index is less than 0, the
whole array will be searched.
When the indexOf method is called with one or two arguments, the following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
Let same be the result of performing Strict Equality Comparison searchElement ===
elementK.
If same is true, return k.
Increase k by 1.
Return -1.
The length property of the indexOf method is 1.
NOTE The indexOf function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the indexOf function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
The elements of the array are converted to Strings, and these Strings are then concatenated, separated by occurrences
of the separator. If no separator is provided, a single comma is used as the separator.
The join method takes one argument, separator, and performs the following steps:
Let O be the result of calling ToObject passing the this value as the
argument.
Let R be a String value produced by concatenating S and next.
Increase k by 1.
Return R.
The length property of the join method is 1.
NOTE The join function is intentionally generic; it does not require that its
this value be an Array object. Therefore, it can be transferred to other kinds of objects for use as a method.
Whether the join function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
lastIndexOf compares searchElement to the elements of the array in descending order using the
Strict Equality Comparison algorithm (7.2.10), and if found at one or more
positions, returns the index of the last such position; otherwise, -1 is returned.
The optional second argument fromIndex defaults to the array's length minus one (i.e. the whole array is
searched). If it is greater than or equal to the length of the array, the whole array will be searched. If it is negative,
it is used as the offset from the end of the array to compute fromIndex. If the computed index is less than 0,
-1 is returned.
When the lastIndexOf method is called with one or two arguments, the following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
Let same be the result of performing Strict Equality Comparison searchElement ===
elementK.
If same is true, return k.
Decrease k by 1.
Return -1.
The length property of the lastIndexOf method is 1.
NOTE The lastIndexOf function is intentionally generic; it does not require that
its this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the lastIndexOf function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
callbackfn should be a function that accepts three arguments. map calls callbackfn
once for each element in the array, in ascending order, and constructs a new Array from the results. callbackfn
is called only for elements of the array which actually exist; it is not called for missing elements of the array.
If a thisArg parameter is provided, it will be used as the this value for each invocation of
callbackfn. If it is not provided, undefined is used instead.
callbackfn is called with three arguments: the value of the element, the index of the element, and the
object being traversed.
map does not directly mutate the object on which it is called but the object may be mutated by the calls
to callbackfn.
The range of elements processed by map is set before the first call to callbackfn. Elements
which are appended to the array after the call to map begins will not be visited by callbackfn. If
existing elements of the array are changed, their value as passed to callbackfn will be the value at the time
map visits them; elements that are deleted after the call to map begins and before being visited
are not visited.
When the map method is called with one or two arguments, the following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
Let mappedValue be the result of calling the [[Call]] internal method of callbackfn with
T as thisArgument and a List containing
kValue, k, and O as argumentsList.
NOTE The map function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the map function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
NOTE The pop function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the pop function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
The arguments are appended to the end of the array, in the order in which they appear. The new length of the array is
returned as the result of the call.
When the push method is called with zero or more arguments item1, item2, etc., the
following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
NOTE The push function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the push function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
callbackfn should be a function that takes four arguments. reduce calls the callback, as a
function, once for each element present in the array, in ascending order.
callbackfn is called with four arguments: the previousValue (or value from the previous call to
callbackfn), the currentValue (value of the current element), the currentIndex, and the object
being traversed. The first time that callback is called, the previousValue and currentValue can be one of
two values. If an initialValue was provided in the call to reduce, then previousValue will
be equal to initialValue and currentValue will be equal to the first value in the array. If no
initialValue was provided, then previousValue will be equal to the first value in the array and
currentValue will be equal to the second. It is a TypeError if the array contains no elements and
initialValue is not provided.
reduce does not directly mutate the object on which it is called but the object may be mutated by the
calls to callbackfn.
The range of elements processed by reduce is set before the first call to callbackfn. Elements
that are appended to the array after the call to reduce begins will not be visited by callbackfn.
If existing elements of the array are changed, their value as passed to callbackfn will be the value at the
time reduce visits them; elements that are deleted after the call to reduce begins and before
being visited are not visited.
When the reduce method is called with one or two arguments, the following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
Let accumulator be the result of calling the [[Call]] internal method of callbackfn with
undefined as thisArgument and a List
containing accumulator, kValue, k, and O as argumentsList.
NOTE The reduce function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the reduce function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
callbackfn should be a function that takes four arguments. reduceRight calls the callback, as a
function, once for each element present in the array, in descending order.
callbackfn is called with four arguments: the previousValue (or value from the previous call to
callbackfn), the currentValue (value of the current element), the currentIndex, and the
object being traversed. The first time the function is called, the previousValue and currentValue
can be one of two values. If an initialValue was provided in the call to reduceRight, then
previousValue will be equal to initialValue and currentValue will be equal to the last
value in the array. If no initialValue was provided, then previousValue will be equal to the last
value in the array and currentValue will be equal to the second-to-last value. It is a TypeError if the
array contains no elements and initialValue is not provided.
reduceRight does not directly mutate the object on which it is called but the object may be mutated by the
calls to callbackfn.
The range of elements processed by reduceRight is set before the first call to callbackfn.
Elements that are appended to the array after the call to reduceRight begins will not be visited by
callbackfn. If existing elements of the array are changed by callbackfn, their value as passed to
callbackfn will be the value at the time reduceRight visits them; elements that are deleted after
the call to reduceRight begins and before being visited are not visited.
When the reduceRight method is called with one or two arguments, the following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
Let accumulator be the result of calling the [[Call]] internal method of callbackfn with
undefined as thisArgument and a List
containing accumulator, kValue, k, and O as argumentsList.
The length property of the reduceRight method is 1.
NOTE The reduceRight function is intentionally generic; it does not require that
its this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the reduceRight function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
NOTE The reverse function is intentionally generic; it does not require that its
this value be an Array object. Therefore, it can be transferred to other kinds of objects for use as a method.
Whether the reverse function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
NOTE The shift function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the shift function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
The slice method takes two arguments, start and end, and returns an array containing
the elements of the array from element start up to, but not including, element end (or through the
end of the array if end is undefined). If start is negative, it is treated as length+start where length is the length of the array.
If end is negative, it is treated as length+end
where length is the length of the array. The following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
NOTE 1 The explicit setting of the length property of the result Array in step
19 is necessary to ensure that its value is correct in situations where the trailing elements of the result Array are
not present.
NOTE 2 The slice function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the slice function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
callbackfn should be a function that accepts three arguments and returns a value that is coercible to the
Boolean value true or false. some calls callbackfn once for each element present in
the array, in ascending order, until it finds one where callbackfn returns true. If such an element is
found, some immediately returns true. Otherwise, some returns false.
callbackfn is called only for elements of the array which actually exist; it is not called for missing elements
of the array.
If a thisArg parameter is provided, it will be used as the this value for each invocation of
callbackfn. If it is not provided, undefined is used instead.
callbackfn is called with three arguments: the value of the element, the index of the element, and the
object being traversed.
some does not directly mutate the object on which it is called but the object may be mutated by the calls
to callbackfn.
The range of elements processed by some is set before the first call to callbackfn. Elements
that are appended to the array after the call to some begins will not be visited by callbackfn. If
existing elements of the array are changed, their value as passed to callbackfn will be the value at the time
that some visits them; elements that are deleted after the call to some begins and before being
visited are not visited. some acts like the "exists" quantifier in mathematics. In particular, for an empty
array, it returns false.
When the some method is called with one or two arguments, the following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
Let testResult be the result of calling the [[Call]] internal method of callbackfn with
T as thisArgument and a List containing
kValue, k, and O as argumentsList.
NOTE The some function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the some function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
The elements of this array are sorted. The sort is not necessarily stable (that is, elements that compare equal do
not necessarily remain in their original order). If comparefn is not undefined, it should be a
function that accepts two arguments x and y and returns a negative value if x<y, zero if x=y, or a positive value if x>y.
Upon entry, the following steps are performed to initialise evaluation of the sort function:
Let obj be the result of calling ToObject passing the this value as the
argument.
The result of the sort function is then determined as follows:
If comparefn is not undefined and is not a consistent comparison function for the elements of this
array (see below), the behaviour of sort is implementation-defined.
Let proto be the result of calling the [[GetPrototypeOf]] internal method of obj. If
proto is not null and there exists an integer j such that all of the conditions below are
satisfied then the behaviour of sort is implementation-defined:
The behaviour of sort is also implementation defined if obj is sparse and any of the
following conditions are true:
The result of the predicate IsExtensible(obj) is false.
Any array index property of obj whose name is a nonnegative integer less than len is a data
property whose [[Configurable]] attribute is false.
The behaviour of sort is also implementation defined if any array index property of obj whose
name is a nonnegative integer less than len is an accessor property or is a data property whose [[Writable]]
attribute is false.
Otherwise, the following steps are taken.
Perform an implementation-dependent sequence of calls to the [[Get]] and [[Set]] internal methods of obj,
to the DeletePropertyOrThrow abstract operation with obj as the
first argument, and to SortCompare (described below), where the property key argument for each call to [[Get]], [[Set]], or DeletePropertyOrThrow is the string representation of a nonnegative integer
less than len and where the arguments for calls to SortCompare are results
of previous calls to the [[Get]] internal method. If obj is not sparse then DeletePropertyOrThrow must not be called. If any [[Set]] call returns
false a TypeError exception is thrown. If an abrupt completion is returned from any of these operations,
it is immediately returned as the value of this function.
Return obj.
The returned object must have the following two properties.
There must be some mathematical permutation π of the
nonnegative integers less than len, such that for every nonnegative integer j less than
len, if property old[j] existed, then new[π(j)] is exactly the same value as old[j],. But if property old[j] did not exist, then new[π(j)] does not exist.
Then for all nonnegative integers j and k, each less than len, if SortCompare(j,k) < 0
(see SortCompare below), then π(j) <π(k).
Here the notation old[j] is used to refer to the
hypothetical result of calling the [[Get]] internal method of obj with argument j before this
function is executed, and the notation new[j] to refer to the
hypothetical result of calling the [[Get]] internal method of obj with argument j after this
function has been executed.
A function comparefn is a consistent comparison function for a set of values S if all of the
requirements below are met for all values a, b, and c (possibly the same value) in the
set S: The notation a <CFb means comparefn(a,b) < 0; a =CFb means comparefn(a,b) = 0 (of either sign); and a >CFb means comparefn(a,b) > 0.
Calling comparefn(a,b) always returns the same value v when given a specific pair of
values a and b as its two arguments. Furthermore, Type(v) is Number, and v is not NaN. Note that this
implies that exactly one of a <CFb,
a =CFb, and a >CFb will be true for a
given pair of a and b.
Calling comparefn(a,b) does not modify obj.
a =CFa (reflexivity)
If a =CFb, then b =CFa (symmetry)
If a =CFb and b =CFc, then
a =CFc (transitivity of =CF)
If a <CFb and b <CFc, then
a <CFc (transitivity of <CF)
If a >CFb and b >CFc, then
a >CFc (transitivity of >CF)
NOTE 1 The above conditions are necessary and sufficient to ensure that
comparefn divides the set S into equivalence classes and that these equivalence classes are
totally ordered.
NOTE 2 The sort function is intentionally generic; it does not require that
its this value be an Array object. Therefore, it can be transferred to other kinds of objects for use as a
method. Whether the sort function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
If IsCallable(comparefn) is false, throw a TypeError
exception.
Return the result of calling the [[Call]] internal method of comparefn passing undefined as
thisArgument and with a List containing the
values of x and y as the argumentsList.
NOTE Because non-existent property values always compare greater than undefined
property values, and undefined always compares greater than any other value, undefined property values
always sort to the end of the result, followed by non-existent property values.
When the splice method is called with two or more arguments start, deleteCount and
(optionally) item1, item2, etc., the deleteCount elements of the array starting at
integer index start are replaced by the arguments item1, item2, etc. An Array object
containing the deleted elements (if any) is returned. The following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
Let items be a List whose elements are, in left to
right order, the portion of the actual argument list starting with item1. The list will be empty if no such
items are present.
NOTE 1 The explicit setting of the length property of the result Array in step
18 is necessary to ensure that its value is correct in situations where its trailing elements are not present.
NOTE 2 The splice function is intentionally generic; it does not require that
its this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the splice function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
The elements of the array are converted to Strings using their toLocaleString methods, and these Strings
are then concatenated, separated by occurrences of a separator String that has been derived in an implementation-defined
locale-specific way. The result of calling this function is intended to be analogous to the result of
toString, except that the result of this function is intended to be locale-specific.
The result is calculated as follows:
Let array be the result of calling ToObject passing the this value as the
argument.
Let separator be the String value for the list-separator String appropriate for the host environment’s
current locale (this is derived in an implementation-defined way).
If len is zero, return the empty String.
Let firstElement be the result of Get(array, "0").
Let R be a String value produced by concatenating S and R.
Increase k by 1.
Return R.
NOTE 1 The first parameter to this function is likely to be used in a future version of this
standard; it is recommended that implementations do not use this parameter position for anything else.
NOTE 2 The toLocaleString function is intentionally generic; it does not require
that its this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a
method. Whether the toLocaleString function can be applied successfully to an exotic object that is not an
Array is implementation-dependent.
Return the result of calling the [[Call]] internal method of func providing array as
thisArgument and an empty List as
argumentsList.
NOTE The toString function is intentionally generic; it does not require that
its this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the toString function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
The arguments are prepended to the start of the array, such that their order within the array is the same as the order
in which they appear in the argument list.
When the unshift method is called with zero or more arguments item1, item2, etc.,
the following steps are taken:
Let O be the result of calling ToObject passing the this value as the
argument.
NOTE The unshift function is intentionally generic; it does not require that its
this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
Whether the unshift function can be applied successfully to an exotic object that is not an Array is
implementation-dependent.
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false,
[[Configurable]]: true }.
NOTE The elements of this array are property names that were not included as standard
properties of Array.prototype prior to the sixth edition of this specification. These names are ignored for
with statement binding purposes in order to preserve the behaviour of existing code that might use one of
these names as a binding in an outer scope that is shadowed by a with statement whose binding object is an
Array object.
Array instances are exotic Array objects and have the internal methods specified for such objects. Array instances
inherit properties from the Array prototype object. Array instances also have an [[ArrayInitialisationState]] internal slot.
Array instances have a length property, and a set of enumerable properties with array index names.
The length property of this Array object is a data property whose value is always numerically greater than
the name of every deletable property whose name is an array index.
The length property initially has the attributes {
[[Writable]]: true, [[Enumerable]]: false, [[Configurable]]: false }.
NOTE Attempting to set the length property of an Array object to a value that is numerically
less than or equal to the largest numeric property name of an existing array indexed non-deletable property of the array
will result in the length being set to a numeric value that is one greater than that largest numeric property name. See
9.4.2.1.
An Array Iterator is an object, that represents a specific iteration over some specific Array instance object. There is
not a named constructor for Array Iterator objects. Instead, Array iterator objects are created by calling certain
methods of Array instance objects.
Several methods of Array objects return Iterator objects. The abstract operation CreateArrayIterator with arguments
array and kind is used to create such iterator objects. It performs the following steps:
All Array Iterator Objects inherit properties from the %ArrayIteratorPrototype% intrinsic object. The
%ArrayIteratorPrototype% object is an ordinary object and its [[Prototype]] internal slot is the %ObjectPrototype% intrinsic object. In
addition, %ArrayIteratorPrototype% has the following properties:
Array Iterator instances are ordinary objects that inherit properties from the %ArrayIteratorPrototype% intrinsic
object. Array Iterator instances are initially created with the internal slots listed in Table
42.
Table 42 — Internal Slots of Array Iterator Instances
Internal Slot
Description
[[IteratedObject]]
The object whose array elements are being iterated.
[[ArrayIteratorNextIndex]]
The integer index of the next array index to be examined by this iteration.
[[ArrayIterationKind]]
A string value that identifies what is to be returned for each element of the iteration. The possible values are: "key", "value", "key+value", "sparse:key", "sparse:value", "sparse:key+value".
TypedArray objects present an array-like view of an underlying binary data buffer (24.1). Each element of a TypedArray instance has the same underlying binary
scalar data type. There is a distinct TypedArray constructor. Listed in Table 43, for each of
the nine supported element types. For each constructor in Table 43 have a corresponding distinct
prototype object.
In the definitions below, references to TypedArray should be replaced with the appropriate constructor name from
the above table. The phrase “the element size in bytes” refers to the value in the Element Size column of the
table in the row corresponding to the constructor. The phrase “element Type” refers to the value in the Element
Type column for that row.
The %TypedArray% intrinsic object is a constructor-like function object that all of the TypedArray constructor
object inherit from. %TypedArray% and its corresponding prototype object provide common properties that are inherited by
all TypedArray constructors and their instances. The %TypedArray% intrinsic does not have a global name or appear
as a property of the global object.
If the this value passed in the call is an Object with a [[ViewedArrayBuffer]] internal slot whose value is undefined, it initialises the this value using the argument values. This permits super
invocation of the TypedArray constructors by TypedArray subclasses.
The %TypedArray% intrinsic function object is designed to act as the superclass of the various TypedArray
constructors. Those constructors use %TypedArray% to initialise their instances by invoking %TypedArray% as if by making a
super call. The %TypedArray% intrinsic function is not designed to be directly called in any other way. If
%TypedArray% is directly called or called as part of a new expression an exception is thrown.
The actual behaviour of a super call of %TypedArray% depends upon the number and kind of arguments that
are passed to it.
This description applies if and only if the %TypedArray% function is called with at least one argument and the Type of
the first argument is Object and that object has a [[TypedArrayName]] internal slot.
%TypedArray%called with argument typedArray performs the following steps:
This description applies if and only if the %TypedArray% function is called with at least one argument and the Type of
first argument is Object and that object does not have either a [[TypedArrayName]] or an [[ArrayBufferData]] internal slot.
%TypedArray% called with argument array performs the following steps:
Assert: Type(array) is Object and array does not have either
a [[TypedArrayName]] or an [[ArrayBufferData]] internal
slot.
Let O be the this value.
Let srcArray be array.
If Type(O) is not Object or if O does not have a
[[TypedArrayName]] internal slot, then throw a
TypeError exception.
If the value of O’s [[TypedArrayName]] internal slot is undefined, then throw a
TypeError exception.
This description applies if and only if the %TypedArray% function is called with at least one argument and the Type of
the first argument is Object and that object has an [[ArrayBufferData]] internal slot.
%TypedArray% called with arguments buffer, byteOffset, and
length performs the following steps:
Set O’s [[ArrayLength]] internal slot to
newByteLength /elementSize .
Return O.
22.2.1.5 %TypedArray% ( all other argument combinations )
If the %TypedArray% function is called with arguments that do not match any of the preceeding argument descriptions a
TypeError exception is thrown.
22.2.2 Properties of the %TypedArray% Intrinsic Object
The %TypedArray% intrinsic object is a built-in function object. The value of the [[Prototype]] internal slot of %TypedArray% is the Function prototype object
(19.2.3).
Besides a length property whose value is 3 and a name property whose value is
"TypedArray", %TypedArray% has the following properties:
Let mappedValue be the result of calling the [[Call]] internal method of mapfn with T
as thisArgument and a List containing
kValue, k, and items as argumentsList.
NOTE The from function is an intentionally generic factory method; it does not
require that its this value be a Typed Array constructor. Therefore it can be transferred to or inherited by any
other constructors that may be called with a single numeric argument. This function uses [[Put]] to store elements into
a newly created object and assume that the constructor sets the length property of the new object to the
argument value passed to it.
NOTE 1 The items argument is assumed to be a well-formed rest argument value.
NOTE 2 The of function is an intentionally generic factory method; it does not
require that its this value be a TypedArray constructor. Therefore it can be transferred to or inherited
by other constructors that may be called with a single numeric argument. However, it does assume that constructor
creates and initialises a length property that is initialised to its argument value.
Add a [[ViewedArrayBuffer]] internal slot to
obj and set its initial value to undefined.
Add a [[TypedArrayName]] internal slot to obj
and set its initial value to undefined .
Add a [[ByteLength]] internal slot to obj and
set its initial value to 0.
Add a [[ByteOffset]] internal slot to obj and
set its initial value to 0.
Add an [[ArrayLength]] internal slot to obj and
set its initial value to 0.
Return obj.
The value of the name property of this function is "[Symbol.create]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: true }.
22.2.3 Properties of the %TypedArrayPrototype% Object
The value of the [[Prototype]] internal slot of the
%TypedArrayPrototype% object is the standard built-in Object prototype object (19.1.3). The %TypedArrayPrototype% object is an ordinary object.
It does not have a [[ViewedArrayBuffer]] or or any other of the internal slots that are specific to TypedArray
instance objects.
%TypedArray%.prototype.buffer is an accessor property whose set accessor function is undefined. Its get accessor function performs the following steps:
Let O be the this value.
If Type(O) is not Object, throw a TypeError
exception.
If O does not have a [[ViewedArrayBuffer]] internal
slot throw a TypeError exception.
Let buffer be the value of O’s [[ViewedArrayBuffer]] internal slot.
If buffer is undefined, then throw a TypeError exception.
%TypedArray%.prototype.byteLength is an accessor property whose set accessor function is undefined. Its get accessor function performs the following steps:
Let O be the this value.
If Type(O) is not Object, throw a TypeError
exception.
If O does not have a [[ViewedArrayBuffer]] internal
slot throw a TypeError exception.
Let buffer be the value of O’s [[ViewedArrayBuffer]] internal slot.
If buffer is undefined, then throw a TypeError exception.
Let size be the value of O’s [[ByteLength]] internal slot.
%TypedArray%.prototype.byteOffset is an accessor property whose set accessor function is undefined. Its get accessor function performs the following steps:
Let O be the this value.
If Type(O) is not Object, throw a TypeError
exception.
If O does not have a [[ViewedArrayBuffer]] internal
slot throw a TypeError exception.
Let buffer be the value of O’s [[ViewedArrayBuffer]] internal slot.
If buffer is undefined, then throw a TypeError exception.
Let offset be the value of O’s [[ByteOffset]] internal slot.
The initial value of %TypedArray%.prototype.constructor is the %TypedArray% intrinsic object.
22.2.3.5 %TypedArray%.prototype.copyWithin (target, start, end = this.length )
%TypedArray%.prototype.copyWithin is a distinct function that implements the same algorithm as Array.prototype.copyWithin as defined in 22.1.3.3 except that the this object’s [[ArrayLength]] internal slot is accessed in place of performing a [[Get]] of
"length". The implementation of the algorithm may be optimized with the knowledge that the this value
is an object that has a fixed length and whose integer indexed properties are not sparse. However, such optimization must
not introduce any observable changes in the specified behaviour of the algorithm.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
The length property of the copyWithin method is 2.
The initial value of the %TypedArray%.prototype.entries data property is the same built-in function object
as the Array.prototype.entries method defined in 22.1.3.4.
%TypedArray%.prototype.every is a distinct function that implements the same algorithm as Array.prototype.every as defined in 22.1.3.5 except that the this object’s [[ArrayLength]] internal slot is accessed in place of performing a [[Get]] of
"length". The implementation of the algorithm may be optimized with the knowledge that the this value
is an object that has a fixed length and whose integer indexed properties are not sparse. However, such optimization must
not introduce any observable changes in the specified behaviour of the algorithm.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
The length property of the every method is 1.
22.2.3.8 %TypedArray%.prototype.fill (value, start = 0, end = this.length )
%TypedArray%.prototype.fill is a distinct function that implements the same algorithm as Array.prototype.fill as defined in 22.1.3.6 except that the this object’s [[ArrayLength]] internal slot is accessed in place of performing a [[Get]] of
"length". The implementation of the algorithm may be optimized with the knowledge that the this value
is an object that has a fixed length and whose integer indexed properties are not sparse. However, such optimization must
not introduce any observable changes in the specified behaviour of the algorithm.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
Let selected be the result of calling the [[Call]] internal method of callbackfn with T as
thisArgument and a List containing kValue,
k, and O as argumentsList.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
%TypedArray%.prototype.find is a distinct function that implements the same algorithm as Array.prototype.find as defined in 22.1.3.8 except that the this object’s [[ArrayLength]] internal slot is accessed in place of performing a [[Get]] of
"length". The implementation of the algorithm may be optimized with the knowledge that the this value
is an object that has a fixed length and whose integer indexed properties are not sparse. However, such optimization must
not introduce any observable changes in the specified behaviour of the algorithm.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
%TypedArray%.prototype.findIndex is a distinct function that implements the same algorithm as Array.prototype.findIndex as defined in 22.1.3.9 except that the this object’s [[ArrayLength]] internal slot is accessed in place of performing a [[Get]] of
"length". The implementation of the algorithm may be optimized with the knowledge that the this value
is an object that has a fixed length and whose integer indexed properties are not sparse. However, such optimization must
not introduce any observable changes in the specified behaviour of the algorithm.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
%TypedArray%.prototype.forEach is a distinct function that implements the same algorithm as Array.prototype.forEach as defined in 22.1.3.10 except that the this object’s [[ArrayLength]] internal slot is accessed in place of performing a [[Get]] of
"length". The implementation of the algorithm may be optimized with the knowledge that the this value
is an object that has a fixed length and whose integer indexed properties are not sparse. However, such optimization must
not introduce any observable changes in the specified behaviour of the algorithm.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
%TypedArray%.prototype.indexOf is a distinct function that implements the same algorithm as Array.prototype.indexOf as defined in 22.1.3.11 except that the this object’s [[ArrayLength]] internal slot is accessed in place of performing a [[Get]] of
"length". The implementation of the algorithm may be optimized with the knowledge that the this value
is an object that has a fixed length and whose integer indexed properties are not sparse. However, such optimization must
not introduce any observable changes in the specified behaviour of the algorithm.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
%TypedArray%.prototype.join is a distinct function that implements the same algorithm as Array.prototype.join as defined in 22.1.3.12 except that the this object’s [[ArrayLength]] internal slot is accessed in place of performing a [[Get]] of
"length". The implementation of the algorithm may be optimized with the knowledge that the this value
is an object that has a fixed length and whose integer indexed properties are not sparse. However, such optimization must
not introduce any observable changes in the specified behaviour of the algorithm.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
The initial value of the %TypedArray%.prototype.keys data property is the same built-in function object as
the Array.prototype.keys method defined in 22.1.3.13.
%TypedArray%.prototype.lastIndexOf is a distinct function that implements the same algorithm as Array.prototype.lastIndexOf as defined in 22.1.3.14 except that the this object’s [[ArrayLength]] internal slot is accessed in place of performing a [[Get]] of
"length". The implementation of the algorithm may be optimized with the knowledge that the this value
is an object that has a fixed length and whose integer indexed properties are not sparse. However, such optimization must
not introduce any observable changes in the specified behaviour of the algorithm.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
The length property of the lastIndexOf method is 1.
%TypedArray%.prototype.length is an accessor property whose set accessor function is undefined. Its get accessor function performs the following steps:
Let O be the this value.
If Type(O) is not Object, throw a TypeError
exception.
If O does not have a [[TypedArrayName]] internal
slot, then throw a TypeError exception.
Assert: O has [[ViewedArrayBuffer]] and [[ArrayLength]] internal
slots.
Let buffer be the value of O’s [[ViewedArrayBuffer]] internal slot.
If buffer is undefined, then throw a TypeError exception.
Let length be the value of O’s [[ArrayLength]] internal slot.
Return length.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
Let mappedValue be the result of calling the [[Call]] internal method of callbackfn with T
as thisArgument and a List containing
kValue, k, and O as argumentsList.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
%TypedArray%.prototype.reduce is a distinct function that implements the same algorithm as Array.prototype.reduce as defined in 22.1.3.18 except that the this object’s [[ArrayLength]] internal slot is accessed in place of performing a [[Get]] of
"length". The implementation of the algorithm may be optimized with the knowledge that the this value
is an object that has a fixed length and whose integer indexed properties are not sparse. However, such optimization must
not introduce any observable changes in the specified behaviour of the algorithm.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
%TypedArray%.prototype.reduceRight is a distinct function that implements the same algorithm as Array.prototype.reduceRight as defined in 22.1.3.19 except that the this object’s [[ArrayLength]] internal slot is accessed in place of performing a [[Get]] of
"length". The implementation of the algorithm may be optimized with the knowledge that the this value
is an object that has a fixed length and whose integer indexed properties are not sparse. However, such optimization must
not introduce any observable changes in the specified behaviour of the algorithm.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
The length property of the reduceRight method is 1.
%TypedArray%.prototype.reverse is a distinct function that implements the same algorithm as Array.prototype.reverse as defined in 22.1.3.20 except that the this object’s [[ArrayLength]] internal slot is accessed in place of performing a [[Get]] of
"length". The implementation of the algorithm may be optimized with the knowledge that the this value
is an object that has a fixed length and whose integer indexed properties are not sparse. However, such optimization must
not introduce any observable changes in the specified behaviour of the algorithm.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
Set multiple values in this TypedArray, reading the values from the object array. The optional
offset value indicates the first element index in this TypedArray where values are written. If omitted, it
is assumed to be 0.
Assert: array does not have a [[TypedArrayName]] internal slot. If it does, the definition in 22.2.3.23 applies.
Let target be the this value.
If Type(target) is not Object, throw a TypeError
exception.
If target does not have a [[TypedArrayName]] internal slot, then throw a TypeError
exception.
Set multiple values in this TypedArray, reading the values from the typedArray argument object. The
optional offset value indicates the first element index in this TypedArray where values are written. If
omitted, it is assumed to be 0.
If targetOffset < 0, then throw a RangeError exception.
Let targetName be the string value target’s [[TypedArrayName]] internal slot.
Let targetType be the string value of the Element Type value in Table 43 for
targetName.
Let targetElementSize be the Number value of the Element Size value specified in Table
43 for targetName.
Let targetByteOffset be the value of target’s [[ByteOffset]] internal slot.
Let srcName be the string value typedArray’s [[TypedArrayName]] internal slot.
Let srcType be the string value of the Element Type value in Table 43 for
srcName .
Let srcElementSize be the Number value of the Element Size value specified in Table
43 for srcName.
Let srcLength be the value of typedArray’s [[ArrayLength]] internal slot.
Let srcByteOffset be the value of typedArray’s [[ByteOffset]] internal slot.
If srcLength + targetOffset > targetLength, then throw a RangeError exception.
If SameValue(srcBuffer, targetBuffer) is true, then
Let srcBuffer be the result of calling CloneArrayBuffer(srcBuffer, srcByteOffset).
Let srcByteIndex be 0.
Else, let srcByteIndex be srcByteOffset.
Let targetByteIndex be targetOffset × targetElementSize + targetByteOffset.
Let limit be targetByteIndex + targetElementSize × min(srcLength,
targetLength – targetOffset).
Repeat, while targetByteIndex < limit
Let value be the result of GetValueFromBuffer (srcBuffer,
srcByteIndex, srcType).
Let status be the result of SetValueInBuffer (targetBuffer,
targetByteIndex, targetType, value).
Set srcByteIndex to srcByteIndex + srcElementSize.
Set targetByteIndex to targetByteIndex + targetElementSize.
Return undefined.
22.2.3.24 %TypedArray%.prototype.slice ( start, end )
The interpretation and use of the arguments of %TypedArray%.prototype.slice are the same as for Array.prototype.slice as defined in 22.1.3.22. The following steps are taken:
Let O be the this value.
If Type(O) is not Object, throw a TypeError
exception.
If O does not have a [[TypedArrayName]] internal
slot, then throw a TypeError exception.
Let len be the value of O’s [[ArrayLength]] internal slot.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
%TypedArray%.prototype.some is a distinct function that implements the same algorithm as Array.prototype.some as defined in 22.1.3.23 except that the this object’s [[ArrayLength]] internal slot is accessed in place of performing a [[Get]] of
"length". The implementation of the algorithm may be optimized with the knowledge that the this value
is an object that has a fixed length and whose integer indexed properties are not sparse. However, such optimization must
not introduce any observable changes in the specified behaviour of the algorithm.
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when this function is called.
%TypedArray%.prototype.sort is a distinct function that, except as described below, implements the same
requirements as those of Array.prototype.sort as defined in 22.1.3.24. The implementation of the %TypedArray%.prototype.sort
specification may be optimized with the knowledge that the this value is an object that has a fixed length and
whose integer indexed properties are not sparse. The only internal methods of the this object that the algorithm
may call are [[Get]] and [[Set]].
This function is not generic. If the this value is not a object with a [[TypedArrayName]] internal slot, a TypeError exception
is immediately thrown when it is called.
Upon entry, the following steps are performed to initialise evaluation of the sort function. These steps
are used instead of the entry steps in 22.1.3.24:
Let obj be the this value as the argument.
If obj does not have a [[TypedArrayName]] internal
slot, then throw a TypeError exception.
Let len be the value of obj’s [[ArrayLength]] internal slot.
The following version of SortCompare is used by
%TypedArray%.prototype.sort. It performs a numeric comparison rather than the string comparsion used in 22.1.3.24.
The Typed Array SortCompare abstract operation is called with two arguments j
and k, the following steps are taken:
If IsCallable(comparefn) is false, throw a TypeError
exception.
Return the result of calling the [[Call]] internal method of comparefn passing undefined as
thisArgument and with a List containing the values
of x and y as the argumentsList.
If x < y, return −1.
If x > y, return 1.
Return +0.
NOTE 1 Because NaN always compares greater than any other value, NaN property
values always sort to the end of the result.
22.2.3.27 %TypedArray%.prototype.subarray(begin = 0, end = this.length )
Returns a new TypedArray object whose element types is the same as this TypedArray and whose ArrayBuffer
is the same as the ArrayBuffer of this TypedArray, referencing the elements at begin, inclusive, up to
end, exclusive. If either begin or end is negative, it refers to an index from the end of
the array, as opposed to from the beginning.
Let O be the this value.
If Type(O) is not Object, throw a TypeError
exception.
If O does not have a [[TypedArrayName]] internal
slot, then throw a TypeError exception.
The initial value of the %TypedArray%.prototype.toLocaleString data property is the same built-in function object as
the Array.prototype.toLocaleString method defined in 22.1.3.26.
The initial value of the %TypedArray%.prototype.toString data property is the same built-in function object as the Array.prototype.toString method defined in 22.1.3.27.
The initial value of the %TypedArray%.prototype.values data property is the same built-in function object
as the Array.prototype.values method defined in 22.1.3.29.
The initial value of the @@iterator property is the same function object as the initial value of the
%TypedArray%.prototype.values property.
22.2.3.32 get %TypedArray%.prototype [ @@toStringTag ]
%TypedArray%.prototype[@@toStringTag] is an accessor property whose set accessor function is undefined. Its get accessor function performs the following steps:
Let O be the this.value.
If Type(O) is not Object, throw a TypeError
exception.
If O does not have a [[TypedArrayName]] internal
slot throw a TypeError exception.
Let name be the value of O’s [[TypedArrayName]] internal slot.
Each of these TypedArray constructor objects has the structure described below, differing only in the name used
as the constructor name instead of TypedArray, in Table 43.
When a TypedArray constructor is called as a function rather than as a constructor, it initialises a new
TypedArray object. The this value passed in the call must be an Object with a [[TypedArrayName]] internal slot and a [[ViewedArrayBuffer]] internal slot whose value is undefined. The constructor function initialises the this value using the argument values.
The TypedArray constructors are designed to be subclassable. They may be used as the value of an
extends clause of a class declaration. Subclass constructors that intended to inherit the specified
TypedArray behaviour must include a super call to the TypedArray constructor to initialise
subclass instances.
A TypedArray constructor with a list of arguments argumentsList performs the following steps:
Let O be the this value.
If Type(O) is not Object, then throw a TypeError
exception.
If O does not have a [[TypedArrayName]] internal
slot, then throw a TypeError exception.
If the value of O’s [[TypedArrayName]] internal slot is not undefined, then throw a
TypeError exception.
Set O’s [[TypedArrayName]] internal slot
to the String value from the constructor name column in the row of Table 43 corresponding to
this constructor.
Let F be the TypedArray function object that was called.
The value of the [[Prototype]] internal slot of a
TypedArray prototype object is the standard built-in %TypedArrayPrototype% object (22.2.3). A TypedArray prototype object is an
ordinary object. It does not have a [[ViewedArrayBuffer]] or or any other of the internal slots that are specific to
TypedArray instance objects.
TypedArray instances are Integer Indexed exotic objects. Each TypedArray instances inherits properties from
the corresponding TypedArray prototype object. Each TypedArray instances have the following internal slots:
[[TypedArrayName]], [[ViewedArrayBuffer]], [[ByteLength]], [[ByteOffset]], and [[ArrayLength]].
Map objects are collections of key/value pairs where both the keys and values may be arbitrary ECMAScript language values. A distinct key value may only occur in one key/value
pair within the Map’s collection. Distinct key values as discriminated using the a comparision algorithm that is
selected when the Map is created.
A Map object can iterate its elements in insertion order. Map object must be implemented using either hash tables or
other mechanisms that, on average, provide access times that are sublinear on the number of elements in the collection. The
data structures used in this Map objects specification is only intended to describe the required observable semantics of Map
objects. It is not intended to be a viable implementation model.
The Map constructor is the %Map% intrinsic object and the initial value of the Map property of the global
object. When Map is called as a function rather than as a constructor, it initialises its this value
with the internal state necessary to support the Map.prototype built-in methods.
The Map constructor is designed to be subclassable. It may be used as the value in an extends
clause of a class definition. Subclass constructors that intend to inherit the specified Map behaviour must
include a super call to Map.
Let status be the result of calling the [[Call]] internal method of adder with map as
thisArgument and a List whose elements are k
and v as argumentsList.
NOTE If the parameter iterable is present, it is expected to be an object that
implements an @@iterator method that returns an iterator object that
produces a two element array-like object whose first element is a value that will be used as an Map key and whose second
element is the value to associate with that key.
The value of the [[Prototype]] internal slot of the Map
prototype object is the standard built-in Object prototype object (19.1.3). The Map prototype object is an ordinary object. It does
not have a [[MapData]] internal slot.
If Type(M) is not Object, then throw a TypeError
exception.
If M does not have a [[MapData]] internal slot
throw a TypeError exception.
If M’s [[MapData]] internal slot is
undefined, then throw a TypeError exception.
Let entries be the List that is the value of
M’s [[MapData]] internal slot.
Repeat for each Record {[[key]], [[value]]} p that is an element of entries,
Set p.[[key]] to empty.
Set p.[[value]] to empty.
Return undefined.
NOTE The existing [[MapData]] List is
preserved because there may be existing MapIterator objects that are suspended
midway through iterating over that List.
NOTE The value empty is used as a specification device to indicate that an entry has
been deleted. Actual implementations may take other actions such as physically removing the entry from internal data
structures.
callbackfn should be a function that accepts three arguments. forEach calls
callbackfn once for each key/value pair present in the map object, in key insertion order.
callbackfn is called only for keys of the map which actually exist; it is not called for keys that have been
deleted from the map.
If a thisArg parameter is provided, it will be used as the this value for each invocation of
callbackfn. If it is not provided, undefined is used instead.
callbackfn is called with three arguments: the value of the item, the key of the item, and the Map object
being traversed.
forEach does not directly mutate the object on which it is called but the object may be mutated by the
calls to callbackfn.
When the forEach method is called with one or two arguments, the following steps are taken:
Let M be the this value.
If Type(M) is not Object, then throw a TypeError
exception.
If M does not have a [[MapData]] internal slot
throw a TypeError exception.
If M’s [[MapData]] internal slot is
undefined, then throw a TypeError exception.
If IsCallable(callbackfn) is false, throw a TypeError
exception.
If thisArg was supplied, let T be thisArg; else let T be undefined.
Let entries be the List that is the value of
M’s [[MapData]] internal slot.
Repeat for each Record {[[key]], [[value]]} e that is an element of entries, in original key insertion
order
If e.[[key]] is not empty, then
Let funcResult be the result of calling the [[Call]] internal method of callbackfn with
T as thisArgument and a List containing
e.[[value]], e.[[key]], and M as argumentsList.
A Map Iterator is an object, that represents a specific iteration over some specific Map instance object. There is not
a named constructor for Map Iterator objects. Instead, map iterator objects are created by calling certain methods of Map
instance objects.
Several methods of Map objects return Iterator objects. The abstract operation CreateMapIterator with arguments
map and kind is used to create such iterator objects. It performs the following steps:
If Type(map) is not Object, throw a TypeError
exception.
If map does not have a [[MapData]] internal
slot throw a TypeError exception.
Let iterator be the result of ObjectCreate(%MapIteratorPrototype%, ([[Map]], [[MapNextIndex]], [[MapIterationKind]])).
All Map Iterator Objects inherit properties from the %MapIteratorPrototype% intrinsic object. The
%MapIteratorPrototype% intrinsic object is an ordinary object and its [[Prototype]] internal slot is the %ObjectPrototype% intrinsic object. In
addition, %MapIteratorPrototype% has the following properties:
Assert: m has a [[MapData]] internal slot and m has been initialised so the
value of [[MapData]] is not undefined.
Let entries be the List that is the value of the
[[MapData]] internal slot of m.
Repeat while index is less than the total number of elements of entries. The number of elements must
be redetermined each time this method is evaluated.
Let e be the Record {[[key]], [[value]]} that is the value of entries[index].
Set index to index+1;
Set the [[MapNextIndex]] internal slot of
O to index.
If e.[[key]] is not empty, then
If itemKind is "key" then, let result be
e.[[key]].
Else if itemKind is "value" then, let
result be e.[[value]].
Map Iterator instances are ordinary objects that inherit properties from the %MapIteratorPrototype% intrinsic object.
Map Iterator instances are initially created with the internal slots described in Table 44.
Table 44 — Internal Slots of Map Iterator Instances
Internal Slot
Description
[[Map]]
The Map object that is being iterated.
[[MapNextIndex]]
The integer index of the next Map data element to be examined by this iterator.
[[MapIterationKind]]
A string value that identifies what is to be returned for each element of the iteration. The possible values are: "key", "value", "key+value".
Set objects are collections of ECMAScript language values. A distinct value
may only occur once as an element of a Set’s collection. Distinct values are discriminated using a comparision
algorithm that is selected when the Set is created.
A Set object can iterate its elements in insertion order. Set objects must be implemented using either hash tables or
other mechanisms that, on average, provide access times that are sublinear on the number of elements in the collection. The
data structures used in this Set objects specification is only intended to describe the required observable semantics of Set
objects. It is not intended to be a viable implementation model.
The Set constructor is the %Set% intrinsic object and the initial value of the Set property of the global
object. When Set is called as a function rather than as a constructor, it initialises its this value
with the internal state necessary to support the Set.prototype built-in methods.
The Set constructor is designed to be subclassable. It may be used as the value in an extends
clause of a class definition. Subclass constructors that intend to inherit the specified Set behaviour must
include a super call to Set.
Let status be the result of calling the [[Call]] internal method of adder with set as
thisArgument and a List whose sole element is
nextValue as argumentsList.
When Set is called as part of a new expression it is a constructor: it initialises a newly
created object. Set called as part of a new expression with argument list argumentsList performs the following
steps:
Let F be the Set function object on which the new operator was applied.
Let argumentsList be the argumentsList argument of the [[Construct]] internal method that was invoked
by the new operator.
The value of the [[Prototype]] internal slot of the Set
prototype object is the standard built-in Object prototype object (19.1.3). The Set prototype object is an ordinary object. It does
not have a [[SetData]] internal slot.
If Type(S) is not Object, then throw a TypeError
exception.
If S does not have a [[SetData]] internal slot
throw a TypeError exception.
If S’s [[SetData]] internal slot is
undefined, then throw a TypeError exception.
Let entries be the List that is the value of
S’s [[SetData]] internal slot.
Repeat for each e that is an element of entries, in original insertion order
If e is not empty and SameValueZero(e, value) is true, then
Replace the element of entries whose value is e with an element whose value is empty.
Return true.
Return false.
NOTE The value empty is used as a specification device to indicate that an entry has
been deleted. Actual implementations may take other actions such as physically removing the entry from internal data
structures.
callbackfn should be a function that accepts three arguments. forEach calls
callbackfn once for each value present in the set object, in value insertion order. callbackfn is
called only for values of the Set which actually exist; it is not called for keys that have been deleted from the
set.
If a thisArg parameter is provided, it will be used as the this value for each invocation of
callbackfn. If it is not provided, undefined is used instead.
NOTE 1 If callbackfn is an Arrow Function, this was lexically bound when
the function was created so thisArg will have no effect.
callbackfn is called with three arguments: the first two arguments are a value contained in the Set. The
same value of passed for both arguments. The Set object being traversed is passed as the third argument.
NOTE 2 The callbackfn is called with three arguments to be consistent with the
call back functions used by forEach methods for Map and Array. For Sets, each item value is considered to
be both the key and the value.
forEach does not directly mutate the object on which it is called but the object may be mutated by the
calls to callbackfn.
NOTE 3 Each value is normally visited only once. However, a value will be revisited if it is
deleted after it has been visited and then re-added before the to forEach call completes. Values that are
deleted after the call to forEach begins and before being visited are not visited unless the value is added
again before the to forEach call completes. New values added, after the call to forEach begins
are visited.
When the forEach method is called with one or two arguments, the following steps are taken:
Let S be the this value.
If Type(S) is not Object, then throw a TypeError
exception.
If S does not have a [[SetData]] internal slot
throw a TypeError exception.
If S’s [[SetData]] internal slot is
undefined, then throw a TypeError exception.
If IsCallable(callbackfn) is false, throw a TypeError
exception.
If thisArg was supplied, let T be thisArg; else let T be undefined.
Let entries be the List that is the value of
S’s [[SetData]] internal slot.
Repeat for each e that is an element of entries, in original insertion order
If e is not empty, then
Let funcResult be the result of calling the [[Call]] internal method of callbackfn with
T as thisArgument and a List containing
e, e, and S as argumentsList.
Set instances are ordinary objects that inherit properties from the Set prototype. After initialisation by the Set
constructor, Set instances also have a [[SetData]] internal
slot.
A Set Iterator is an ordinary object, with the structure defined below, that represents a specific iteration over some
specific Set instance object. There is not a named constructor for Set Iterator objects. Instead, set iterator objects
are created by calling certain methods of Set instance objects.
Several methods of Set objects return Iterator objects. The abstract operation CreateSetIterator with arguments
set and kind is used to create such iterator objects. It performs the following steps:
If Type(set) is not Object, throw a TypeError
exception.
If set does not have a [[SetData]] internal
slot throw a TypeError exception.
If set’s [[SetData]] internal slot is
undefined, then throw a TypeError exception.
Let iterator be the result of ObjectCreate(%SetIteratorPrototype%, ([[IteratedSet]], [[SetNextIndex]], [[SetIterationKind]])).
Set iterator’s [[IteratedSet]] internal
slot to set.
All Set Iterator Objects inherit properties from the %SetIteratorPrototype% intrinsic object. The
%SetIteratorPrototype% intrinsic object is an ordinary object and its [[Prototype]] internal slot is the %ObjectPrototype% intrinsic object. In
addition, %SetIteratorPrototype% has the following properties:
Assert: s has a [[SetData]] internal slot and s has been initialised so the
value of [[SetData]] is not undefined.
Let entries be the List that is the value of the
[[SetData]] internal slot of s.
Repeat while index is less than the total number of elements of entries. The number of elements must
be redetermined each time this method is evaluated.
Let e be entries[index].
Set index to index+1;
Set the [[SetNextIndex]] internal slot of
O to index.
If e is not empty, then
If itemKind is "key+value" then,
Let result be the result of performing ArrayCreate(2).
Assert: result is a new, well-formed Array object so
the following operations will never fail.
Set Iterator instances are ordinary objects that inherit properties from the %SetIteratorPrototype% intrinsic object.
Set Iterator instances are initially created with the internal slots specified Table 45.
Table 45 — Internal Slots of Set Iterator Instances
Internal Slot
Description
[[IteratedSet]]
The Set object that is being iterated.
[[SetNextIndex]]
The integer index of the next Set data element to be examined by this iterator
[[SetIterationKind]]
A string value that identifies what is to be returned for each element of the iteration. The possible values are: "key", "value", "key+value". "key" and "value" have the same meaning.
WeakMap objects are collections of key/value pairs where the keys are objects and values may be arbitrary ECMAScript language values. A WeakMap may be queried to see if it contains an
key/value pair with a specific key, but no mechanisms is provided for enumerating the objects it holds as keys. If an object
that is being used as the key of a WeakMap key/value pair is only reachable by following a chain of references that start
within that WeakMap, then that key/value pair is inaccessible and is automatically removed from the WeakMap. WeakMap
implementations must detect and remove such key/value pairs and any associated resources.
An implementation may impose an arbitrarily determined latency between the time a key/value pair of a WeakMap becomes
inaccessible and the time when the key/value pair is removed from the WeakMap. If this latency was observable to ECMAScript
program, it would be a source of indeterminacy that could impact program execution. For that reason, an ECMAScript
implementation must not provide any means to observe a key of a WeakMap that does not require the observer to present the
observed key.
WeakMap objects must be implemented using either hash tables or other mechanisms that, on average, provide access times
that are sublinear on the number of key/value pairs in the collection. The data structure used in this WeakMap objects
specification are only intended to describe the required observable semantics of WeakMap objects. It is not intended to be
a viable implementation model.
NOTE WeakMap and WeakSets are intended to provide mechanisms for dynamically associating state
with an object in a manner that does not “leak” memory resources if, in the absence of the WeakMap or WeakSet,
the object otherwise became inaccessible and subject to resource reclamation by the implementation’s garbage
collection mechanisms. Achieving this characteristic requires coordination between the WeakMap or WeakSet implementation
and the garbage collector. The following references describe mechanism that may be useful to implementations of WeakMap
and WeakSets:
Barry Hayes. 1997. Ephemerons: a new finalization mechanism. In Proceedings of the 12th ACM SIGPLAN conference on
Object-oriented programming, systems, languages, and applications (OOPSLA '97), A. Michael Berman (Ed.). ACM, New
York, NY, USA, 176-183. http://doi.acm.org/10.1145/263698.263733.
The WeakMap constructor is the %WeakMap% intrinsic object and the initial value of the WeakMap property of
the global object. When WeakMap is called as a function rather than as a constructor, it initialises its
this value with the internal state necessary to support the WeakMap.prototype built-in methods.
The WeakMap constructor is designed to be subclassable. It may be used as the value in an
extends clause of a class definition. Subclass constructors that intend to inherit the specified
WeakMap behaviour must include a super call to WeakMap.
Let status be the result of calling the [[Call]] internal method of adder with map as
thisArgument and a List whose elements are k
and v as argumentsList.
NOTE If the parameter iterable is present, it is expected to be an object that
implements an @@iterator method that returns an iterator object that
produces a two element array-like object whose first element is a value that will be used as a WeakMap key and whose
second element is the value to associate with that key.
The value of the [[Prototype]] internal slot of the
WeakMap prototype object is the standard built-in Object prototype object (19.1.3). The WeakMap prototype object is an ordinary object. It
does not have a [[WeakMapData]] internal slot.
Repeat for each Record {[[key]], [[value]]} p that is an element of entries,
If p.[[key]] and key are the same object, then
Set p.[[key]] to empty.
Set p.[[value]] to empty.
Return true.
Return false.
NOTE The value empty is used as a specification device to indicate that an entry has
been deleted. Actual implementations may take other actions such as physically removing the entry from internal data
structures.
WeakMap instances are ordinary objects that inherit properties from the WeakMap prototype. WeakMap instances also have a
[[WeakMapData]] internal slot.
WeakSet objects are collections of objects. A distinct object may only occur once as an element of a WeakSet’s
collection. A WeakSet may be queried to see if it contains a specific object, but no mechanisms is provided for enumerating
the objects it holds. If an object that is contain by a WeakSet is only reachable by following a chain of references that
start within that WeakSet, then that object is inaccessible and is automatically removed from the WeakSet. WeakSet
implementations must detect and remove such objects and any associated resources.
An implementation may impose an arbitrarily determined latency between the time an object contained in a WeakSet becomes
inaccessible and the time when the object is removed from the WeakSet. If this latency was observable to ECMAScript program,
it would be a source of indeterminacy that could impact program execution. For that reason, an ECMAScript
implementation must not provide any means to determine if a WeakSet contains a particular object that does not require the
observer to present the observed object.
WeakSet objects must be implemented using either hash tables or other mechanisms that, on average, provide access times
that are sublinear on the number of elements in the collection. The data structure used in this WeakSet objects
specification is only intended to describe the required observable semantics of WeakSet objects. It is not intended to be a
viable implementation model.
The WeakSet constructor is the %WeakSet% intrinsic object and the initial value of the WeakSet property of
the global object. When WeakSet is called as a function rather than as a constructor, it initialises its
this value with the internal state necessary to support the WeakSet.prototype built-in methods.
The WeakSet constructor is designed to be subclassable. It may be used as the value in an
extends clause of a class definition. Subclass constructors that intend to inherit the specified
WeakSet behaviour must include a super call to WeakSet.
Let status be the result of calling the [[Call]] internal method of adder with set as
thisArgument and a List whose sole element is
nextValue as argumentsList.
The value of the [[Prototype]] internal slot of the
WeakSet prototype object is the standard built-in Object prototype object (19.1.3). The WeakSet prototype object is an ordinary object. It
does not have a [[WeakSetData]] internal slot.
Let entries be the List that is the value of
S’s [[WeakSetData]] internal slot.
Repeat for each e that is an element of entries, in original insertion order
If e is not empty and SameValue(e, value) is true, then
Replace the element of entries whose value is e with an element whose value is empty.
Return true.
Return false.
NOTE The value empty is used as a specification device to indicate that an entry has
been deleted. Actual implementations may take other actions such as physically removing the entry from internal data
structures.
WeakSet instances are ordinary objects that inherit properties from the WeakSet prototype. After initialisation by the
WeakSet constructor, WeakSet instances also have a [[WeakSetData]] internal slot.
The abstract operation AllocateArrayBuffer with argument constructor is used to create an uninitialised
ArrayBuffer object. It performs the following steps:
Let obj be the result of calling OrdinaryCreateFromConstructor(constructor,
"%ArrayBufferPrototype%", ( [[ArrayBufferData]], [[ArrayBufferByteLength]]) ).
The abstract operation SetArrayBufferData with arguments arrayBuffer
and bytes is used to initialise the storage block encapsulated by an ArrayBuffer object. It performs the
following steps:
The abstract operation CloneArrayBuffer takes two parameters, an
ArrayBuffer srcBuffer, an integer srcByteOffset. It creates a new ArrayBufer whose data is a copy of
srcBuffer’s data starting at srcByteOffset.This operation performs the follow steps:
The abstract operation GetValueFromBuffer takes four parameters, an
ArrayBuffer arrayBuffer, an integer byteIndex, a String type, and optionally a Boolean
isLittleEndian. If isLittleEndian is not present, its default value is undefined. This operation performs the follow steps:
Assert: There are sufficient bytes in arrayBuffer starting at
byteIndex to represent a value of valueType.
Let block be arrayBuffer’s [[ArrayBufferData]] internal slot.
If block is undefined or null, then throw a TypeError exception.
Let elementSize be the Number value of the Element Size value specified in Table 43
for valueType.
Let rawValue be a List of elementSize containing, in
order, the elementSize bytes starting at byteIndex of block.
If isLittleEndian is undefined, set isLittleEndian to either true or false. The
choice is implementation dependent and should be the alternative that is most efficient for the implementation. An
implementation must use the same value each time this step is executed and the same value must be used for the
corresponding step in the SetValueInBuffer abstract operation.
If isLittleEndian is false, reverse the order of the elements of rawValue.
If type is “Float32” , then
Let value be the byte elements of rawValue concatenated and interpreted as a little-endian bit
string encoding of an IEEE 754-208 binary32 value.
If value is an IEEE 754-208 binary32 NaN value, return the NaN Number value.
Return the Number value that corresponds to value.
If type is “Float64” , then
Let value be the byte elements of rawValue concatenated and interpreted as a little-endian bit
string encoding of an IEEE 754-208 binary64 value.
If value is an IEEE 754-208 binary64 NaN value, return the NaN Number value.
Return the Number value that is encoded by corresponds to value.
If the first character of type is "U", then
Let intValue be the byte elements of rawValue concatenated and interpreted as a bit string
encoding of an unsigned little-endian binary number.
Else
Let intValue be the byte elements of rawValue concatenated and interpreted as a bit string
encoding of a binary little-endian 2’s complement number of bit length elementSize × 8.
Return the Number value that corresponds to intValue.
The abstract operation SetValueInBuffer takes five parameters, an
ArrayBuffer arrayBuffer, an integer byteIndex, a String type, a Number value, and
optionally a Boolean isLittleEndian. If isLittleEndian is not present, its default value is undefined. This operation performs the follow steps:
Assert: There are sufficient bytes in arrayBuffer starting at
byteIndex to represent a value of valueType.
Let block be arrayBuffer’s [[ArrayBufferData]] internal slot.
If block is undefined or null, then throw a TypeError exception.
Let elementSize be the Number value of the Element Size value specified in Table 43
for the row containing the value of type as its Element Type entry.
If isLittleEndian is undefined, set isLittleEndian to either true or false. The
choice is implementation dependent and should be the alternative that is most efficient for the implementation. An
implementation must use the same value each time this step is executed and the same value must be used for the
corresponding step in the GetValueFromBuffer abstract operation.
If type is “Float32” , then
Set rawValue to a List containing the 4 bytes that
are the result of converting value to IEEE-868-2005 binary32 format using “Round to nearest, ties
to even” rounding mode. If isLittleEndian is false, the bytes are arranged in big endian
order. Otherwise, the bytes are arranged in little endian order. If value is NaN,
rawValue may be set to any implementation choosen non-signaling NaN encoding.
Else, if type is “Float64” , then
Set rawValue to a List containing the 8 bytes that
are the IEEE-868-2005 binary64 format encoding of value. If isLittleEndian is false, the
bytes are arranged in big endian order. Otherwise, the bytes are arranged in little endian order. If
value is NaN, rawValue may be set to any implementation choosen non-signaling NaN
encoding.
Else,
Let n be the Size Element value in Table 43 for the row containing the value of
type as its Element Type entry.
Let convOp be the abstract operation named in the Conversion Operation column in Table 43 for the row containing the value of type as its Element Type entry.
Let intValue be the result of calling convOp with value as its argument .
If intValue ≥ 0, then
Let rawBytes be a List containing the
n-byte binary encoding of intValue. If isLittleEndian is false, the bytes are
ordered in big endian order. Otherwise, the bytes are ordered in little endian order.
Else,
Let rawBytes be a List containing the
n-byte binary 2’s complement encoding of intValue. If isLittleEndian is
false, the bytes are ordered in big endian order. Otherwise, the bytes are ordered in little endian
order.
Store the individual bytes of rawBytes in order starting at position byteIndex of block.
The ArrayBuffer constructor is the %ArrayBuffer% intrinsic object and the initial value of the ArrayBuffer
property of the global object. When ArrayBuffer is called as a function rather than as a constructor, its
this value must be an Object with an [[ArrayBufferData]] internal slot whose value is undefined. The ArrayBuffer constructor initialises the this value using the argument
values.
The ArrayBuffer constructor is designed to be subclassable. It may be used as the value of an
extends clause of a class declaration. Subclass constructors that intended to inherit the specified
ArrayBuffer behaviour must include a super call to the ArrayBuffer constructor to
initialise subclass instances.
ArrayBuffer called as function with argument length performs the following steps:
Let O be the this value.
If Type(O) is not Object or if O does not have an
[[ArrayBufferData]] internal slot or if the value of
O’s [[ArrayBufferData]] internal slot is
not undefined, then
The value of the name property of this function is "[Symbol.create]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: true }.
24.1.4 Properties of the ArrayBuffer Prototype Object
The value of the [[Prototype]] internal slot of the
ArrayBuffer prototype object is the standard built-in Object prototype object (19.1.3). The ArrayBuffer prototype object is an ordinary object.
It does not have an [[ArrayBufferData]] or [[ArrayBufferByteLength]] internal slot.
ArrayBuffer.prototype.byteLength is an accessor property whose set accessor function is undefined. Its get accessor function performs the following steps:
Let O be the this value.
If Type(O) is not Object, throw a TypeError
exception.
If O does not have an [[ArrayBufferData]] internal
slot throw a TypeError exception.
If the value of O’s [[ArrayBufferData]] internal slot is undefined or null, then
throw a TypeError exception.
Let length be the value of O’s [[ArrayBufferByteLength]] internal slot.
ArrayBuffer instances inherit properties from the ArrayBuffer prototype object. ArrayBuffer instances each have an
[[ArrayBufferData]] internal slot and an
[[ArrayBufferByteLength]] internal slot.
ArrayBuffer instances whose [[ArrayBufferData]] is null are considered to be neutered and all operators to
access or modify data contained in the ArrayBuffer instance will fail.
The abstract operation GetViewValue with arguments view, requestIndex, isLittleEndian,
and type is used by functions on DataView instances is to retrieve values from the view’s buffer. It
performs the following steps:
If Type(view) is not Object, throw a TypeError
exception.
If view does not have a [[DataView]] internal
slot, then throw a TypeError exception.
Let buffer be the value of view’s [[ViewedArrayBuffer]] internal slot.
If buffer is undefined, then throw a TypeError exception.
The abstract operation SetViewValue with arguments view, requestIndex, isLittleEndian,
type, and value is used by functions on DataView instances to store values into the view’s
buffer. It performs the following steps:
If Type(view) is not Object, throw a TypeError
exception.
If view does not have a [[DataView]] internal
slot, then throw a TypeError exception.
Let buffer be the value of view’s [[ViewedArrayBuffer]] internal slot.
If buffer is undefined, then throw a TypeError exception.
The DataView constructor is the %DataView% intrinsic object and the initial value of the DataView property
of the global object. When DataView is called as a function rather than as a constructor, it initialises its
this value with the internal state necessary to support the DataView.prototype internal methods.
The DataView constructor is designed to be subclassable. It may be used as the value of an
extends clause of a class declaration. Subclass constructors that intended to inherit the specified
DataView behaviour must include a super call to the DataView constructor to
initialise subclass instances.
The @@create method of a DataView function object F performs the following steps:
Let F be the this value.
Let obj be the result of calling OrdinaryCreateFromConstructor(F,
"%DataViewPrototype%", ( [[DataView]], [[ViewedArrayBuffer]] , [[ByteLength]], [[ByteOffset]])
).
Set the value of obj’s [[DataView]] internal
slot to true.
Return obj.
The value of the name property of this function is "[Symbol.create]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]:
true }.
NOTE The value of the [[DataView]] internal slot is not used within this specification. The
simple presense of that internal slot is used within the
specification to identify objects created using this @@create method.
24.2.4 Properties of the DataView Prototype Object
The value of the [[Prototype]] internal slot of the
DataView prototype object is the standard built-in Object prototype object (19.1.3). The DataView prototype object is an ordinary object. It
does not have a [[DataView]], [[ViewedArrayBuffer]], [[ByteLength]], or [[ByteOffset]] internal slot.
DataView.prototype.byteLength is an accessor property whose set accessor function is undefined. Its get accessor function performs the following steps:
Let O be the this value.
If Type(O) is not Object, throw a TypeError
exception.
If O does not have a [[ViewedArrayBuffer]] internal
slot throw a TypeError exception.
Let buffer be the value of O’s [[ViewedArrayBuffer]] internal slot.
If buffer is undefined, then throw a TypeError exception.
Let size be the value of O’s [[ByteLength]] internal slot.
DataView.prototype.byteOffset is an accessor property whose set accessor function is undefined. Its get accessor function performs the following steps:
Let O be the this value.
If Type(O) is not Object, throw a TypeError
exception.
If O does not have a [[ViewedArrayBuffer]] internal
slot throw a TypeError exception.
Let buffer be the value of O’s [[ViewedArrayBuffer]] internal slot.
If buffer is undefined, then throw a TypeError exception.
Let offset be the value of O’s [[ByteOffset]] internal slot.
DataView instances are ordinary objects that inherit properties from the DataView prototype object. DataView instances
each have a [[DataView]], [[ViewedArrayBuffer]], [[ByteLength]], and [[ByteOffset]] internal slots.
The JSON object is a single ordinary object that contains two functions, parse and stringify, that
are used to parse and construct JSON texts. The JSON Data Interchange Format is defined in ECMA-404. The JSON interchange
format used in this specification is exactly that described by ECMA-404.
Conforming implementations of JSON.parse and JSON.stringify must support the exact interchange format described in this specification
without any deletions or extensions to the format.
The value of the [[Prototype]] internal slot of the JSON
object is the standard built-in Object prototype object (19.1.3). The value of the [[Extensible]] internal slot of the JSON object is set to true.
The JSON object does not have a [[Construct]] internal method; it is not possible to use the JSON object as a constructor
with the new operator.
The JSON object does not have a [[Call]] internal method; it is not possible to invoke the JSON object as a function.
The parse function parses a JSON text (a JSON-formatted String) and produces an ECMAScript value. The JSON
format is a subset of the syntax for ECMAScript literals, Array Initialisers and Object Initialisers. After parsing, JSON
objects are realized as ECMAScript objects. JSON arrays are realized as ECMAScript Array instances. JSON strings, numbers,
booleans, and null are realized as ECMAScript Strings, Numbers, Booleans, and null.
The optional reviver parameter is a function that takes two parameters, (key and value). It can
filter and transform the results. It is called with each of the key/value pairs produced by the parse, and
its return value is used instead of the original value. If it returns what it received, the structure is not modified. If
it returns undefined then the property is deleted from the result.
Parse JText interpreted as UTF-16 encoded Unicode points as a JSON text as specified in ECMA-404. Throw a
SyntaxError exception if JText is not a valid JSON text as defined in that specification.
Let scriptText be the result of concatenating "(", JText, and ");".
Let completion be the result of parsing and evaluating scriptText as if it was the source text of an
ECMAScript Script. but using the alternative definition of DoubleStringCharacter provided below. The
extended PropertyDefinitionEvaluation semantics defined in B.3.1 must not be used during the evaluation.
Let unfiltered be completion.[[value]].
Assert: unfiltered will be either a primitive value or an object
that is defined by either an ArrayLiteral or an ObjectLiteral.
Return the result of calling the abstract operation Walk, passing root and the
empty String. The abstract operation Walk is described below.
Else
Return unfiltered.
JSON allows Unicode code points U+2028 and U+2029 to directly appear in String literals without
using an escape sequence. This is enabled by using the following alternative definition of DoubleStringCharacter when parsing scriptText in step 5:
DoubleStringCharacter::
SourceCharacterbut not one of"or\orU+0000 through U+001F
\EscapeSequence
The CV of DoubleStringCharacter::SourceCharacterbut not one of"or\or U+0000 through
U+001F is the UTF-16 Encoding (10.1.1) of the code point value of
SourceCharacter.
NOTE The syntax of a valid JSON text is a subset of the ECMAScript PrimaryExpression syntax. Hence a valid JSON text is also a valid PrimaryExpression. Step 3 above verifies that JText conforms to that subset.
When scriptText is parsed and evaluated as a Script the result will be either a
String, Number, Boolean, or Null primitive value or an Object defined as if by an ArrayLiteral
or ObjectLiteral.
24.3.1.1 Runtime
Semantics: Walk Abstract Operation
The abstract operation Walk is a recursive abstract operation that takes two parameters: a holder object and
the String name of a property in that object. Walk uses the value of reviver that was originally
passed to the above parse function.
Let newElement be the result of calling the abstract operation Walk, passing val and ToString(I).
If newElement is undefined, then
Let status be the result of calling the [[Delete]] internal method of val with ToString(I) as the argument.
Else
Let status be the result of calling the [[DefineOwnProperty]] internal method of val
with arguments ToString(I) and PropertyDescriptor{[[Value]]:
newElement, [[Writable]]: true, [[Enumerable]]: true, [[Configurable]]:
true}.
NOTE This algorithm intentionally does not throw an exception if status is false.
Let keys be a List of String values consisting
of the names of all the own properties of val whose [[Enumerable]] attribute is true. The
ordering of the Strings is the same as that used by the Object.keys
standard built-in function.
For each String P in keys do,
Let newElement be the result of calling the abstract operation Walk, passing val and
P.
If newElement is undefined, then
Let status be the result of calling the [[Delete]] internal method of val with
P as the argument.
Else
Let status be the result of calling the [[DefineOwnProperty]] internal method of val
with arguments P and PropertyDescriptor{[[Value]]: newElement, [[Writable]]:
true, [[Enumerable]]: true, [[Configurable]]: true}.
NOTE This algorithm intentionally does not throw an exception if status is false.
Return the result of calling the [[Call]] internal method of reviver passing holder as
thisArgument and with a List containing name and
val as argumentsList.
It is not permitted for a conforming implementation of JSON.parse to extend
the JSON grammars. If an implementation wishes to support a modified or extended JSON interchange format it must do so by
defining a different parse function.
NOTE In the case where there are duplicate name Strings within an object, lexically preceding
values for the same key shall be overwritten.
24.3.2
JSON.stringify ( value [ , replacer [ , space ] ] )
The stringify function returns a String in UTF-16 encoded JSON format representing an ECMAScript value. It
can take three parameters. The value parameter is an ECMAScript value, which is usually an object or array,
although it can also be a String, Boolean, Number or null. The optional replacer parameter is either a
function that alters the way objects and arrays are stringified, or an array of Strings and Numbers that acts as a white
list for selecting the object properties that will be stringified. The optional space parameter is a String or
Number that allows the result to have white space injected into it to improve human readability.
For each value v of a property of replacer that has an array index property name. The
properties are enumerated in the ascending array index order of their names.
Set gap to a String containing space occurrences of code unit 0x0020 (the Unicode space
character). This will be the empty String if space is less than 1.
Return the result of calling the abstract operation Str(the empty String, wrapper).
NOTE 1 JSON structures are allowed to be nested to any depth, but they must be acyclic. If
value is or contains a cyclic structure, then the stringify function must throw a TypeError exception.
This is an example of a value that cannot be stringified:
a = [];
a[0] = a;
my_text = JSON.stringify(a); // This must throw a TypeError.
NOTE 2 Symbolic primitive values are rendered as follows:
The null value is rendered in JSON text as the String null.
The undefined value is not rendered.
The true value is rendered in JSON text as the String true.
The false value is rendered in JSON text as the String false.
NOTE 3 String values are wrapped in double quotes. The characters " and
\ are escaped with \ prefixes. Control characters are replaced with escape sequences
\uHHHH, or with the shorter forms, \b (backspace), \f (formfeed), \n
(newline), \r (carriage return), \t (tab).
NOTE 4 Finite numbers are stringified as if by calling ToString(number). NaN and Infinity regardless of
sign are represented as the String null.
NOTE 5 Values that do not have a JSON representation (such as undefined and functions)
do not produce a String. Instead they produce the undefined value. In arrays these values are represented as the
String null. In objects an unrepresentable value causes the property to be excluded from
stringification.
NOTE 6 An object is rendered as an opening left brace followed by zero or more properties,
separated with commas, closed with a right brace. A property is a quoted String representing the key or property name, a
colon, and then the stringified property value. An array is rendered as an opening left bracket followed by zero or more
values, separated with commas, closed with a right bracket.
Let value be the result of calling the [[Call]] internal method of ReplacerFunction passing
holder as the this value and with an argument list consisting of key and value.
The abstract operation Quote(value) wraps a String value in
double quotes and escapes characters within it.
Let product be code unit 0x0022 (the Unicode double quote character).
For each code unit C in value
If C is 0x0022 or 0x005C (the Unicode reverse solidus character)
Let product be the concatenation of product and code unit 0x005C.
Let product be the concatenation of product and C.
Else if C is backspace, formfeed, newline, carriage return, or tab
Let product be the concatenation of product and code unit 0x005C (the Unicode backslash
character).
Let abbrev be the string value corresponding to the value of C as follows:
backspace
"b"
formfeed
"f"
newline
"n"
carriage return
"r"
tab
"t"
Let product be the concatenation of product and abbrev.
Else if C has a code unit value less than 0x0020 (the Unicode space character)
Let product be the concatenation of product and code unit 0x005C (the Unicode backslash
character).
Let product be the concatenation of product and "u".
Let hex be the string result of converting the numeric code unit value of C to a String of
four hexadecimal digits. Alphabetic hexadecimal digits are presented as lowercase characters.
Let product be the concatenation of product and hex.
Else
Let product be the concatenation of product and C.
Let product be the concatenation of product and code unit 0x0022 (the Unicode double quote
character).
The abstract operation JO(value) serializes an object. It has
access to the stack, indent, gap, and PropertyList of the
invocation of the stringify method.
If stack contains value then throw a TypeError exception because the structure is
cyclical.
Append value to stack.
Let stepback be indent.
Let indent be the concatenation of indent and gap.
If PropertyList is not undefined, then
Let K be PropertyList.
Else
Let K be a List of Strings consisting of the keys
of all the own properties of value whose [[Enumerable]] attribute is true and whose property key is a String value. The ordering of the Strings is the same as that used
by the Object.keys standard built-in function.
Let member be the result of calling the abstract operation Quote with
argument P.
Let member be the concatenation of member and the string ":".
If gap is not the empty String
Let member be the concatenation of member and code unit 0x0020 (the Unicode space
character).
Let member be the concatenation of member and strP.
Append member to partial.
If partial is empty, then
Let final be "{}".
Else
If gap is the empty String
Let properties be a String formed by concatenating all the element Strings of partial with
each adjacent pair of Strings separated with code unit 0x002C (the Unicode comma character). A comma is not
inserted either before the first String or after the last String.
Let final be the result of concatenating "{",properties, and "}".
Else gap is not the empty String
Let separator be the result of concatenating code unit 0x002C (the comma character), code unit 0x000A
(the line feed character), and indent.
Let properties be a String formed by concatenating all the element Strings of partial with
each adjacent pair of Strings separated with separator. The separator String is not inserted
either before the first String or after the last String.
Let final be the result of concatenating "{", code unit 0x000A (the line feed
character), indent, properties, code unit 0x000A, stepback, and "}".
The abstract operation JA(value) serializes an array. It has
access to the stack, indent, and gap of the invocation of the stringify method. The
representation of arrays includes only the elements between zero and array.length– 1 inclusive. Properties whose keys are not array indexes are excluded from the
stringification. An array is stringified as an open left bracket, elements separated by comma, and a closing right
bracket.
If stack contains value then throw a TypeError exception because the structure is
cyclical.
Append value to stack.
Let stepback be indent.
Let indent be the concatenation of indent and gap.
Let properties be a String formed by concatenating all the element Strings of partial with
each adjacent pair of Strings separated with code unit 0x002C (the comma character). A comma is not inserted
either before the first String or after the last String.
Let final be the result of concatenating "[",properties, and "]".
Else
Let separator be the result of concatenating code unit 0x002C (the comma character), code unit 0x000A
(the line feed character), and indent.
Let properties be a String formed by concatenating all the element Strings of partial with
each adjacent pair of Strings separated with separator. The separator String is not inserted
either before the first String or after the last String.
Let final be the result of concatenating "[", code unit 0x000A (the line feed
character), indent, properties, code unit 0x000A, stepback, and "]".
An interface is a set of object property keys whose associated values match a specific specification. Any object that
provides all the properties of an interface in conformance to the interface’s specification conforms to that
interface. An interface isn’t represented by a single object and there may be many distinctly implemented objects
that conform to any interface. An individual object may conform to multiple interfaces.
The Iterator interface includes the following properties:
Property
Value
Requirements
next
A function that returns an object.
The function returns an object that conforms to the IteratorResult interface. If a previous call to the next method of an Iterator has returned an IteratorResult object whose done property is true, then all subsequent calls to the next method of that object must also return an IteratorResult object whose done property is true,
NOTE Arguments may be passed to the next function but their interpretation and validity is
dependent upon the target Iterator. The for-of statement and other common users of Iterators do not pass any arguments, so
Iterators that expect to be used in such a manner must be prepared to deal with being called with no arguments..
The IteratorResult interface includes the following properties:
Property
Value
Requirements
done
Either true or false.
This is the result status of the an iteratornext method call. If the end of the iterator was reached done is true. If the end was not reached done is false and a value is available. If a done property (either own or inherited does not exist), it is consider to have the value false.
value
Any ECMAScript languge value.
If done is false, this is the current iteration element value. If done is true, this is the return value of the iterator, if it supplied one. If the iterator does not have a return value, value is undefined. In that case, the value property may be absent form the conforming object if it does not inherit an explicit value property.
Generator Function objects are constructor functions that are usually created by evaluating GeneratorDeclaration, GeneratorExpression, and GeneratorMethod syntactic productions. They may also be created by calling the
GeneratorFunction constructor.
The GeneratorFunction constructor is the %GeneratorFunction% intrinsic object and the value of the name
GeneratorFunction exported from the built-in module "std:iteration". When
GeneratorFunction is called as a function rather than as a constructor, it creates and initialises a new
GeneratorFunction object. Thus the function call GeneratorFunction(…) is equivalent to the object creation expression new
GeneratorFunction(…) with the same arguments.
However, if the this value passed in the call is an Object with a [[Code]] internal slot whose value is undefined, it initialises the this value using the argument values. This permits
GeneratorFunction to be used both as factory method and to perform constructor instance initialisation.
GeneratorFunction may be subclassed and subclass constructors may perform a super invocation
of the GeneratorFunction constructor to initialise subclass instances. However, all syntactic forms for
defining generator function objects create direct instances of GeneratorFunction. There is no syntactic means
to create instances of GeneratorFunction subclasses.
The last argument specifies the body (executable code) of a generator function; any preceding arguments specify formal
parameters.
When the GeneratorFunction function is called with some arguments p1, p2, … ,
pn, body (where n might be 0, that is,
there are no “p” arguments, and where body might also not be provided), the following
steps are taken:
Let argCount be the total number of arguments passed to this function invocation.
Let P be the empty String.
If argCount = 0, let bodyText be the empty String.
Else if argCount = 1, let bodyText be that argument.
Let parameters be the result of parsing P, interpreted as UTF-16 encoded Unicode text as described in
clause 10.1.1, using FormalParameters as the goal
symbol. Throw a SyntaxError exception if the parse fails.
Let funcBody be the result of parsing bodyText, interpreted as UTF-16 encoded Unicode text as
described in clause 10.1.1, using
FunctionBody[Yield] as the goal symbol. Throw a SyntaxError exception if the parse fails or if any
static semantics errors are detected.
If IsSimpleParameterList of parameters is false and any element of the BoundNames of parameters
also occurs in the VarDeclaredNames of funcBody, then throw a SyntaxError exception.
If any element of the BoundNames of parameters also occurs in the LexicallyDeclaredNames of funcBody,
then throw a SyntaxError exception.
If bodyText is strict mode code (see 10.2.1) then let strict be true, else let strict be
false.
A prototype property is automatically created for every function created using the
GeneratorFunction constructor, to provide for the possibility that the function will be used as a
constructor.
25.2.1.2 new GeneratorFunction ( ... argumentsList)
When GeneratorFunction is called as part of a new expression, it creates and initialises a
newly created object:
Let F be the GeneratorFunction function object on which the new operator was
applied.
Let argumentsList be the argumentsList argument of the [[Construct]] internal method that was invoked
by the new operator.
Return the result of Construct (F, argumentsList).
If GeneratorFunction is implemented as an ECMAScript function
object, its [[Construct]] internal method will perform the above steps.
25.2.2 Properties of the GeneratorFunction Constructor
The GeneratorFunction constructor is a built-in Function object that inherits from the Function constructor. The value
of the [[Prototype]] internal slot of the GeneratorFunction
constructor is the intrinsic object %Function%.
The value of the [[Extensible]] internal slot of the
GeneratorFunction constructor is true.
The GeneratorFunction constructor has the following properties:
Let obj be the result of calling FunctionAllocate with argument
proto, false, and "generator".
Return obj.
The value of the name property of this function is "[Symbol.create]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: true }.
NOTE The GeneratorFunction @@create function passes false as the strict parameter to FunctionAllocate.
This causes the allocated ECMAScript function object to have the internal
methods of a non-strict function. The GeneratorFunction constructor may reset the functions [[Strict]] internal slot to true. It is up to
the implementation whether this also changes the internal methods.
25.2.3 Properties of the GeneratorFunction Prototype Object
The GeneratorFunction prototype object is an ordinary object. It is not a function object and does not have a [[Code]]
internal slot or any other of the internal slots listed in
Table 26 or Table 46. In addition to being the value of the prototype
property of the %GeneratorFunction% intrinsic and is itself the %Generator% intrinsic.
The value of the [[Prototype]] internal slot of the
GeneratorFunction prototype object is the %FunctionPrototype% intrinsic object. The initial value of the [[Extensible]] internal slot of the GeneratorFunction prototype object is
true.
Every GeneratorFunction instance is an ECMAScript function object and
has the internal slots listed in Table 26. The value of the [[FunctionKind]] internal slot for all such instances is
"generator".
The GeneratorFunction instances have the following own properties:
The value of the length property is an integer that indicates the typical number of arguments expected by
the GeneratorFunction. However, the language permits the function to be invoked with some other number of arguments. The
behaviour of a GeneratorFunction when invoked on a number of arguments other than the number specified by its
length property depends on the function.
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]:
true }.
Whenever a GeneratorFunction instance is created another ordinary object is also created and is the initial value of
the generator function’s prototype property. The value of the prototype property is used to initialise
the [[Prototype]] internal slot of a newly created Generator
object before the generator function object is invoked as a constructor for that newly created object.
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: true }.
NOTE Unlike function instances, the object that is the value of the a
GeneratorFunction’s prototype property does not have a constructor property whose value
is the GeneratorFunction instance.
A Generator object is an instance of a generator function and conforms to both the Iterator and Iterable
interfaces.
Generator instances directly inherit properties from the object that is the value of the prototype property
of the Generator function that created the instance. Generator instances indirectly inherit properties from the Generator
Prototype intrinsic, %GeneratorPrototype%.
The Generator prototype object is the %GeneratorPrototype% intrinsic. It is also the initial value of the
prototype property of the %Generator% intrinsic (the GeneratorFrunction.prototype).
The Generator prototype is an ordinary object. It is not a Generator instance and does not have a [[GeneratorState]] internal slot.
The value of the [[Prototype]] internal slot of the
Generator prototype object is the intrinsic object %ObjectPrototype% (19.1.3). The initial value of the [[Extensible]] internal slot of the Function prototype object is
true.
All Generator instances indirectly inherit properties of the Generator prototype object.
Let E be Completion{[[type]]: throw, [[value]]: exception, [[target]]: empty}.
If state is "completed", then return E.
If state is neither "suspendedStart" nor "suspendedYield", then throw a
TypeError exception.
If state is "suspendedStart" then,
Set generator’s [[GeneratorState]] internal slot to "completed".
Once a generator enters the "completed" state it never leaves it and its associated execution context is never resumed. Any execution state associated with
generator can be discard at this point.
Return E.
Let genContext be value of generator’s [[GeneratorContext]] internal slot.
Resume the suspended evaluation of genContext using E as the
result of the operation that suspended it. Let result be the value
returned by the resumed compation.
Set generator’s [[GeneratorState]] internal slot to "completed".
Once a generator enters the "completed" state it never leaves it and its associated execution context is never resumed. Any execution state associated with
generator can be discard at this point.
Resume the suspended evaluation of genContext using NormalCompletion(value) as the result of the operation that suspended it. Let result be the value returned by the resumed
computation.
Set the code evaluation state of genContext such that when evaluation is resumed with a CompletionresumptionValue the following steps will be
performed:
Return resumptionValue.
NOTE: This returns to the evaluation of the YieldExpression production that originally called this
abstract operation.
Resume the suspended evaluation of genContext using NormalCompletion(value) as the result of the operation that suspended it. Let result be the value returned by the resumed
computation.
A Promise is an object that that is used as a place holder for the eventual results of a deferred (and possibly
asynchromous) computation.
Any Promise object is in one of three mutually exclusive states: fulfilled, rejected, and
pending:
A promise p is fulfilled if p.then(f, r) will immediately enqueue a Task to call the
function f.
A promise p is rejected if p.then(f, r) will immediately enqueue a Task to call the
function r.
A promise is pending if it is neither fulfilled nor rejected.
A promise said to be settled if it is not pending, i.e. if it is either fulfilled or rejected.
A promise is resolved if it is settled or if it has been "locked in" match the state of another promise. trying to
Attempting to resolve or reject a resolved promise has no effect. A promise is unresolved if it is not resolved. A
unresolved promise is always in the pending state. A resolved promise may be pending, fullfiled, pending.
A PromiseCapability is a Record value used to encapsulate a promise objects along with the functions that capable of
resolving or rejecting that promise object. PromiseCapability records are produced by the NewPromiseCapability abstract operation.
PromiseCapability Records have the fields listed in Table 47.
Table 47 — PromiseCapability Record Fields
Field Name
Value
Meaning
[[Promise]]
An object
An object that is usable as a promise.
[[Resolve]]
A function object
The function that is used to resolve the given promise object.
[[Reject]]
A function object
The function that is used to reject the given promise object.
Let rejectResult be the result of calling the [[Call]] internal method of capability.[[Reject]]
with undefined as thisArgument and a List
containing value.[[value]] as argumentsList.
The PromiseReaction is a Record value used to store information about how a promise should react when it becomes
resolved or rejected with a given value. PromiseReaction records are created by the then method of the
Promise prototype, and are used by a PromiseReactionTask.
PromiseReaction records have the fields listed in Table 48.
Table 48 — PromiseReaction Record Fields
Field Name
Value
Meaning
[[Capabilities]]
A PromiseCapability record
The capabilities of the promise for which this record provides a reaction handler.
[[Handler]]
A function object
The function that should be applied to the incoming value, and whose return value will govern what happens to the derived promise.
The abstract operation NewPromiseCapability takes a constructor function, and attempts to use that constructor
function in the fashion of the built-in Promise constructor to create a Promise object and extract its
resolve and reject functions. The promise plus the resolve and reject functions are used to initialize a new
PromiseCapability record which is returned as the value of this abstraction operation. This is useful to support
subclassing, as this operation is generic on any constructor that calls a passed executor argument in the same way as
the Promise constructor. We use it to generalize static methods of the Promise constructor to any subclass.
If IsConstructor(C) is false, throw a TypeError
exception.
Assert: C is a constructor function that supports the parameter
conventions of the Promise constructor (see 25.4.3.1).
NOTE This abstract operation is supports Promise subclassing, as it is generic on any
constructor that calls a passed executor function argument in the same way as the Promise constructor. It is used to
generalize static methods of the Promise constructor to any subclass.
The abstract operation TriggerPromiseReactions takes a collection of functions to trigger in the next Task, and calls
them, passing each the given argument. Typically, these reactions will modify a previously-returned promise, possibly
calling in to a user-supplied handler before doing so.
Repeat for each reaction in reactions, in original insertion order
The abstract operation UpdatePromiseFromPotentialThenable takes a value x and tests if it is a thenable. If
so, it tries to use x's then method to resolve the
promised accessed through promiseCapability. Otherwise, it returns "not a thenable".
If Type(x) is not Object, return "not a
thenable".
Let rejectResult be the result of calling the [[Call]] internal method of
promiseCapability.[[Reject]] with undefined as thisArgument and (then.[[value]]) as
argumentsList.
If IsCallable(then) is false, return "not a thenable".
Let thenCallResult be the result of calling the [[Call]] internal method of then passing x as
thisArgument and (promiseCapability.[[Resolve]], promiseCapability.[[Reject]]) as
argumentsList.
Let rejectResult be the result of calling the [[Call]] internal method of
promiseCapability.[[Reject]] with undefined as thisArgument and
(thenCallResult.[[value]]) as argumentsList.
The task PromiseReactionTask with parameters reaction and argument applies the appropriate
handler to the incoming value, and uses the handler's return value to resolve or reject the derived promise associated
with that handler.
Let status be the result of calling the [[Call]] internal method of promiseCapability.[[Reject]]
passing undefined as thisArgument and (handlerResult.[[value]]) as
argumentsList.
NextTask status.
Let handlerResult be handlerResult.[[value]].
If SameValue(handlerResult, promiseCapability.[[Promise]]) is
true, then
Let selfResolutionError be a newly-created TypeError object.
Let status be the result of calling the [[Call]] internal method of promiseCapability.[[Reject]]
passing undefined as thisArgument and (selfResolutionError) as argumentsList
Let status be the result of calling the [[Call]] internal method of promiseCapability.[[Resolve]]
passing undefined as thisArgument and (handlerResult) as argumentsList.
The Promise constructor is the %Promise% intrinsic object and the initial value of the Promise property of
the global object. When Promise is called as a function rather than as a constructor, it initialises its
this value with the internal state necessary to support the Promise.prototype methods.
The Promise constructor is designed to be subclassable. It may be used as the value in an
extends clause of a class definition. Subclass constructors that intend to inherit the specified
Promise behaviour must include a super call to Promise.
When the Promise function is called with argument executor the following steps are taken:
Let promise be the this value.
If IsCallable(executor) is false, then throw a TypeError
exception.
If Type(promise) is not Object, then throw a
TypeError exception.
If promise does not have a [[PromiseStatus]] internal slot, then throw a TypeError
exception.
If promise's [[PromiseStatus]] internal slot
is not undefined, then throw a TypeError exception.
Return InitializePromise(promise, executor).
NOTE The executor argument must be a function object. It is called for
initiating and reporting completion of the possibly deferred action represented by this Promise object. The executor
is called with two arguments: resolve and reject. These are functions that may be used by the
executor function to report eventual completion or failure of the deferred computation. Returning from the
executor function does not mean that the deferred action has been completed but only that the request to eventually
perform the deferred action has been accepted.
The resolve function that is passed to an executor function accepts a single argument. The
executor code may eventually call the resolve function to indicate that it wishes to resolve the
associated Promise objecct. The argument passed to the resolve function represents the eventual value of
the deferred action and can be either the actual fulfillment value or another Promise object which will provide the
value if it is fullfilled.
The reject function that is passed to an executor function accepts a single argument. The
executor code may eventually call the reject function to indicate that the associated Promise is
rejected and will never be fulfilled. The argument passed to the reject function is used as the rejection
value of the promise. Typically it will be an Error object.
The resolve and reject functions passed to an executor function by the Promise constructor have the
capability to actually resolve and reject the associated promise. Subclasses may have different constructor behavior
that passes in customized values for resolve and reject.
Let completion be the result of calling the [[Call]] internal method of executor with
undefined as thisArgument and (resolve, reject) as argumentsList.
The all function returns a new promise which is fulfilled with an array of fulfillment values for the
passed promises, or rejects with the reason of the first passed promise that rejects. It casts all elements of the
passed iterable to promises as it runs this algorithm.
Let resolveResult be the result of calling the [[Call]] internal method of
promiseCapability.[[Resolve]] with undefined as thisArgument and (values)
as argumentsList.
A Promise.all resolve element function is an anonymous built-in function that is used
to resolve a specific Promise.all element.. Each Promise.all resolve element function has [[Index]], [[Values]], [[Capabilities]], and
[[RemainingElements]] internal slots.
When a Promise.all resolve element function F is called with argument
x, the following steps are taken:
Let index be the value of F's [[Index]] internal slot.
Let values be the value of F's [[Values]] internal slot.
Let promiseCapability be the value of F's [[Capabilities]] internal slot.
Let remainingElementsCount be the value of F's [[RemainingElements]] internal slot.
Set remainingElementsCount.[[value]] to remainingElementsCount.[[value]] - 1.
If remainingElementsCount.[[value]] is 0,
Return the result of calling the [[Call]] internal method of promiseCapability.[[Resolve]] with
undefined as thisArgument and (values) as argumentsList.
Let resolveResult be the result of calling the [[Call]] internal method of
promiseCapability.[[Resolve]] with undefined as thisArgument and (x) as
argumentsList.
The race function returns a new promise which is settled in the same way as the first passed promise to
settle. It casts all elements of the passed iterable to promises as it
runs this algorithm.
NOTE The race function requires its this value to be a constructor
function that supports the parameter conventions of the Promise constructor. It also requires that its
this value provides a cast method.
Let rejectResult be the result of calling the [[Call]] internal method of promiseCapability.[[Reject]]
with undefined as thisArgument and (r) as argumentsList.
Let resolveResult be the result of calling the [[Call]] internal method of
promiseCapability.[[Resolve]] with undefined as thisArgument and (x) as
argumentsList.
NOTE The resolve function requires that its this value to be a
constructor function that supports the parameter conventions of the Promise constructor.
The value of the [[Prototype]] internal slot of the
Promise prototype object is the standard built-in Object prototype object (19.1.3). The Promise prototype object is an ordinary object. It
does not have a [[PromiseStatus]] internal slot or any of
the other internal slots of Promise instances..
A promise resolution handler function is an anonymous built-in function that has the ability to handle a promise
being resolved, by "unwrapping" any incoming values until they are no longer promises or thenables and can be passed to
the appropriate fulfillment handler.
Each promise resolution handler function has [[Promise]], [[FulfillmentHandler]], and [[RejectionHandler]] internal slots.
When a promise resolution handler function F is called with argument x, the following steps are
taken:
Let promise be the value of F's [[Promise]] internal slot.
Let fulfillmentHandler be the value of F's [[FulfillmentHandler]] internal slot.
Let rejectionHandler be the value of F's [[RejectionHandler]] internal slot.
Let selfResolutionError be a newly-created TypeError object.
Return the result of calling the [[Call]] internal method of rejectionHandler with undefined as
thisArgument and (selfResolutionError) as argumentsList.
Let C be the value of promise's [[PromiseConstructor]] internal slot.
Promise instances are ordinary objects that inherit properties from the Promise prototype object (the intrinsic,
%PromiseProtype%). Promise instances are initially created with the internal slots described in Table
49.
Table 49 — Internal Slots of Promise Instances
Internal Slot
Description
[[PromiseStatus]]
A string value that governs how a promise will react to incoming calls to its then method. The possible values are: undefined, "unresolved","has-resolution", and "has-rejection".
[[PromiseConstructor]]
The function object that was used to construct this promise. Checked by the cast method of the Promise constructor.
[[PromiseResult]]
The value with which the promise has been resolved or rejected, if any. Only meaningful if [[PromiseStatus]] is not "unresolved".
[[PromiseResolveReactions]]
A List of PromiseReaction records to be processed when/if the promise transitions from being unresolved to having a resolution.
[[PromiseRejectReactions]]
A List of PromiseReaction records to be processed when/if the promise transitions from being unresolved to having a rejection.
The value of the [[Prototype]] internal slot of the Reflect
object is the standard built-in Object prototype object (19.1.3).
The Reflect object is not a function object. It does not have a [[Construct]] internal method; it is not possible to use
the Reflect object as a constructor with the new operator. The Reflect object also does not have a [[Call]]
internal method; it is not possible to invoke the Reflect object as a function.
The %Realm% intrinsic object is the constructor for Realm objects. When %Realm% is called as a function rather than as
a constructor, it initialises its this value with the internal state necessary to support the
%Realm%.prototype built-in methods.
The %Realm% constructor is designed to be subclassable. It may be used as the value in an extends clause
of a class definition. Subclass constructors that intend to inherit the specified Realm
behaviour must include a super call to %Realm%.
If IsCallable(initializer) is false, throw a TypeError
exception.
Let status be the result of calling the [[Call]] internal method of the initializer function,
passing realmObject as the this value and builtins as the single argument.
The value of the [[Prototype]] internal slot of the
%Realm% prototype object is the standard built-in Object prototype object (19.1.3). The %Realm% prototype object is an ordinary object. It
does not have a [[Realm]] internal slot.
%Realm% instances are ordinary objects that inherit properties from the %Realm% prototype object. %Realm% instances each
have a [[Realm]] internal slot.
The %Loader% intrinsic object is the constructor for Loader objects. When %Loader% is called as a function rather than
as a constructor, it initialises its this value with the internal state necessary to support the
%Loader%.prototype built-in methods.
The %Loader% constructor is designed to be subclassable. It may be used as the value in an extends clause
of a class definition. Subclass constructors that intend to support the specified Loader behaviour must include a
super call to %Loader%.
The value of the name property of this function is "[Symbol.create]".
This property has the attributes { [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]:
true }.
26.3.3 Properties of the %Loader% Prototype Object
The value of the [[Prototype]] internal slot of the
%Loader% prototype object is the standard built-in Object prototype object (19.1.3). The %Loader% prototype object is an ordinary object. It
does not have [[LoaderRecord]] internal slot.
The phrase "this Loader" within the specification of the following
methods refers to the result returned by performing the abstract operation thisLoader with the this value of the
current method invocation passed as the argument.
The abstract operation thisLoader with argument value performs the following steps:
If Type(value) is Object and value has a [[LoaderRecord]]
internal slot, then
The define method installs a module in this loader's module registry for source
using name as the registry key. The module is not immediately available. The translate and
instantiate hooks are called asynchronously, and dependencies are loaded asynchronously. define
returns a Promise object that resolves to undefined when the new module and its dependencies are installed in
the registry.
When the define method is called with arguments name, source, and optional argument
options the following steps are taken:
If this Loader's module registry contains a Module with the given normalized name, return it. Otherwise,
return undefined. If the module is in the registry but has never been evaluated, first
synchronously evaluate the bodies of the module and any dependencies that have not evaluated yet.
When the get method is called with the argument name, the following steps are taken:
The import method asynchronously loads, links, and evaluates a module and all its dependencies if these
actions have not already been performed. The argument name is the registry key for the module.
import returns a Promise that resolves to the Module object once it has been committed to the
registry and evaluated.
When the import method is called with argument name and optional arguments options
the following steps are taken:
If the optional argument options is an object with an address property the string value of that
property is used as the module location and module loading starts with the fetch step. If an address property
is not present, module loading starts with the locate step.
The length property of the import method is 1.
NOTE Invoking the import method is the dynamic equivalent (when combined with
normalization) of: ImportDeclaration::importModuleSpecifier;
The load method asynchronously loads and links and all its dependencies if these actions have not already
been performed. The argument name is the registry key for the module. load returns a Promise that
resolves to the Module object once it has been committed to the registry.
When the load method is called with argument name and optional arguments options the
following steps are taken:
If the optional argument options is an object with an address property. The string value of
that property is used as the module location and module loading starts with the fetch step. If an address
property is not present, module loading starts with the locate step.
The length property of the import method is 1.
NOTE The load method differs from the import method in that it does
not force evaluation of the loaded module.
The module method asynchronously loads, links, and evaluates evaluates an anonymous module from
source. The module's dependencies, if any, are loaded and committed to the registry. The anonymous module
itself is not added to the registry. module returns a Promise object that resolves to a new Module instance
object once the given module body has been evaluated.
When the module method is called with argument source and optional arguments options
the following steps are taken:
In the prototype this is the Module Factory Function. However, this factory seems to
have only specialized utility and it seems to unnecessarily clutter the “global” namespace of Module
abstractions. Making it a method of module loaders seems like a more sanity thing to do, but we can break it out if
that;s what people really want.
Also need to reconcile with are execute factory returns by the instantiate hook. Is
this method intended to be able as an execute factory. If sho it probably needs to accept multiple arguments.
When the newModule method is called with argument obj it creates a new Module objects whose
export properties are derived form the properties of obj. The following steps are performed:
If Type(obj) is not Object, throw a TypeError
exception.
Let mod be CreateLinkedModuleInstance( )
Let keys be the result of calling the ObjectKeys abstract operation passing obj as the argument.
Loader hooks are methods that are called at various points in the process of loading a module. The %Loader% prototype
provide default implementations for the hook methods. However, individual Loader object may over-ride these defaults
using own properties.
This is a Loader hook that may be over-riden by an own property of Loader instances. The normalize hook
is called once per distinct ModuleSpecifier String value in a ModuleBody, while the module ModuleBody with that is being loaded. The
name argument is the StringValue of a ModuleSpecifier.
The normalize hook returns an eventual String, the normalised module name, which is used for the rest of
the import process. In particular, the [[Loads]] and [[Modules]] Lists of a ModuleLinkage record are both keyed by
normalised module names. The module registry contains at most one module for a given normalised module name.
After calling this hook, if the normalised module name is in the registry or the load table, no new Load
Record is created. Otherwise the loader initialtes a load for that module that starts by calling the locate
hook.
This is a Loader hook that may be over-riden by an own property of Loader instances. The locate hook is
called for each distinct normalized import ModuleSpecifier immediately after the
normalize hook returns successfully, unless the module is already loaded or loading.
The locate hook is called to obtain to determine the Loader-dependent resource address (URL, path, etc.)
corresponding to normalised module name. The resource address is used later in the Loader pipeline to retrive the source
code of the requested module.
When a locate hook is called by an Loader object the argument loadRequest is a LoadRequest
object (15.2.3.2). The value of the name property
is the normalised module name. The locate hook returns an eventual value that is used as the resource
address. When the returned value is resolved, loading will continue with the fetch hook.
NOTE The System.locate hook typically is significantly more complicated than
the default locate hook.
When the fetch loader hook is called with argument loadRequest, the following steps are
taken:
Throw a TypeError exception.
This is a Loader hook that will normally be over-riden by an own property of Loader instances. The fetch
hook is called by a Loader for all modules whose source code was not directly provided to the Loader. It is also used to
process the import keyword. The fetch hook is not called for module bodies directly provided
as arguments to loader.module() or loader.define(). However, the fetch hook may
be called when loading other modules imported by such modules.
When a fetch hook is called by an Loader object the argument loadRequest is a LoadRequest
object (15.2.3.2) with an address property. The
value of the address property identifies the module source code to fetch. The fetch hook returns an
eventual String containing the source code of the module.
This is a Loader hook that may be over-riden by an own property of Loader instances. The
translate hook is called for each ModuleBody including those passed to
loader.module() or loader.define().The translate hook is called prior to parsing
the ModuleBody and provides a Loader the opportunity to modify or replace the source code that
will be parse.
NOTE An example of the use of the translate hook would be to translate source
code for a another programing language into an ECMAScript ModuleBody.
When a translate hook is called by an Loader object the argument loadRequest is a LoadRequest
object (15.2.3.2) with address and
source properties. The value of the address property identifies the module source code to
fetch. The value of the source property is the resolved value returned from the fetch hook.
The translate hook returns either an eventual String value ECMAScript that will be parsed as a ModuleBody.
When the instantiate loader hook is called with argument loadRequest, the following steps are taken:
Return undefined.
This hook allows a Loader to provide interoperability with other module systems.
When a instantiate hook is called by an Loader object the argument, loadRequest, is a
LoadRequest object (15.2.3.2) with address and
source properties. loadRequest.name, loadRequest.metadata,
and loadRequest.address are the same values passed to the fetch and
translate hooks. loadRequest.source is the the value produced by the
translate hook.
If the instantiate hook returns an eventual undefined, then the loader uses the default linking
behavior. It parses loadRequest.source as a Module, looks at its imports, loads its dependencies
asynchronously, and finally links them together and adds them to the registry.
Otherwise, the instantiate hook must return an eventual instantiationRequest object. An
instantiateRequest object has two required properties. The value of the deps property is an
array of strings. Each string is the name of a module upon which the module identified by loadRequest has
dependencies. The value of the execute property is a function which the loader will use to create the
module and link it with its clients and dependencies. The function should expect to receive the same number of arguments
as the size of the deps array and must return an eventual Module object. The arguments are Module objects
and have a one-to-one correspondence with elements of the deps array.
The module is evaluated during the linking process. First all of the modules it depends upon are linked and evaluated
, and then passed to the execute function. Then the resulting module is linked with the downstream
dependencies.
NOTE This feature is provided in order to permit custom loaders to support using
import to import pre-ES6 modules such as AMD modules. The design requires incremental linking when such
modules are present, but it ensures that modules implemented with standard source-level module declarations can still be
statically validated.
Loader instances are ordinary objects that inherit properties from the %LoaderPrototype% intrinsic object. Loader
instances each have a [[Loader]] interal slot whose value after initialization is the Loader Record that the Load instance
reflects.
A Loader Iterator object represents a specific iteration over the module registry of some specific Loader instance
object. There is not a named constructor for Loader Iterator objects. Instead, Loader iterator objects are created by
calling certain methods of Loader instance objects.
Several methods of Loader objects return Iterator objects. The abstract operation CreateLoaderIterator with arguments
loader and kind is used to create such iterator objects. It performs the following steps:
Assert: loader is an initialized Loader instance object.
Let iterator be the result of ObjectCreate(%LoaderIteratorPrototype%, ([[Loader]], [[LoaderNextIndex]], [[LoaderIterationKind]])).
All Loader Iterator Objects inherit properties from the %LoaderIteratorPrototype% intrinsic object. The
%LoaderIteratorPrototype% intrinsic object is an ordinary object and its [[Prototype]] internal slot is the %ObjectPrototype% intrinsic object. In
addition, %LoaderIteratorPrototype% has the following properties:
Let entries be the List that is the value of the
loaderRecord.[[Modules]] internal slot of
m.
Repeat while index is less than the total number of elements of entries. The number of elements must
be redetermined each time this method is evaluated.
Let e be the Record {[[key]], [[value]]} that is the value of entries[index].
Set index to index+1;
Set the [[LoaderNextIndex]] internal slot of
O to index.
If e.[[key]] is not empty, then
If itemKind is "key" then, let result be
e.[[key]].
Else if itemKind is "value" then, let
result be e.[[value]].
NOTE Setting the [[Loader]] internal slot to undefined when the iterator is exhausted
ensures that the same iterator can not restarted if new entries are subsequently added. This condition is tested in
step 7.
Loader Iterator instances are ordinary objects that inherit properties from the %LoaderIteratorPrototype% intrinsic
object. Loader Iterator instances are initially created with the internal slots described in Table
50.
Table 50 — Internal Slots of Loader Iterator Instances
Internal Slot
Description
[[Loader]]
The Loader object that is being iterated.
[[LoaderNextIndex]]
The integer index of the next Loader registry data element to be examined by this iterator.
[[LoaderterationKind]]
A string value that identifies what is to be returned for each element of the iteration. The possible values are: "key", "value", "key+value".
When Proxy is called as part of a new expression it is a constructor: it creates and
initializes a new exotic proxy object. Proxy called as part of a new expression with arguments
target and handler performs the following steps:
The Proxy.revocable function is used to create a revocable Proxy object. When
Proxy.revocable is called with arguments target and handler the following steps are
taken:
any character in the Unicode categories “Uppercase letter (Lu)”, “Lowercase letter (Ll)”, “Titlecase letter (Lt)”, “Modifier letter (Lm)”, “Other letter (Lo)”, or “Letter number (Nl)”.
UnicodeCombiningMark::
any character in the Unicode categories “Non-spacing mark (Mn)” or “Combining spacing mark (Mc)”
UnicodeDigit::
any character in the Unicode category “Decimal number (Nd)”
UnicodeConnectorPunctuation::
any character in the Unicode category “Connector punctuation (Pc)”
ReservedWord::
Keyword
FutureReservedWord
NullLiteral
BooleanLiteral
Keyword::one of
break
do
instanceof
typeof
case
else
new
var
catch
finally
return
void
continue
for
switch
while
debugger
function
this
with
default
if
throw
delete
in
try
FutureReservedWord::one of
class
enum
extends
super
const
export
import
The following tokens are also considered to be FutureReservedWords when parsing strict mode code (see 10.2.1).
Annex B(normative) Additional ECMAScript Features for Web
Browsers
The ECMAScript language syntax and semantics defined in this annex are required when the ECMAScript host is a web browser.
The content of this annex is normative but optional if the ECMAScript host is not a web browser.
The syntax and semantics of 11.8.4 is extended as follows except that this
extension is not allowed for strict mode code:
Syntax
EscapeSequence::
CharacterEscapeSequence
OctalEscapeSequence
HexEscapeSequence
UnicodeEscapeSequence
OctalEscapeSequence::
OctalDigit[lookahead ∉ DecimalDigit]
ZeroToThreeOctalDigit[lookahead ∉ DecimalDigit]
FourToSevenOctalDigit
ZeroToThreeOctalDigitOctalDigit
ZeroToThree::one of
0123
FourToSeven::one of
4567
Static Semantics
The CV of EscapeSequence::OctalEscapeSequence is the CV of the OctalEscapeSequence.
The CV of OctalEscapeSequence::OctalDigit is the character whose code unit value is the MV of the OctalDigit.
The CV of OctalEscapeSequence::ZeroToThreeOctalDigit is the character whose code unit value is (8
times the MV of the ZeroToThree) plus the MV of the OctalDigit.
The CV of OctalEscapeSequence::FourToSevenOctalDigit is the character whose code unit value is (8
times the MV of the FourToSeven) plus the MV of the OctalDigit.
The CV of OctalEscapeSequence::ZeroToThreeOctalDigitOctalDigit is the
character whose code unit value is (64 (that is, 82) times the MV of the ZeroToThree) plus (8 times
the MV of the first OctalDigit) plus the MV of the second OctalDigit.
The syntax of 21.2.1 is extended as modified and extended as follows. These changes
introduce ambiguities that are broken by the ordering or grammar productions and by contextual information. The following
grammar is used, with each alternative considered only if previous production alternatives do not match.
Within 21.2.2.5 reference to “Atom::(Disjunction) ”
are to be interpreted as meaning “Atom::(Disjunction) or AtomNoBrace::(Disjunction) ”.
Term (21.2.2.5) includes the following additional evaluation rule:
The production Term::QuantifiableAssertionQuantifier evaluates the same as the production Term::AtomQuantifier but with QuantifiableAssertionsubstituted for Atom.
Atom (21.2.2.8) evaluation rules for the Atom productions except for
Atom::PatternCharacter
are also used for the AtomNoBrace productions, but with AtomNoBrace
substituted for Atom. The following evaluation rule is also
added:
The production AtomNoBrace::PatternCharacterNoBrace evaluates as follows:
Let ch be the character represented by PatternCharacterNoBrace.
Let A be a one-element CharSet containing the character ch.
Call CharacterSetMatcher(A, false) and return its Matcher result.
CharacterEscape (21.2.2.10) includes the following additional evaluation rule:
The production CharacterEscape::OctalEscapeSequence evaluates by evaluating the CV of the OctalscapeSequence (see B.1.2) and returning its
character result.
ClassAtom (21.2.2.17) includes the following additional evaluation rules:
The production ClassAtomInRange::- evaluates by returning the CharSet containing the one character -.
The production ClassAtomInRange::ClassAtomNoDashInRange evaluates by evaluating ClassAtomNoDashInRange to
obtain a CharSet and returning that CharSet.
ClassAtomNoDash (21.2.2.18) includes the following additional evaluation rules:
The production ClassAtomNoDashInRange::SourceCharacterbut not one of\or]or- evaluates
by returning a one-element CharSet containing the character represented by SourceCharacter.
The production ClassAtomNoDashInRange::\ClassEscape but ony if…, evaluates by evaluating ClassEscape to obtain a CharSet and returning that CharSet.
The production ClassAtomNoDashInRange::\IdentityEscape evaluates by returning the character represented by IdentityEscape.
The escape function is a property of the global object. It computes a new version of a String value in
which certain characters have been replaced by a hexadecimal escape sequence.
For those characters being replaced whose code unit value is 0xFF or less, a two-digit escape sequence of
the form %xx is used. For those characters being replaced whose code unit value is greater than
0xFF, a four-digit escape sequence of the form %uxxxx is used.
When the escape function is called with one argument string, the following steps are taken:
Let char be the code unit (represented as a 16-bit unsigned integer) at position k within
string.
If char is the code point of one of the 69 nonblank
characters ″ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789@*_+-./″ then,
Let S be a String containing the single character char.
Else if char > 256,
Let S be a String containing six characters ″%uwxyz″
where wxyz are four hexadecimal digits encoding the value of char.
Else, char < 256
Let S be a String containing three characters ″%xy″
where xy are two hexadecimal digits encoding the value of char.
Let R be a new String value computed by concatenating the previous value of R and S.
Increase k by 1.
Return R.
NOTE The encoding is partly based on the encoding described in RFC 1738, but the entire
encoding specified in this standard is described above without regard to the contents of RFC 1738. This encoding does
not reflect changes to RFC 1738 made by RFC 3986.
The unescape function is a property of the global object. It computes a new version of a String value in
which each escape sequence of the sort that might be introduced by the escape function is replaced with the
character that it represents.
When the unescape function is called with one argument string, the following steps are
taken:
Let c be the code unit at position k within string.
If c is %,
If k ≤ length−6 and the code unit at position k+1 within string is
u and the four code units at positions k+2, k+3, k+4, and k+5
within string are all hexadecimal digits, then
Let c be the code unit whose value is the integer represented by the four hexadecimal digits at
positions k+2, k+3, k+4, and k+5 within string.
Increase k by 5.
Else if k ≤ length−3 and the two code units at positions k+1 and k+2
within string are both hexadecimal digits, then
Let c be the code unit whose value is the integer represented by two zeroes plus the two
hexadecimal digits at positions k+1 and k+2 within string.
Increase k by 2.
Let R be a new String value computed by concatenating the previous value of R and c.
Increase k by 1.
Return R.
B.2.2 Additional Properties of the Object.prototype Object
Object.prototype.__proto__ is an accessor property with attributes { [[Enumerable]]: false, [[Configurable]]: true }. The [[Get]] and [[Set]] attributes are
defined as follows
The substr method takes two arguments, start and length, and returns a substring of
the result of converting the this object to a String, starting from character position start and running
for length characters (or through the end of the String if length is undefined). If
start is negative, it is treated as (sourceLength+start) where sourceLength is the length of the String. The result is
a String value, not a String object. The following steps are taken:
If intStart is negative, then let intStart be max(size + intStart,0).
Let resultLength be min(max(end,0), size – intStart).
If resultLength ≤ 0, return the empty String "".
Return a String containing resultLength consecutive characters from S beginning with the character at
position intStart.
The length property of the substr method is 2.
NOTE The substr function is intentionally generic; it does not require that its
this value be a String object. Therefore it can be transferred to other kinds of objects for use as a method.
When the anchor method is called with argument name, the following steps are taken:
Let S be the this value.
Return the result of performing the abstract operation CreateHTML with arguments S, "a",
"name" and name.
The abstract operation CreateHTML is called with arguments
string, tag, attribute, and value. The
arguments tag and attribute must be string values. The following steps are taken:
Let escapedV be the string value that is the same as V except that each occurrence of the
character " (code unit value 0x0022) in V has been replaced with the six character sequence
""".
Let p1 be the string value that is the concatenation of the following string values:
p1
a single space code unit 0x0020
attribute
"="
′"′
escapedV
′"′
Let p2 be the string value that is the concatenation of p1 and ">".
Let p3 be the string value that is the concatenation of p2 and S.
Let p4 be the string value that is the concatenation of p2, "</", tag, and
">".
NOTE The property toUTCString is preferred. The toGMTString
property is provided principally for compatibility with old code. It is recommended that the toUTCString
property be used in new ECMAScript code.
The Function object that is the initial value of Date.prototype.toGMTString is the same Function object
that is the initial value of Date.prototype.toUTCString.
B.2.5 Additional Properties of the RegExp.prototype Object
When the compile method is called with arguments pattern and flags, the following steps are
taken:
Let O be the this value.
If Type(O) is not Object or Type(O) is Object and O does not have a
[[RegExpMatcher]] internal slot, then
Throw a TypeError exception.
Let extensible be the result of calling the [[IsExtensible]] internal method of O.
If extensible is false, then throw a TypeError exception.
If Type(pattern) is Object and pattern has a
[[RegExpMatcher]] internal slot, then
If the value of pattern’s [[RegExpMatcher]] internal slot is undefined, then throw a
TypeError exception.
If flags is not undefined, then throw a TypeError exception.
Let P be the value of pattern’s [[OriginalSource]] internal slot.
Let F be the value of pattern’s [[OriginalFlags]] internal slot.
Else,
let P be pattern.
let F be flags.
Return the result of the abstract operation RegExpInitialise with arguments
O,P, and F.
NOTE The compile method completely reinitialises the this object RegExp
with a new pattern and flags. An implementaton may interpret use of this method as an assertion that the resulting
RegExp object will be used multiple times and hence is a candidate for extra optimization.
B.3.1 __proto___ Property Names in Object Initialisers
In 12.1.5 the PropertyDefinitionEvaluation algorithm for the production PropertyDefinition:PropertyName:AssignmentExpression is replaced with the following:
B.3.2 Web Legacy Compatibility for Block-Level Function Declarations
Prior to the Sixth Edition, the ECMAScript specification did not define the occurrence of a FunctionDeclaration as an element of a Block statement’s StatementList. However, support for that form of FunctionDeclaration was an
allowable extension and most browser-hosted ECMAScript implementations permitted them. However, the semantics of such
declarations differ among those implementations. Because of these semantic differences, existing web ECMAScript code that
uses Block level function declarations is only portable among browser implementation if the usage
only depends upon the semantic intersection of all of the browser implementations for such declarations. The following are
the use cases that fall within that intersection semantics:
A function is declared and only referenced within a single block
A function declaration with the name f is declared exactly once within the function code of an
enclosing function g and that declaration is nested within a Block.
No other declaration of f that is not a var declaration occurs within the function code
of g
All references to f occur within the StatementList of the Block containing the declaration of f.
A function is declared and possibly used within a single Block but also referenced by an inner
function definition that is not contained within that same Block.
A function declaration with the name f is declared exactly once within the function code of an
enclosing function g and that declaration is nested within a Block.
No other declaration of f that is not a var declaration occurs within the function code
of g
References to f may occur within the StatementList of the Block containing the declaration of f.
References to f occur within the function code of g that lexically follows the Block containing the declaration of f.
A function is declared and possibly used within a single block but also referenced within subsequent blocks.
A function declaration with the name f is declared exactly once within the function code of an
enclosing function g and that declaration is nested within a Block.
No other declaration of f that is not a var declaration occurs within the function code
of g
References to f may occur within the StatementList of the Block containing the declaration of f.
References to f occur within another function h that is nested within g and no
other declaration of f shadows the references to f from within h.
All invocations of h occur after the declaration of f has been evaluated.
The first use case is interoperable with the inclusion of Block level function declarations in
the sixth edition. Any pre-existing ECMAScript code that employees that use case will operate using the Block level
function declarations semantics defined by clauses 10 and 13 of this specification.
Sixth edition interoperability for the second and third use cases requires the following extensions to the clauses 10 and
14 semantics. These extensions are applied to a non-strict mode functions g if the above pre-conditions of use
cases 2 and 3 above exist at the time of static semantic analysis of g. However, the last pre-condition of use
case 3 is not included in this determination and the determination is not applied to any function declaration that is nested
within syntactic constructs that are specified in the Fifth edition of this specification.
Let B be environment record for the construct within g that introduces a new environment contour and
which most closely encloses the declaration of f, all function code references to f, and the definitions
of all nested functions that contain unshadowed references to f. This syntactic construct may be the
definition of g itself, in which case B is the function
environment record for g.
As part of the instantiation of B, its CreateMutableBinding concrete method is called with arguments
“f” (the string name of the function) and false. This creates an uninitialised binding for the name
f. Any reference that resolves to that binding prior to step 3 below will throw a ReferenceError
exception.
When the InitialiseBinding concrete method is used to initialise the binding for the function declaration f
also invoke InitialiseBind on B using the same arguments.
If an ECMAScript implication has a mechanism that produces diagnostic warning messages, a warning should be produced for
each function g for which the above steps are performed.
Annex C(informative) The Strict Mode of ECMAScript
The strict mode restriction and exceptions
The identifiers "implements", "interface", "let", "package",
"private", "protected", "public", "static", and "yield" are
classified as FutureReservedWord tokens within strict mode code. (11.6.2.2).
A conforming implementation, when processing strict mode code, may not extend the
syntax of NumericLiteral (11.8.3) to include
LegacyOctalIntegerLiteral as described in B.1.1.
A conforming implementation, when processing strict mode code (see 10.2.1), may not extend the syntax of EscapeSequence to include
LegacyOctalEscapeSequence as described in B.1.2.
Assignment to an undeclared identifier or otherwise unresolvable reference does not create a property in the global
object. When a simple assignment occurs within strict mode code, its LeftHandSide
must not evaluate to an unresolvable Reference. If it does a
ReferenceError exception is thrown (6.2.3.2). The LeftHandSide also may not be a
reference to a data property with the attribute value {[[Writable]]:false}, to an accessor property with the
attribute value {[[Set]]:undefined}, nor to a non-existent property of an object whose [[Extensible]] internal slot has the value false. In these cases a
TypeError exception is thrown (12.13).
The identifier eval or arguments may not appear as the LeftHandSideExpression of an
Assignment operator (12.13) or of a PostfixExpression (12.13) or as the UnaryExpression operated upon by a Prefix Increment (12.4.7) or a Prefix Decrement (12.4.8) operator.
Arguments objects for strict mode functions define non-configurable accessor properties named "caller" and
"callee" which throw a TypeError exception on access (9.2.8).
Arguments objects for strict mode functions do not dynamically share their array indexed property values with the
corresponding formal parameter bindings of their functions. (9.4.4.1).
For strict mode functions, if an arguments object is created the binding of the local identifier arguments
to the arguments object is immutable and hence may not be the target of an assignment expression. (9.4.4.1).
It is a SyntaxError if strict mode code contains an ObjectLiteral with
more than one definition of any data property (12.1.5).
It is a SyntaxError if the Identifier"eval" or the Identifier"arguments"
occurs as the Identifier in a PropertySetParameterList of a PropertyDefinition that is contained in strict code or if its
FunctionBody is strict code (12.1.5).
Strict mode eval code cannot instantiate variables or functions in the variable environment of the caller to eval.
Instead, a new variable environment is created and that environment is used for declaration binding instantiation for the
eval code (18.2.1).
If this is evaluated within strict mode code, then the this value is
not coerced to an object. A this value of null or undefined is not converted to the global object and
primitive values are not converted to wrapper objects. The this value passed via a function call (including calls
made using Function.prototype.apply and Function.prototype.call) do not coerce
the passed this value to an object (8.3.2, 12.1.1, 19.2.3.3, 0).
When a delete operator occurs within strict mode code, a
SyntaxError is thrown if its UnaryExpression is a direct reference to a variable, function argument, or
function name(12.4.4).
When a delete operator occurs within strict mode code, a
TypeError is thrown if the property to be deleted has the attribute { [[Configurable]]:false } (12.4.4).
It is a SyntaxError if a VariableDeclaration occurs within strict code
and its Identifier is eval or arguments (13.2.2).
Strict mode code may not include a WithStatement. The occurrence of a WithStatement in such a context is an
SyntaxError (13.10).
It is a SyntaxError if a TryStatement with a Catch occurs within
strict code and the Identifier of the Catch production is eval or arguments (13.14)
It is a SyntaxError if the identifier eval or arguments appears within the FormalParameters of a strict mode FunctionDeclaration or FunctionExpression (0)
A strict mode function may not have two or more formal parameters that have the same name. An attempt to create such a
function using a FunctionDeclaration, FunctionExpression, or Function constructor is a
SyntaxError (0, 19.2.1).
An implementation may not extend, beyond that defined in this specification, the meanings within strict mode functions of
properties named caller or arguments of function instances. ECMAScript code may not create or
modify properties with these names on function objects that correspond to strict mode functions (9.2.2, 9.4.4).
It is a SyntaxError to use within strict mode code the identifiers
eval or arguments as the Identifier of a FunctionDeclaration or
FunctionExpression or as a formal parameter name (0). Attempting to dynamically define such a strict mode function
using the Function constructor (19.2.1) will throw a SyntaxError
exception.
Annex D(informative) Corrections and Clarifications
with Possible Compatibility Impact
In Edition 6
20.3.1.14: Previous editions permitted the TimeClip abstract
operation to return either +0 or −0 as the representation of a 0 time
value. The 6th Edition specifies that +0 always returned. This means that for the 6th Edition the time value of a Date object is never observably −0 and methods that
return time values never return −0.
20.3.1.15: If a time zone offset is not present, the local time zone is used.
Edition 5.1 incorrectly stated that a missing time zone should be interpreted as “z”.
20.3.4.36: If the year cannot be represented using the Date Time String Format
specified in 20.3.1.15 a RangeError exception is thrown. Previous editions did not
specify the a behaviour for that case.
20.3.4.41: Previous editions did not specify the value returned by Date.prototype.toString when this
time value is NaN. The 6th Edition specifies the result to be the String value is "Invalid
Date".
21.2.3.1, 21.2.3.3.4: If any LineTerminator
code points in the value of the source property of an RegExp instance must be expressed using an escape sequence.
Edition 5.1 only required the escaping of "/".
In Edition 5.1
Clause references in this list refer to the clause numbers used in Edition 5.1.
: CV definitions added for DoubleStringCharacter::LineContinuation and SingleStringCharacter::LineContinuation .
: The argument S is not ignored. It controls whether an exception is thrown when attempting to set an immutable binding.
: In algorithm step 5, true is passed as the last argument to [[DefineOwnProperty]].
: Former algorithm step 5.e is now 5.f and a new step 5.e was added to restore compatibility with 3rd Edition when
redefining global functions.
: In the final bullet item, use of IEEE 754 round-to-nearest mode is specified.
12.6.3: Missing ToBoolean restored in step 3.a.ii of
both algorithms.
12.6.4: Additional final sentences in each of the last two paragraphs clarify
certain property enumeration requirements.
12.7, 12.8, 12.9: BNF modified to clarify that a continue or break statement
without an Identifier or a return statement without an Expression
may have a LineTerminator before the semi-colon.
12.14: Step 3 of algorithm 1 and step 2.a of algorithm 3 are corrected such that the value field of B is passed as a parameter rather than B
itself.
: In step 2 of algorithm, clarify that S may be the empty string.
: In step 2 of algorithm clarify that trimmedString may be the empty string.
15.1.3: Added notes clarifying that ECMAScript’s
URI syntax is based upon RFC 2396 and not the newer RFC 3986. In the algorithm for Decode, a step was
removed that immediately preceded the current step 4.d.vii.10.a because it tested for a condition that cannot occur.
: Corrected use of variable P in steps 5 and 6 of algorithm.
15.2.4.2: Edition 5 handling of undefined and null as this value caused existing code to fail. Specification modified to
maintain compatibility with such code. New steps 1 and 2 added to the algorithm.
: Steps 5 and 7 of Edition 5 algorithm have been deleted because they imposed requirements upon the argArray
argument that are inconsistent with other uses of generic array-like objects.
: In step 9.a, incorrect reference to relativeStart was replaced with a reference to actualStart.
: Clarified that the default value for fromIndex is the length minus 1 of the array.
: In step 10 (corresponding to step 8 in 5.1) of the algorithm, undefined is now the specified return value.
: In step 11.d.iii (corresponding to 9.c.ii in 5.1) the first argument to
the [[Call]] internal method has been changed to undefined for consistency with the definition of
Array.prototype.reduce.
: In Algorithm steps 3.l.ii and 3.l.iii the variable name was inverted resulting in an incorrectly inverted test.
: Normative requirement concerning canonically equivalent strings deleted from paragraph following algorithm because it is
listed as a recommendation in NOTE 2.
: In split algorithm step 11.a and 13.a, the positional order of the arguments to
SplitMatch was corrected to match the actual parameter signature of SplitMatch. In step 13.a.iii.7.d, lengthA replaces
A.length.
: In first paragraph, removed the implication that the individual character property access had “array index”
semantics. Modified algorithm steps 3 and 5 such that they do not enforce “array index” requirement.
: Specified legal value ranges for fields that lacked them. Eliminated “time-only” formats. Specified default
values for all optional fields.
: The step numbers of the algorithm for the internal closure produced by step 2 were incorrectly numbered in a manner that
implied that they were steps of the outer algorithm.
: In the abstract operation IsWordChar the first character in the list in step 3 is “a” rather than
“A”.
: In the algorithm for the closure returned by the abstract operation CharacterSetMatcher, the variable defined by step 3 and
passed as an argument in step 4 was renamed to ch in order to avoid a name conflict with a formal parameter of the
closure.
: Step 9.e was deleted because It performed an extra increment of i.
: Removed requirement that the message own property is set to the empty String
when the message argument is undefined.
: Removed requirement that the message own property is set to the empty String
when the message argument is undefined.
: Steps 6-10 modified/added to correctly deal with missing or empty message
property value.
: Removed requirement that the message own property is set to the empty String
when the message argument is undefined.
: In step 10.b.iii of the JA abstract operation, the last element of the concatenation is
“]”.
B.2.1: Added to NOTE that the encoding is based upon RFC 1738
rather than the newer RFC 3986.
: An item was added corresponding to regarding FutureReservedWords in strict mode.
In Edition 5
Clause references in this list refer to the clause numbers used in Edition 5.
Throughout: In the Edition 3 specification the meaning of phrases such as “as if by the expression new
Array()” are subject to misinterpretation. In the Edition 5 specification text for all internal references and
invocations of standard built-in objects and methods has been clarified by making it explicit that the intent is that the actual
built-in object is to be used rather than the current dynamically resolved value of the correspondingly identifier binding.
11.8.1: ECMAScript generally uses a left to right evaluation order, however the Edition 3
specification language for the > and <= operators resulted in a partial right to left order. The specification has been
corrected for these operators such that it now specifies a full left to right evaluation order. However, this change of order is
potentially observable if side-effects occur during the evaluation process.
: Edition 5 clarifies the fact that a trailing comma at the end of an ArrayInitialiser does not add
to the length of the array. This is not a semantic change from Edition 3 but some implementations may have previously
misinterpreted this.
: Edition 5 reverses the order of steps 2 and 3 of the algorithm. The original order as specified in Editions 1 through 3
was incorrectly specified such that side-effects of evaluating Arguments could affect the result of
evaluating MemberExpression.
12.4: In Edition 3, an object is created, as if by new Object()to serve as
the scope for resolving the name of the exception parameter passed to a catch clause of a try
statement. If the actual exception object is a function and it is called from within the catch clause, the scope
object will be passed as the this value of the call. The body of the function can then define new properties on its
this value and those property names become visible identifiers bindings within the scope of the catch clause after
the function returns. In Edition 5, when an exception parameter is called as a function, undefined is passed as the
this value.
13: In Edition 3, the algorithm for the production FunctionExpression with an Identifier adds an object created as if by new Object() to the scope chain to serve as a scope
for looking up the name of the function. The identifier resolution rules (10.1.4 in Edition 3) when applied to such an object
will, if necessary, follow the object’s prototype chain when attempting to resolve an identifier. This means all the
properties of Object.prototype are visible as identifiers within that scope. In practice most implementations of Edition 3 have
not implemented this semantics. Edition 5 changes the specified semantics by using a Declarative Environment Record to bind the name of the function.
14: In Edition 3, the algorithm for the production SourceElements:SourceElementsSourceElement did not correctly
propagate statement result values in the same manner as Block. This could result in the
eval function producing an incorrect result when evaluating a Program text. In practice
most implementations of Edition 3 have implemented the correct propagation rather than what was specified in Edition 5.
9: In Edition 6, Function calls are not allowed to return a Reference
value.
13.6: In Edition 6, a terminating semi-colon is no longer required at the end of a
do-while statement.
13.6: Prior to Edition 6, an initialisation expression could appear as part of the
VariableDeclaration that precedes the in keyword. The value of that expression was always discarded. In
Edition 6, the ForBind in that same position does not allow the occurance of such an initialiser.
13.14: In Edition 6, it is an early error for a Catch clause to
contained a var declaration for the same Identifier that appears as the Catch clause parameter. In previous editions, such a variable declaration would be instantiated in the
enclosing variable environment but the declaration’s Initialiser value would be assigned to the
Catch parameter.
14.3 In Edition 6, the function objects that are created as the values of the [[Get]]
or [[Set]] attribute of accessor properties in an ObjectLiteral are not constructor functions. In
Edition 5, they were constructors.
19.1.2.2 and 19.1.2.3: In Edition 6, all
property additions and changes are processed, even if one of them throws an exception. If an exception occurs during such
processing, the first such exception is thrown after all propertie are processed. In Edition 5, processing of property
additions and changes immediately terminated when the first exception occurred.
19.1.2.5: In Edition 6, if the argument to Object.freeze is not an object it is treated as if it was a non-extensible ordinary
object with no own properties. In Edition 5, a non-object argument always causes a TypeError to be
thrown.
19.1.2.6: In Edition 6, if the argument to Object.getOwnPropertyDescriptor is not an object an attempt is make to
coerce the argument using ToObject. If the coerecion is successful the result is used in place of
the original argument value. In Edition 5, a non-object argument always causes a TypeError to be
thrown.
19.1.2.7: In Edition 6, if the argument to Object.getOwnPropertyNames is not an object an attempt is make to coerce the
argument using ToObject. If the coerecion is successful the result is used in place of the
original argument value. In Edition 5, a non-object argument always causes a TypeError to be
thrown.
19.1.2.9: In Edition 6, if the argument to Object.getPrototypeOf is not an object an attempt is make to coerce the argument
using ToObject. If the coerecion is successful the result is used in place of the original
argument value. In Edition 5, a non-object argument always causes a TypeError to be thrown.
19.1.2.11: In Edition 6, if the argument to Object.isExtensible is not an object it is treated as if it was a non-extensible
ordinary object with no own properties. In Edition 5, a non-object argument always causes a TypeError to be thrown.
19.1.2.12: In Edition 6, if the argument to Object.isFrozen is not an object it is treated as if it was a non-extensible ordinary
object with no own properties. In Edition 5, a non-object argument always causes a TypeError to be
thrown.
19.1.2.13: In Edition 6, if the argument to Object.isSealed is not an object it is treated as if it was a non-extensible ordinary
object with no own properties. In Edition 5, a non-object argument always causes a TypeError to be
thrown.
19.1.2.14: In Edition 6, if the argument to Object.keys is not an object an attempt is make to coerce the argument using ToObject. If the coerecion is successful the result is used in place of the original argument value.
In Edition 5, a non-object argument always causes a TypeError to be thrown.
19.1.2.15: In Edition 6, if the argument to Object.preventExtensions is not an object it is treated as if it was a
non-extensible ordinary object with no own properties. In Edition 5, a non-object argument always causes a TypeError to be thrown.
19.1.2.17: In Edition 6, if the argument to Object.seal is not an object it is treated as if it was a non-extensible ordinary object
with no own properties. In Edition 5, a non-object argument always causes a TypeError to be
thrown.
19.2.4.1: In Edition 6, the length property of function instances
is configurable. In previous editions it was non-configurable.
19.3.3 In Edition 6, the Boolean prototype object is not a
Boolean instance. In previous editions it was a Boolean instance whose Boolean value was false.
20.1.3 In Edition 6, the Number prototype object is not a
Number instance. In previous editions it was a Number instance whose number value was +0.
20.3.4 In Edition 6, the Date prototype object is not a Date
instance. In previous editions it was a Date instance whose TimeValue was NaN.
22.1.3 In Edition 6, the Array prototype object is not an Array
instance. In previous editions it was an Array instance with a length property whose value was +0.
21.1.3 In Edition 6, the String prototype object is not a
String instance. In previous editions it was a String instance whose String value was the empty string.
21.1.3.22 and 21.1.3.24 In
Edition 6, lowercase/upper conversion processing operates on code points. In previous editions such the conversion processing
was only applied to individual code units. The only affected code points are those in the Deseret block of Unicode
21.1.3.25 In Edition 6, the String.prototype.trim method is defined to recognize white space code points that
may exists outside of the Unicode BMP. However, as of Unicode 6.1 no such code points are defined. In previous editions such
code points would not have been recognized as white space.
21.2.5 In Edition 6, the RegExp prototype object is not a
RegExp instance. In previous editions it was a RegExp instance whose pattern is the empty string.
21.2.5 In Edition 6, source, global,
ignoreCase, and multiline are accessor properties defined on the RegExp prototype object. In
previous editions they were data properties defined on RegExp instances.
22.1.3 In Edition 6, the Array prototype object is not an Array
instance. In previous editions it was an Array instance with a length property whose value was +0.
Clause references in this list refer to the clause numbers used in Edition 5 and 5.1.
7.1: Unicode format control characters are no longer stripped from
ECMAScript source text before processing. In Edition 5, if such a character appears in a StringLiteral
or RegularExpressionLiteral the character will be incorporated into the literal where in Edition 3 the
character would not be incorporated into the literal.
7.2: Unicode character <BOM> is now treated as whitespace and
its presence in the middle of what appears to be an identifier could result in a syntax error which would not have occurred in
Edition 3
7.3: Line terminator characters that are preceded by an escape sequence are now
allowed within a string literal token. In Edition 3 a syntax error would have been produced.
: Regular expression literals now return a unique object each time the literal is evaluated. This change is detectable by
any programs that test the object identity of such literal values or that are sensitive to the shared side effects.
: Edition 5 requires early reporting of any possible RegExp constructor errors that would be produced when converting a
RegularExpressionLiteral to a RegExp object. Prior to Edition 5 implementations were permitted to
defer the reporting of such errors until the actual execution time creation of the object.
: In Edition 5 unescaped “/” characters may appear as a CharacterClass in a regular
expression literal. In Edition 3 such a character would have been interpreted as the final character of the literal.
: In Edition 5, indirect calls to the eval function use the global
environment as both the variable environment and lexical environment for the eval
code. In Edition 3, the variable and lexical environments of the caller of an indirect eval was used as the
environments for the eval code.
: In Edition 5 all methods of Array.prototype are intentionally generic. In Edition 3 toString
and toLocaleString were not generic and would throw a TypeError exception if applied to objects that
were not instances of Array.
: In Edition 5 the array indexed properties of argument objects that correspond to actual formal parameters are enumerable.
In Edition 3, such properties were not enumerable.
: In Edition 5 the value of the [[Class]] internal slot of an
arguments object is "Arguments". In Edition 3, it was "Object". This is observable if
toString is called as a method of an arguments object.
12.6.4: for-in statements no longer throw a TypeError if the
in expression evaluates to null or undefined. Instead, the statement behaves as if the value of the
expression was an object with no enumerable properties.
15: Implementations are now required to ignore extra arguments to standard built-in methods unless otherwise explicitly
specified. In Edition 3 the handling of extra arguments was unspecified and implementations were explicitly allowed to throw a
TypeError exception.
15.1.1: The value properties NaN, Infinity, and
undefined of the Global Object have been changed to be read-only properties.
15.1.2.1. Implementations are no longer permitted to restrict the use of eval in ways that are not a direct call. In
addition, any invocation of eval that is not a direct call uses the global
environment as its variable environment rather than the caller’s variable environment.
: The specification of the function parseInt no longer allows implementations to treat Strings beginning with
a 0 character as octal values.
: In Edition 3, a TypeError is thrown if the second argument passed to Function.prototype.apply is neither an array object nor an arguments object.
In Edition 5, the second argument may be any kind of generic array-like object that has a valid length
property.
, 15.3.3.4: In Edition 3 passing undefined or null as the first argument to either Function.prototype.apply or Function.prototype.call causes the global object to be passed to the indirectly
invoked target function as the this value. If the first argument is a primitive value the result of calling ToObject on the primitive value is passed as the this value. In Edition 5, these
transformations are not performed and the actual first argument value is passed as the this value. This difference will
normally be unobservable to existing ECMAScript Edition 3 code because a corresponding transformation takes place upon
activation of the target function. However, depending upon the implementation, this difference may be observable by host
object functions called using apply or call. In addition, invoking a standard built-in function in
this manner with null or undefined passed as the this value will in many cases cause behaviour in Edition
5 implementations that differ from Edition 3 behaviour. In particular, in Edition 5 built-in functions that are specified to
actually use the passed this value as an object typically throw a TypeError exception if passed null or
undefined as the this value.
: In Edition 5, the prototype property of Function instances is not enumerable. In Edition 3, this property
was enumerable.
: In Edition 5, the individual characters of a String object’s [[StringData]] may be accessed as array indexed
properties of the String object. These properties are non-writable and non-configurable and shadow any inherited properties
with the same names. In Edition 3, these properties did not exist and ECMAScript code could dynamically add and remove
writable properties with such names and could access inherited properties with such names.
: Date.parse is now required to first attempt to parse its argument as an ISO
format string. Programs that use this format but depended upon implementation specific behaviour (including failure) may
behave differently.
: In Edition 5, \s now additionally matches <BOM>.
: In Edition 3, the exact form of the String value of the source property of an object created by the
RegExp constructor is implementation defined. In Edition 5, the String must conform to certain specified
requirements and hence may be different from that produced by an Edition 3 implementation.
: In Edition 3, the result of RegExp.prototype.toString need not
be derived from the value of the RegExp object’s source property. In Edition 5 the result must be derived
from the source property in a specified manner and hence may be different from the result produced by an Edition
3 implementation.
, : In Edition 5, if an initial value for the message property of an Error object is not specified via the
Error constructor the initial value of the property is the empty String. In Edition 3, such an initial value is
implementation defined.
: In Edition 3, the result of Error.prototype.toString is
implementation defined. In Edition 5, the result is fully specified and hence may differ from some Edition 3
implementations.
: In Edition 5, the name JSON is defined in the global
environment. In Edition 3, testing for the presence of that name will show it to be undefined unless it is defined
by the program or implementation.
Produces a list of the Identifiers bound by a production. Does not include Identifiers that are bound within inner environments associated with the production.
Returns a List of the string values of the property names referenced by a production. The list reflects the order of the references in the source text. The list may contain duplicate elements.
, 13.5
PrototypeMethodDefinitions
Return a list of the non-static MethodDefinition productions that are part of a ClassElementList.
13.5
ReferencesSuper
Determine if a MethodDefinition contains any references to the ReservedWordsuper.
13.3
SpecialMethod
Determine if a MethodDefinition defines a generator method or an accessor property.
13.3
StaticMethodDefinitions
Return a list of the static MethodDefinition productions that are part of a ClassElementList.
13.5
SV
Determines the “string value” of a StringLiteral or component of a StringLiteral.
7.8.4
VarDeclaredNames
Returns a list of the local top-level scoped identifiers declared by a production. These are identifier that are scoped as if by a var statement.
[1] IEEE Std 754-2008: IEEE Standard for Floating-Point Arithmetic. Institute of Electrical
and Electronic Engineers, New York (2008)
[2] The Unicode Consortium. The Unicode Standard, Version 3.0, defined by: The Unicode
Standard, Version 3.0 (Reading, MA, Addison-Wesley, 2000. ISBN 0-201-61633-5)
[3] ISO 8601:2004(E) Data elements and interchange formats – Informationinterchange -- Representation of dates and times